





 本文介绍了如何利用TextHero库快速对文本数据进行预处理和可视化,适用于Python环境,对于大数据分析和数据可视化工作流程尤其有用。
本文介绍了如何利用TextHero库快速对文本数据进行预处理和可视化,适用于Python环境,对于大数据分析和数据可视化工作流程尤其有用。
文本数据可视化
自然语言处理 (Natural Language Processing)
When we are working on any NLP project or competition, we spend most of our time on preprocessing the text such as removing digits, punctuations, stopwords, whitespaces, etc and sometimes visualization too. After experimenting TextHero on a couple of NLP datasets I found this library to be extremely useful for preprocessing and visualization. This will save us some time writing custom functions. Aren’t you excited!!? So let’s dive in.
在进行任何NLP项目或竞赛时,我们将大部分时间用于预处理文本,例如删除数字,标点符号,停用词,空白等,有时还会进行可视化处理。 在几个NLP数据集上试验TextHero之后,我发现此库对于预处理和可视化非常有用。 这将节省我们一些编写自定义函数的时间。 你不兴奋!!? 因此,让我们开始吧。
We will apply techniques that we are going to learn in this article to Kaggle’s Spooky Author Identification dataset. You can find the dataset here. The complete code is given at the end of the article.
我们将把本文中要学习的技术应用于Kaggle的Spooky Author Identification数据集。 您可以在此处找到数据集。 完整的代码在文章末尾给出。
Note: TextHero is still in beta. The library may undergo major changes. So some of the code snippets or functionalities below might get changed.
注意:TextHero仍处于测试版。 图书馆可能会发生重大变化。 因此,下面的某些代码段或功能可能会更改。
安装 (Installation)
pip install texthero前处理 (Preprocessing)
As the name itself says clean method is used to clean the text. By default, the clean method applies 7 default pipelines to the text.
顾名思义, clean方法用于清理文本。 默认情况下, clean方法将7个default pipelines应用于文本。
from texthero import preprocessing
df[‘clean_text’] = preprocessing.clean(df[‘text’])fillna(s)fillna(s)lowercase(s)lowercase(s)remove_digits()remove_digits()remove_punctuation()remove_punctuation()remove_diacritics()remove_diacritics()remove_stopwords()remove_stopwords()remove_whitespace()remove_whitespace()
We can confirm the default pipelines used with below code:
我们可以确认以下代码使用的默认管道:

Apart from the above 7 default pipelines, TextHero provides many more pipelines that we can use. See the complete list here with descriptions. These are very useful as we deal with all these during text preprocessing.
除了上述7个默认管道之外, TextHero还提供了更多可以使用的管道。 请参阅此处的完整列表及其说明。 这些非常有用,因为我们在文本预处理期间会处理所有这些问题。
Based on our requirements, we can also have our custom pipelines as shown below. Here in this example, we are using two pipelines. However, we can use as many pipelines as we want.
根据我们的要求,我们还可以具有如下所示的自定义管道。 在此示例中,我们使用两个管道。 但是,我们可以使用任意数量的管道。
from texthero import preprocessing custom_pipeline = [preprocessing.fillna, preprocessing.lowercase] df[‘clean_text’] = preprocessing.clean(df[‘text’], custom_pipeline)自然语言处理 (NLP)
As of now, this NLP functionality provides only named_entity and noun_phrases methods. See the sample code below. Since TextHero is still in beta, I believe, more functionalities will be added later.
到目前为止,此NLP功能仅提供named_entity和noun_phrases方法。 请参见下面的示例代码。 由于TextHero仍处于测试阶段,我相信以后会添加更多功能。
named entity
命名实体
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.named_entities(s)[0])Output:
[('Narendra Damodardas Modi', 'PERSON', 0, 24),
('Indian', 'NORP', 31, 37),
('14th', 'ORDINAL', 64, 68),
('India', 'GPE', 99, 104),
('2014', 'DATE', 111, 115)]noun phrases
名词短语
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.noun_chunks(s)[0])Output:
[(‘Narendra Damodardas Modi’, ‘NP’, 0, 24),
(‘an Indian politician’, ‘NP’, 28, 48),
(‘the 14th and current Prime Minister’, ‘NP’, 60, 95),
(‘India’, ‘NP’, 99, 104)]表示 (Representation)
This functionality is used to map text data into vectors (Term Frequency, TF-IDF), for clustering (kmeans, dbscan, meanshift) and also for dimensionality reduction (PCA, t-SNE, NMF).
此功能用于将文本数据映射到vectors (术语频率,TF-IDF), clustering (kmeans,dbscan,meanshift)以及降dimensionality reduction (PCA,t-SNE,NMF)。
Let’s look at an example with TF-TDF and PCA on the Spooky author identification train dataset.
让我们看一下Spooky作者标识训练数据集中的TF-TDF和PCA的示例。
train['pca'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
.pipe(representation.pca)
)visualization.scatterplot(train, 'pca', color='author', title="Spooky Author identification")
可视化 (Visualization)
This functionality is used to plotting Scatter-plot, word cloud, and also used to get top n words from the text. Refer to the examples below.
此功能用于绘制Scatter-plot ,词云,还用于从文本中获取top n words 。 请参考以下示例。
Scatter-plot example
散点图示例
train['tfidf'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
)train['kmeans_labels'] = (
train['tfidf']
.pipe(representation.kmeans, n_clusters=3)
.astype(str)
)train['pca'] = train['tfidf'].pipe(representation.pca)visualization.scatterplot(train, 'pca', color='kmeans_labels', title="K-means Spooky author")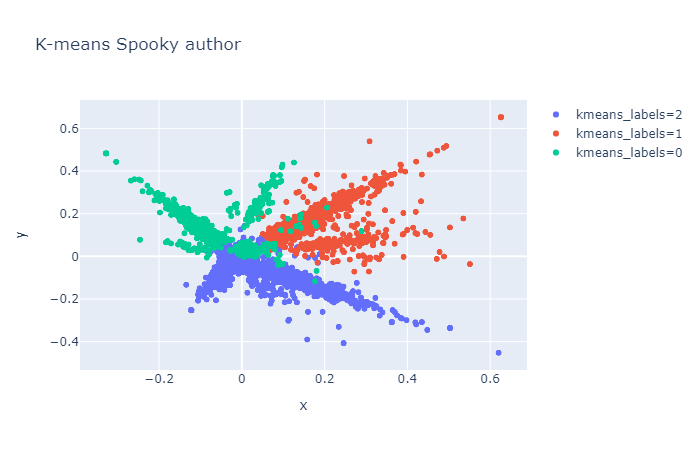
Wordcloud示例 (Wordcloud example)
from texthero import visualization
visualization.wordcloud(train[‘clean_text’])
热门单词示例 (Top words example)
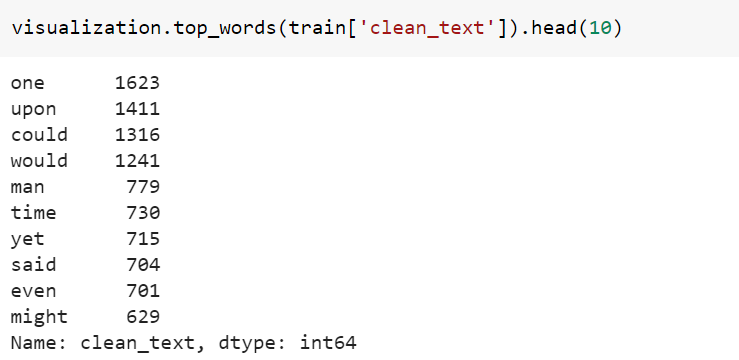
完整的代码 (Complete Code)
结论 (Conclusion)
We have gone thru most of the functionalities provided by TextHero. Except for the NLP functionality, I found that rest of the features are really useful which we can try to use it for the next NLP project.
我们已经通过了TextHero提供的大多数功能。 除了NLP功能以外,我发现其余功能确实有用,我们可以尝试将其用于下一个NLP项目。
Thank you so much for taking out time to read this article. You can reach me at https://www.linkedin.com/in/chetanambi/
非常感谢您抽出宝贵的时间阅读本文。 您可以通过https://www.linkedin.com/in/chetanambi/与我联系
文本数据可视化















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









