





自动化实例(Automation Example)
1.Selenium简介(1. Introduction to Selenium)
Many of you probably have played with web scraping in Python before. There are several Python packages to extract website information based on the webpage (HTML) elements; some examples are BeautifulSoup, Scrapy, and urllib2. These packages often rely on web elements such as XPATH or CSS to extract the data. They each have their pros and cons, but they can handle scraping from many websites without a problem.
你们中的许多人以前可能都曾使用Python进行过网络抓取。 有几个Python程序包可根据网页(HTML)元素提取网站信息。 一些实例是BeautifulSoup , Scrapy和的urllib 2.这些软件包通常依赖于网络元件,诸如XPath或CSS来提取数据。 他们每个人都有自己的优缺点,但是他们可以毫无问题地处理许多网站上的抓取。
However, more and more websites are adopting JavaScript and other methods to make scraping more difficult, or even prevent it entirely. For example, the NYPD Open Data Portal’s “Download” button isn’t displayed until after a user clicks on the “Export” button. Therefore, the regular scraping methods with XPATH or CSS would not work properly, because the web elements are not found until a user clicks on the button. Before you start pulling your hair out, here comes Selenium to your rescue!
但是,越来越多的网站采用JavaScript和其他方法使抓取更加困难,甚至完全阻止抓取。 例如,直到用户单击“导出”按钮后,才会显示NYPD Open Data Portal的“下载”按钮。 因此,使用XPATH或CSS的常规抓取方法将无法正常工作,因为只有在用户单击按钮后才能找到Web元素。 在开始拔头发之前,Selenium可以为您解救!
Traditionally, Selenium is designed to automate testing for web applications. The essence of the package is automating browser behaviors and it is available in many languages such as Java, Python, Ruby, etc. Since Selenium mimics user behaviors, one obvious drawback is the speed. Nevertheless, thanks to the freedom of behaving like a human, Selenium is a powerful tool for web scraping with the fewest limitations when compared with traditional web scraping packages. Let’s dive deeper and see how it works.
传统上,Selenium旨在自动化Web应用程序的测试。 该软件包的本质是使浏览器行为自动化,并且可以在多种语言(例如Java,Python,Ruby等)中使用。由于Selenium模仿用户行为,因此速度上是一个明显的缺点。 尽管如此,由于其行为举止像人类一样自由,所以Selenium是一种功能强大的刮网工具,与传统的刮网程序包相比,它具有最少的限制。 让我们深入研究一下它是如何工作的。
2.设置Selenium Webdriver (2. Set up Selenium Webdriver)
In order to deploy Selenium, you will need to set up the Webdriver for your browser based on your operating system. Here I will use Chrome as an example.
为了部署Selenium,您将需要根据操作系统为浏览器设置Webdriver。 在这里,我将以Chrome为例。
- Step 1: Find your Chrome Version. You can find the version of your Chrome browser at “About Google Chrome” 第1步:找到您的Chrome版本。 您可以在“关于Google Chrome浏览器”中找到Chrome浏览器的版本

Step 2: Download the Webdriver based on your version of Chrome.
步骤2:根据您的Chrome版本下载Webdriver 。
Step 3 for Windows users: You will need to download the Chrome Webdriver based on your system (32 bits or 64 bits) and then place the
chromedriver.exein your PATH.Windows用户的第3步:您需要根据系统(32位或64位)下载Chrome Webdriver,然后将
chromedriver.exe放入PATH中。Step 3 for Mac users: After downloading the Chrome driver for Mac, navigate to this directory
/usr/local/. Then check if thebinfolder exists. If it doesn’t exist, create abinfolder and place the driver in/usr/local/bin. Runcd ~/bin && chmod +x chromedriverto make it executable.适用于Mac用户的第3步:下载适用于Mac的Chrome驱动程序后,导航至该目录
/usr/local/。 然后检查bin文件夹是否存在。 如果不存在,请创建一个bin文件夹,并将驱动程序放在/usr/local/bin。 运行cd ~/bin && chmod +x chromedriver使其可执行。
3.示例:USAC开放数据-电子费率数据 (3. An Example: USAC Open Data — E-Rate Data)
Here are the packages that will be needed in the exercise. Let’s import them!
这是练习中需要的软件包。 让我们导入它们!
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from bs4 import BeautifulSoup
import requests
from urllib.parse import urljoin
import pandas as pd
import timeNow that you have the Chrome Webdriver environment set up, let’s put Selenium into action! In this article I will use the USAC E-Rate Data Portal as an example. Assuming that a user wants to download all the E-rate related datasets, let’s design the user path on this data portal, and then we will try to replicate user actions with Selenium.
现在,您已经设置了Chrome Webdriver环境,现在让我们开始使用Selenium! 在本文中,我将以USAC E-Rate数据门户为例。 假设用户想要下载所有与E-rate相关的数据集,让我们在此数据门户上设计用户路径,然后我们将尝试使用Selenium复制用户操作。
步骤1:收集所有与E-Rate相关的数据集URL (Step 1: Collect all E-Rate related datasets URLs)
We will go to USAC Open Data to search for E-rate datasets. We found that there are only 2 pages from the result page, so we can write the following code to scrape all the URLs related to E-Rate data for Selenium to use later.
我们将前往USAC开放数据搜索E-rate数据集。 我们发现结果页面只有2页,因此我们可以编写以下代码来擦除与E-Rate数据相关的所有URL,以供Selenium稍后使用。
result_links = []
# Get all e-rate URLs from USAC data page
for i in range(2): # 2 is the total number of pages
url = ‘https://opendata.usac.org/browse?category=E-rate&limitTo=datasets&page=' + str(i + 1)
req = requests.get(url)
soup = BeautifulSoup(req.content)
erate_links = lambda tag: (getattr(tag, ‘name’, None) == ‘a’ and
‘href’ in tag.attrs and
‘e-rate’ in tag.get_text().lower())
results = soup.find_all(erate_links)
links = [urljoin(url, tag[‘href’]) for tag in results]
links = [link for link in links if link.startswith(‘https://opendata.usac.org/E-rate’)]
result_links.extend(links)print(‘In total, there are ‘ + str(len(result_links)) + ‘ links retrieved.’)Upon execution, a message will pop up: “In total, there are 15 links retrieved.”
执行后,将弹出一条消息:“总共检索到15个链接。”
步骤2:下载E-Rate数据集并使用数据字典PDF抓取相关元数据 (Step 2: Download E-Rate Dataset and Scrape Related Metadata with Data Dictionary PDFs)
Now that we have all the links for the datasets we want to download, the next step will be to download them. If we are a user, the action chain will be: we will click on the link, then click on the “Export” button, and finally select CSV option for download.
现在我们有了要下载的数据集的所有链接,下一步将是下载它们。 如果我们是用户,则操作链将是:我们将单击链接,然后单击“导出”按钮,最后选择CSV选项进行下载。
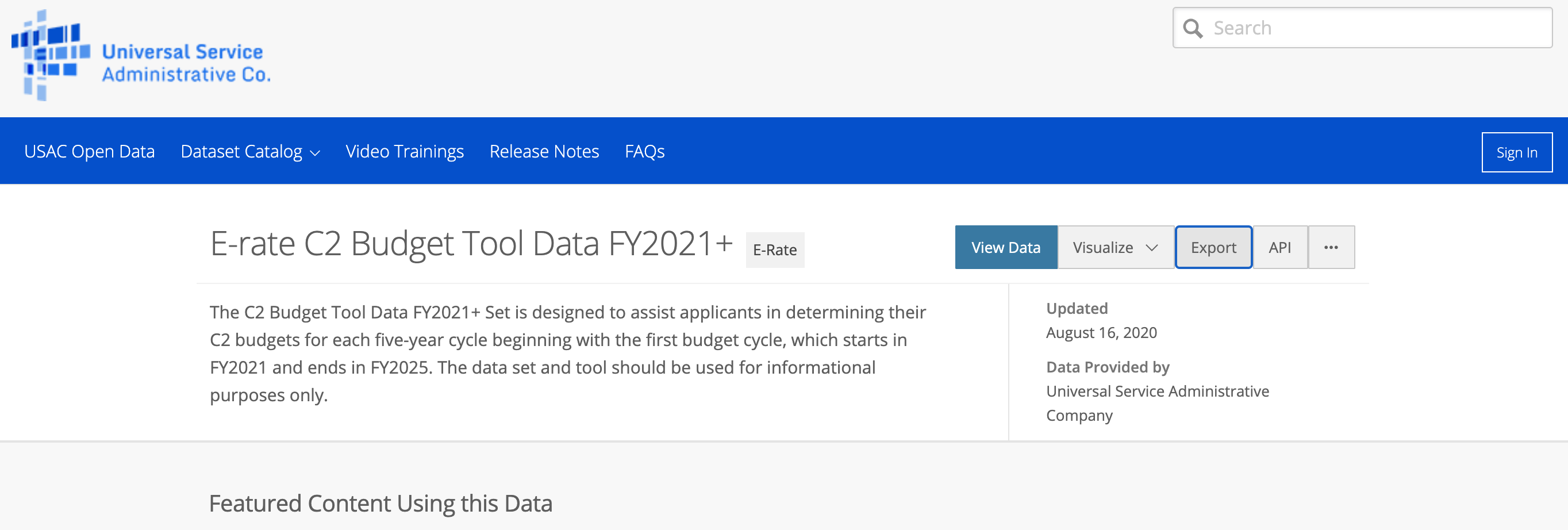
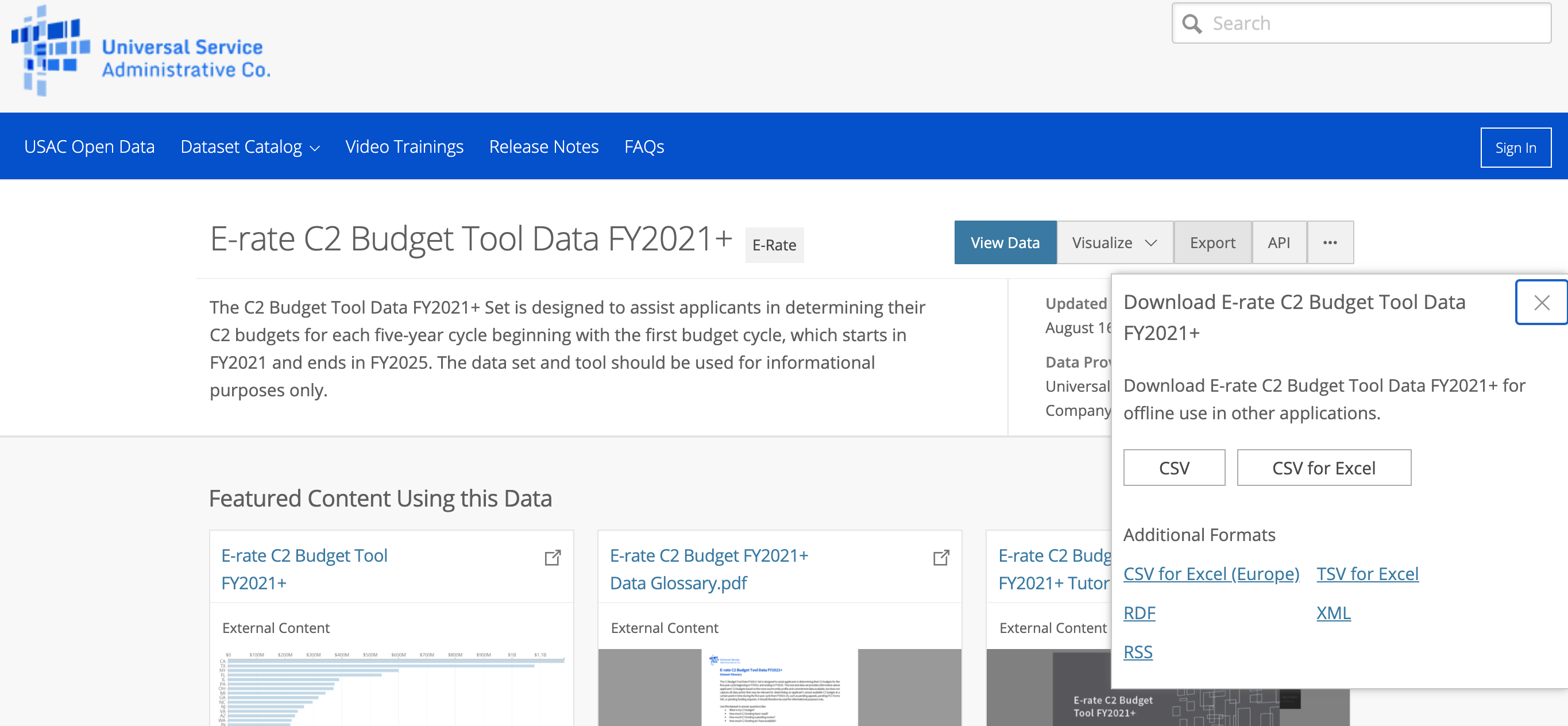
Some additional metadata will also be helpful for the dataset documentation. On the dataset page, there are some key items that we want to get including introduction, update date, contact, email, update frequency, and update url. These metadata can be found in the “About this Dataset” section.
一些其他元数据对于数据集文档也将有所帮助。 在数据集页面上,我们希望获得一些关键项,包括简介,更新日期,联系方式,电子邮件,更新频率和更新URL。 这些元数据可以在“关于此数据集”部分中找到。
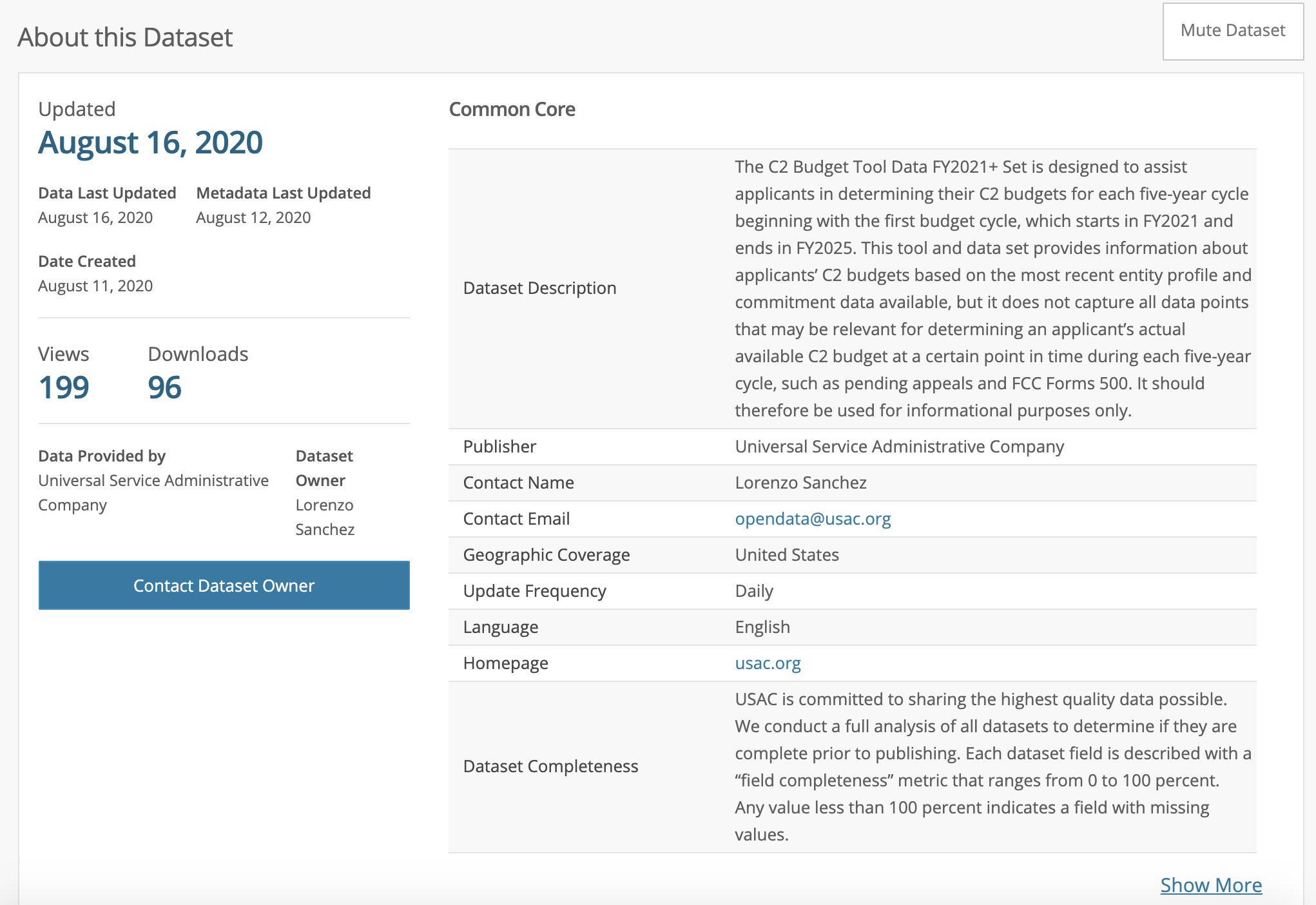
So here is a simple example of how to automate repetitive work and build a data collection with Selenium. Please note that the sleep time is arbitrary. The goal here is to behave like a human, so make sure your action chains make sense and assign an appropriate sleep time.
因此,这是一个简单的示例,说明如何使用Selenium自动执行重复工作并构建数据收集。 请注意,睡眠时间是任意的。 这里的目标是表现得像人一样,因此请确保您的动作链有意义并分配适当的睡眠时间。
# set up driver
driver = webdriver.Chrome()# set up dataframe for metadata
metadata = pd.DataFrame(columns = ['Intro', 'Update Date', 'Contact', 'Email', 'Update Freq', 'URL'])for i in range(len(result_links)):
# extract metadata by XPATH
data_dict = {}
driver.get(result_links[i])
intro = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/div/div[1]/table/tbody/tr[1]/td[2]/span").text
update_date = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/dl/div[1]/div/div[1]/div/dd").text
contact = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/dl/div[3]/div/div[2]/dd").text
email = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/div/div[1]/table/tbody/tr[4]/td[2]/span/a").text
update_freq = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/div/div[1]/table/tbody/tr[6]/td[2]/span").text
# update data_dict with new metadata
data_dict.update({'Intro': intro, 'Update Date': update_date,
'Contact': contact, 'Email': email,
'Update Freq': update_freq, 'URL': result_links[i]})
# update dataframe
metadata = metadata.append(data_dict, ignore_index = True)
time.sleep(5)
action = ActionChains(driver)
# Click Show More
showmore = driver.find_element_by_xpath("//*[@id="app"]/div/div[2]/div[1]/section/div[2]/div/div[5]/a[1]")
action.move_to_element(showmore).perform()
showmore.click()
time.sleep(5)
# Download glossary PDFs
glossary = driver.find_element_by_xpath("//a[contains(@href, '.pdf')]")
glossary[0].click()
time.sleep(5)
# Click Export
action = ActionChains(driver)
exportmenu = driver.find_element_by_xpath("//*[@id="app"]/div/div[1]/div/div/div[1]/div/div[2]/div/div[2]/button")
action.move_to_element(exportmenu).perform()
exportmenu.click()
# Click to download CSV file
downloadmenu = driver.find_element_by_xpath("//*[@id="export-flannel"]/section/ul/li[1]/a")
action.move_to_element(downloadmenu).perform()
downloadmenu.click()As previously mentioned, Selenium is slower than most web scraping packages. Another obvious drawback is that if the owner of the website changed the design, all the XPATHs will need to be updated. But otherwise, it is a very powerful tool and I encourage you to try it out and explore more.
如前所述,Selenium比大多数Web抓取软件包要慢。 另一个明显的缺点是,如果网站的所有者更改了设计,则将需要更新所有XPATH。 否则,它是一个非常强大的工具,我鼓励您尝试一下并进行更多探索。
My next article will be a tutorial about how to use Airflow to schedule Selenium jobs to make it even more powerful. Stay tuned :)
我的下一篇文章将是有关如何使用Airflow安排Selenium作业以使其功能更加强大的教程。 敬请关注 :)
Reference:
参考:
翻译自: https://towardsdatascience.com/selenium-in-action-2fd56ad91be6















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









