





人工智能中的rl是什么意思
From Icarus burning his wings to the Wright brothers soaring through the sky, it took mankind thousands of years to learn how to fly, but how long will it take an AI to do the same?
从伊卡洛斯(Icarus)燃烧的翅膀到赖特兄弟(Wright brothers)在天上飞来飞去,人类花了数千年的时间学习如何飞行,但是人工智能要花多长时间才能做到呢?
介绍 (Introduction)
Hello everyone!
大家好!
Welcome back to this series of articles where I am going to write about my journey into using Artificial Intelligence to make a plane fly (Part 1 is here).
欢迎回到本系列文章,我将在其中撰写有关使用人工智能使飞机飞行的旅程(第1部分在此处 )。
In the previous article, we defined the transition function from a state to another based on the agent’s action.
在上一篇文章中,我们根据代理的操作定义了从状态到另一状态的转换函数 。
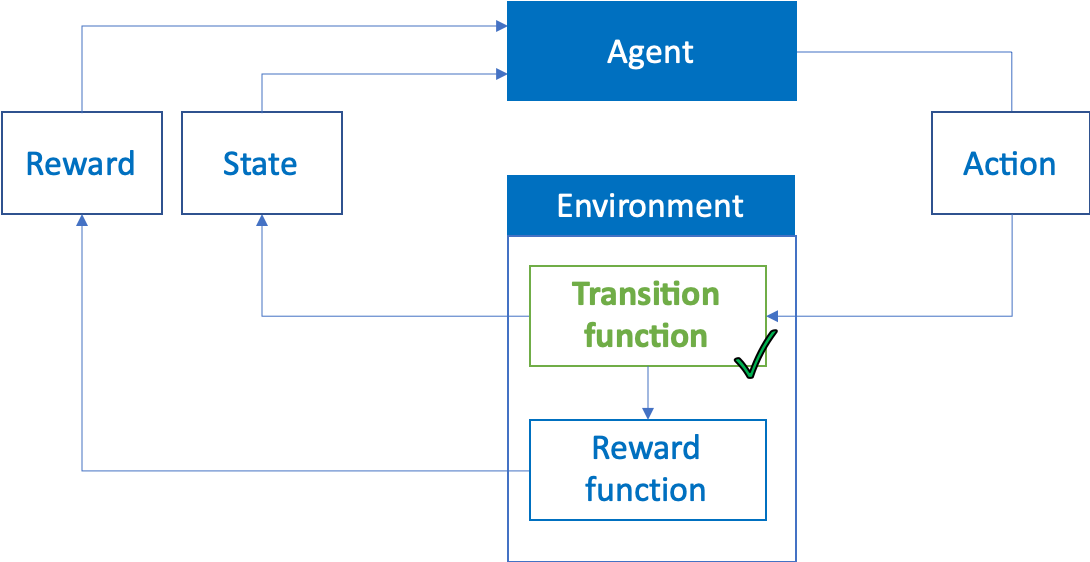
In this article, we will be presenting a complete example of:
在这篇文章中, 我们将展示一个完整的示例 :
how to easily create your custom RL environment using Python/Tensorforce
如何使用Python / Tensorforce 轻松创建自定义RL环境
how to customize, train, and test state of the art agents in your environment.
如何在您的环境中自定义,培训和测试最先进的 代理 。
We will begin with a brief recap of what reinforcement learning is. Then we are going to define our environment (actions, states, rewards) for today’s exercise (the plane will learn to take-off as efficiently as possible). Finally, we will define our agent (The type of agent we will use, hyperparameters optimization, training, and testing).
我们将简要回顾一下强化学习是什么。 然后,我们将为今天的练习定义我们的环境 ( 动作 , 状态 , 奖励 )(飞机将学会尽可能高效地起飞)。 最后,我们将定义代理 (我们将使用的代理类型, 超参数优化, 培训和测试 )。
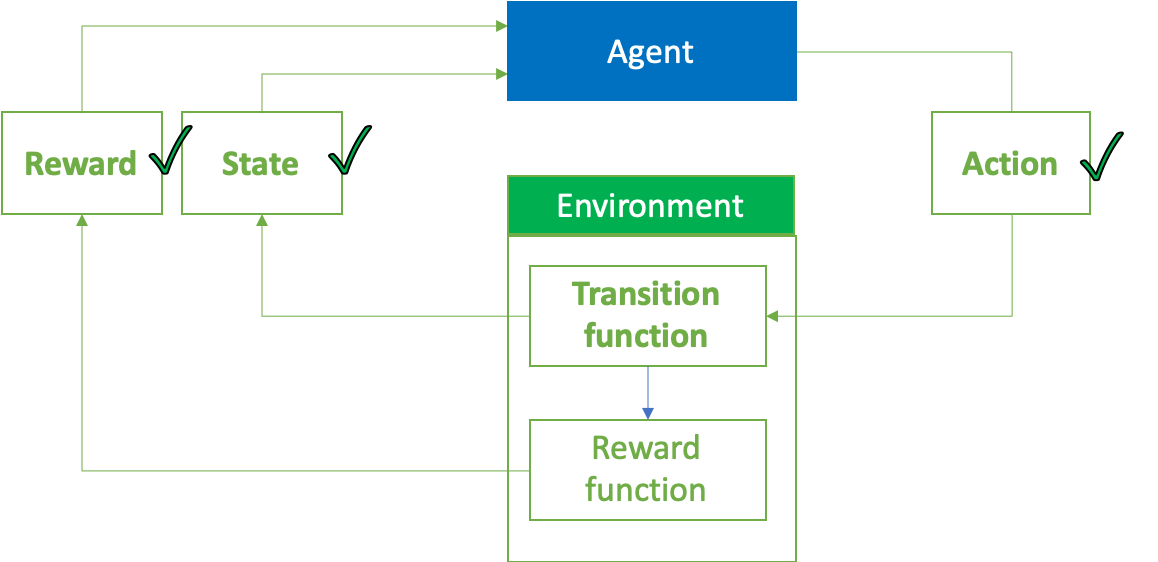
什么是强化学习? (What is Reinforcement Learning?)
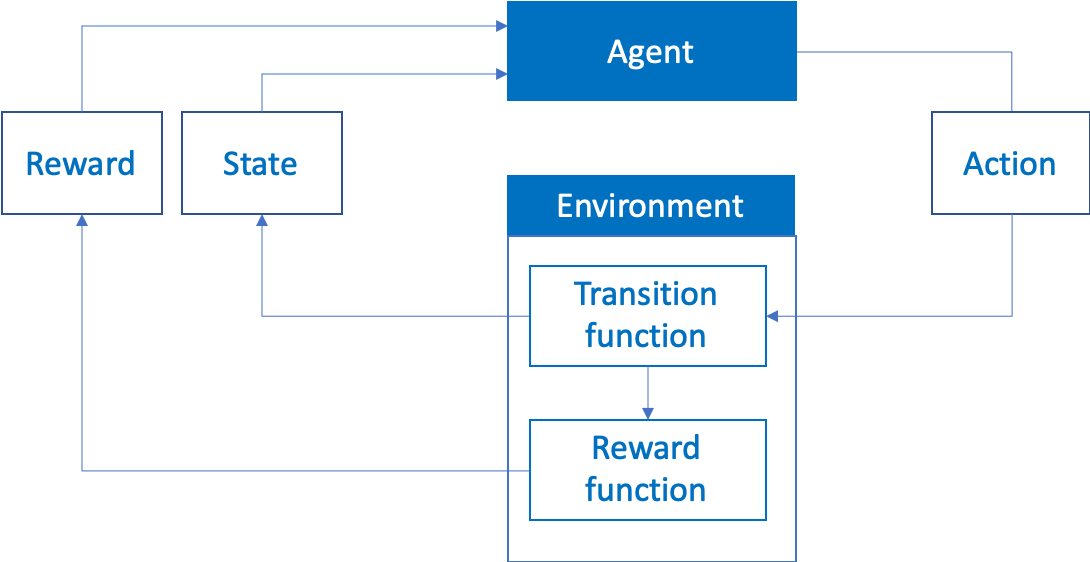
Reinforcement Learning is the branch of Machine Learning that allows training an agent on how to select the best sequence of actions depending on the current state to maximize long term returns. This sequence of actions is called a policy. Reinforcement Learning mimics the real-life process of learning through trial and error.
强化学习是机器学习的一个分支,它使您可以培训坐席如何根据当前状态选择最佳的动作顺序,以最大化长期回报。 这种行动顺序称为政策 。 强化学习通过反复试验模仿现实的学习过程。
The agent starts in a given state, it takes an action and then observes the state of its environment and gets a reward (or punishment) for reaching this state. The goal of Reinforcement Learning is to understand the relation between the actions, states, and rewards in order to find the best sequence of actions to take in any given situation. This fits perfectly our problem as controlling the plane can easily be described as the sequence of actions to take on thrust and pitch allowing for the best trajectories.
代理从给定状态开始,采取行动,然后观察其环境状态,并获得达到此状态的奖励(或惩罚)。 强化学习的目的是了解动作,状态和奖励之间的关系,以便找到在任何给定情况下采取的最佳动作顺序。 这完全符合我们的问题,因为控制飞机可以很容易地描述为采取推力和俯仰动作的顺序,以实现最佳轨迹。
In our example of a virtual plane, the relationship between actions (thrust and pitch) and outcomes (reward and new state) is known since we have designed the physical model to compute them in the previous article. However, it is not known to the agent (otherwise it would become planification and not Reinforcement Learning). Therefore the agent will have to understand how its environment works to select the best actions.
在我们的虚拟平面示例中,动作(推力和俯仰)与结果(奖励和新状态)之间的关系是已知的,因为我们在上一篇文章中设计了物理模型来计算它们。 但是,代理不知道(否则它将变成计划化的,而不是强化学习的)。 因此,代理将必须了解其环境如何选择最佳操作。
环境定义 (Environment definition)
As mentioned earlier we will be using Tensorforce to implement our work. This library allows us to create our custom environments fairly easily with a nice amount of customization. It provides an implementation of state of the art agents which is easily customizable. Tensorforce’s custom environment definition requires the following information (from Tensorforce’s doc):
如前所述,我们将使用Tensorforce实施我们的工作。 该库使我们可以通过大量定制轻松地创建定制环境。 它提供了易于定制的最先进代理的实现。 Tensorforce的自定义环境定义需要以下信息(来自Tensorforce的doc ):
class CustomEnvironment(Environment):
def __init__(self):
super().__init__()
def states(self):
return dict(type='float', shape=(8,))
def actions(self):
return dict(type='int', num_values=4)
# Optional: should only be defined if environment has a natural fixed
# maximum episode length; restrict training timesteps via
# Environment.create(..., max_episode_timesteps=???)
def max_episode_timesteps(self):
return super().max_episode_timesteps()
# Optional additional steps to close environment
def close(self):
super().close()
def reset(self):
state = np.random.random(size=(8,))
return state
def execute(self, actions):
next_state = np.random.random(size=(8,))
terminal = np.random.random() < 0.5
reward = np.random.random()
return next_state, terminal, reward-Init is self-explanatory and initializes the values needed to create the environment (see the doc for more details)
-Init是不言自明的,它会初始化创建环境所需的值(有关更多详细信息,请参阅文档 )
-States defines the shape and type of the state representation. In the example, it is represented by 8 floats (hence it is of 8 continuous dimensions).
-状态定义状态表示的形状和类型。 在示例中,它由8个浮点数表示(因此它具有8个连续尺寸)。
-Actions defines the shape and type of the actions made available to the agent. In the example, the agent has the possibility to pick an action between 1,2,3 and 4 (where each action would then be processed by the environment to create the next step, for example, we could imagine the following relations in a grid world game, 1: Go up, 2: Go down, 3: Go left, 4: Go right).
-动作定义可用于代理的动作的形状和类型。 在该示例中,代理有可能在1,2,3和4之间选择一个动作(然后每个动作将由环境处理以创建下一步,例如,我们可以想象网格中的以下关系)世界游戏:1:上,2:下,3:向左,4:向右)。
-Reset puts the environment back into its starting state in order for a new episode to start. It is thus identical to States.
-Reset使环境回到其初始状态,以便开始新的情节。 因此,它与国家相同。
-Execute processes the action chosen by the agent and collects the new state, the reward, and whether or not the agent reached a terminal state.
-Execute处理代理程序选择的动作,并收集新状态,奖励以及代理程序是否达到终端状态。
环境定制 (Environment Customization)
Let’s now customize our environment! For our first case, we will train CaptAIn (our AI pilot) to learn how to take-off. We will use it as an example to go through all the steps in detail.
现在让我们自定义我们的环境! 对于第一个案例,我们将训练CaptAIn (我们的AI飞行员)学习如何起飞。 我们将以它为例来详细介绍所有步骤。
状态与行动 (States and Actions)
Let’s begin by defining our states and actions.
让我们从定义状态和动作开始。
To be able to learn how to fly, we want CaptAIn to observe the position and velocity (both horizontal and vertical) of its aircraft. We, therefore, want our states spaces to be of 4 dimensions (2 dimensions for the horizontal and vertical position and 2 dimensions for horizontal en vertical velocity).
为了学习如何飞行,我们希望CaptAIn观察其飞机的位置和速度(水平和垂直)。 因此,我们希望状态空间为4维(水平和垂直位置为2维,水平和垂直速度为2维)。
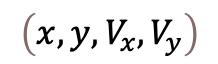
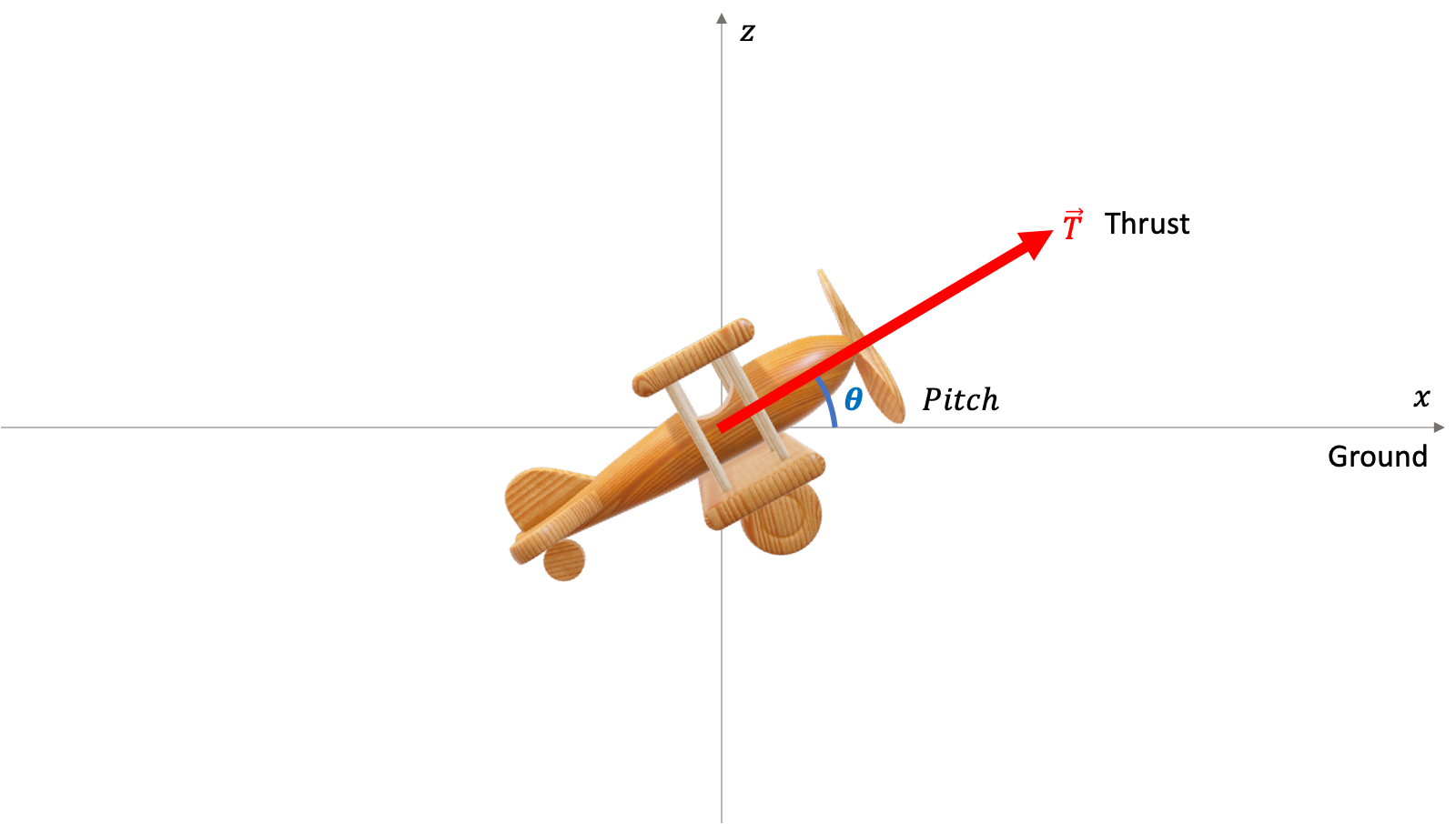
To fly the aircraft, we want our CaptAIn to be able to control the Thrust (or power) and the Pitch (or direction) of the plane. The thrust will be limited from 50% to 100% of the engine’s thrust by 10% increments (50, 60, 70, 80, 90, 100% of maximum power). This will help the training by limiting the power to only values realistically used during flight. The pitch will be limited to realistic positive values (from 0 to 15°).
为了使飞机飞行,我们希望CaptAIn能够控制飞机的推力(或功率)和俯仰(或方向)。 推力将从发动机推力的50%限制到100%,并以10%的增量进行限制(最大功率的50%,60%,70%,80%,90%,100%)。 通过将功率限制为仅在飞行过程中实际使用的值,这将有助于训练。 螺距将限制为实际的正值(从0到15°)。
This leads to the following implementation :
这导致以下实现:
def states(self):
return dict(type="float", shape=(4,))
def actions(self):
return {
"thrust": dict(type="int", num_values=6)
"theta": dict(type="int", num_values=16)
}终端状态 (Terminal State)
Let’s now investigate the terminal state. We will define 3 ways for an episode to end:
现在让我们研究终端状态。 我们将定义3种结束情节的方式:
- The plane reaches an altitude of 25m (this is our definition of take-off). 飞机到达25m的高度(这是我们对起飞的定义)。
- The plane runs off the runway (>5km) without taking-off 飞机不起飞就跑出跑道(> 5km)
- The episode lasts more than 100s. 情节持续超过100秒。
def max_episode_timesteps(self):
return 100
def terminal(self):
self.finished = self.FlightModel.Pos[1] > 25 # The Agent suceeded
self.episode_end = (self.FlightModel.timestep > self.max_step_per_episode) or (
self.FlightModel.Pos[0] > 5000 # The Agent did not suceed (runs of the runway or takes too much time)
)
return self.finished or self.episode_endself.FlightModel.Pos[1] is the vertical position of the plane above the runway and self.FlightModel.Pos[0] its horizontal position from the start of the runway.
self.FlightModel.Pos [1]是飞机在跑道上方的垂直位置, self.FlightModel.Pos [0]是飞机从跑道起点开始的水平位置。
奖赏 (Rewards)
The next step is the rewards definition. They need to be designed to encourage the agent to perform our task, it needs to be encountered sufficiently frequently for the agent to learn quickly while being sufficiently precise for the agent to learn only the behavior we seek. We want our CaptAIn to take-off as quickly as possible, therefore we want to encourage the shortest take-off distance or the shortest take-off time (the two are directly related).
下一步是奖励的定义。 他们需要设计为鼓励代理执行我们的任务,需要足够频繁地遇到它,以便代理快速学习,同时又要足够精确以使代理仅学习我们寻求的行为。 我们希望CaptAIn尽快起飞,因此我们希望鼓励最短的起飞距离或最短的起飞时间(两者直接相关)。
To achieve this we will be penalizing the agent for every time step it takes to reach the objective. We can think of it as withdrawing 1 dollar from the CaptAIn’s bank account for every second it takes to take-off. We will also reward him if it reaches its goal (reaching an altitude of 25m), the amount will be based on how much runway there was left when it took-off. We can think of it as roughly giving him 1 dollar per meter of runway left in order to motivate him to use the least runway possible while also rewarding him for successfully taking-off.
为了实现这一目标,我们将对达到目标的每个步骤对代理进行惩罚。 我们可以认为这是从CaptAIn的银行帐户中每起飞一秒钟提取1美元。 如果到达目标(到达25m的高度),我们也将给予奖励,金额将取决于起飞时还剩下多少跑道。 我们可以认为这大致是给他每米跑道1美元,以激励他使用尽可能少的跑道,同时也奖励他成功起飞。
def reward(self):
if self.finished:
reward = np.log(((5000 - self.FlightModel.Pos[0]) ** 2)) #if sucessfull reward based on how much runway is left (5000 being the length of the runway).
else:
reward = -1 #else, if unsucessful, give a small punition.
return reward执行 (Execute)
Last but not least we will use the transition function defined in the previous article to compute the next state and reward based on the current state and action (execute the agent’s actions).
最后但并非最不重要的一点是,我们将使用上一篇文章中定义的转换函数来计算下一个状态,并根据当前状态和操作(执行代理的操作)进行奖励。
def execute(self, actions):
next_state = self.FlightModel.compute_timestep(actions) #defined in our AirplaneModel, see below
terminal = self.terminal() #defined earlier
reward = self.reward() #defined earlier
return next_state, terminal, rewardThe transition function (compute_timestep) is defined in our airplane environment and goes as follows:
转换函数( compute_timestep )在我们的飞机环境中定义,其运行方式如下:
#Extract from the airplane model.
def compute_timestep(self, action): #our transition function
"""
Compute the dynamics of the the plane over a given number of episodes based on thrust and theta values
Variables : Thrust in N, theta in degrees, number of episodes (no unit)
This will be used by the RL environment.
"""
thrust_factor = (action["thrust"]+5)/10 #maps the action to the thrust percentage from 50% to 100%
self.theta = np.radians(action["theta"]) #convert the pitch angle to radians
self.timestep += 1 #increment timestep
self.fuel_consumption() #apply the fuel consumption
thrust_modified = thrust_factor * self.altitude_factor() * self.THRUST_MAX # Apply the altitude factor to the thrust
# Compute the dynamics for the episode
self.compute_dyna(thrust_modified)
self.obs = [
floor(self.Pos[0]),
floor(self.Pos[1]),
floor(self.V[0]),
floor(self.V[1]),
]
return self.obs #returns the next stateFor your custom environment, you would have to provide your own transition function. Now that the environment is defined, let’s move on to the Agent definition!
对于您的自定义环境,您将必须提供自己的过渡功能。 现在已经定义了环境,让我们继续进行代理定义!
代理商定义 (Agent Definition)
Our CaptAIn needs to be able to understand a complex relation (our Transition function, which is unknown to him) between continuous states (position and velocity) and discrete actions (thrust and pitch) in order to maximize its long-term rewards.
我们的CaptAIn需要能够理解连续状态(位置和速度)与离散动作(推力和俯仰)之间的复杂关系(我们不知道的过渡函数),以便最大化其长期回报。
Tensorforce has multiple agents (Deep Q-network, Dueling QDN, Actor-Critic, PPO …) already implemented so we don’t have to do it ourselves.
Tensorforce已实施了多个代理(深度Q网络,对决QDN,Actor-Critic,PPO…),因此我们不必自己做。
In order not to overload this article we won’t go in detail into the agent selection nor how they work. After trying out the different agents it was clear that the most fitted for our task was the PPO (Proximal Policy Optimization) algorithm. For more details on how it works please refer to this article. The specificities and advantages between each of them could be the subject of an entire article but we will stay focused on implementation today.
为了不使本文过多,我们将不详细介绍代理的选择及其工作方式。 在尝试了不同的代理之后,很明显,最适合我们任务的是PPO(近端策略优化)算法。 有关它的工作原理请参见更多细节此文章。 它们之间的特殊性和优点可能是整篇文章的主题,但今天我们将继续专注于实现。
代理实施 (Agent implementation)
Here is a basic implementation of the PPO agent taken from the Tensorforce documentation. We will go over the hyperparameters in a following part and stick with the default values for the moment.
这是来自Tensorforce文档的PPO代理的基本实现。 我们将在下一部分中遍历超参数,并暂时保留默认值。
agent = Agent.create(
agent='ppo', environment=environment,
# Automatically configured network
network='auto',
# Optimization
batch_size=10, update_frequency=2, learning_rate=1e-3, subsampling_fraction=0.2,
optimization_steps=5,
# Reward estimation
likelihood_ratio_clipping=0.2, discount=0.99, estimate_terminal=False,
# Critic
critic_network='auto',
critic_optimizer=dict(optimizer='adam', multi_step=10, learning_rate=1e-3),
# Preprocessing
preprocessing=None,
# Exploration
exploration=0.0, variable_noise=0.0,
# Regularization
l2_regularization=0.0, entropy_regularization=0.0,
# TensorFlow etc
name='agent', device=None, parallel_interactions=1, seed=None, execution=None, saver=None,
summarizer=None, recorder=None
)With the agent operational, we have completed the whole framework.
随着代理的运营,我们已经完成了整个框架。
培训与测试 (Training and testing)
Now that the environment and the agent are good to go, fasten your seatbelt and get ready for take-off!
现在环境和代理商都可以使用,系好安全带并准备起飞!
Let’s take a look at the basic code to initialize our environment and train and test the agent.
让我们看一下用于初始化环境以及训练和测试代理的基本代码。
def run(environment, agent, n_episodes, max_step_per_episode, test=False):
"""
Train agent for n_episodes
"""
environment.FlightModel.max_step_per_episode = max_step_per_episode
# Loop over episodes
for i in range(n_episodes):
# Initialize episode
episode_length = 0
states = environment.reset()
internals = agent.initial_internals()
terminal = False
while not terminal:
# Run episode
episode_length += 1
actions = agent.act(states=states)
states, terminal, reward = environment.execute(actions=actions)
agent.observe(terminal=terminal, reward=reward)This function takes the environment we defined earlier as well as our agent and runs it for the given number of episodes. There are two modes, training mode (where exploration is allowed), used for training the agent over a large number of episodes; and test mode (where exploration is not allowed) used to evaluate the agent’s performance.
此功能采用我们之前定义的环境以及我们的代理,并针对给定的情节数运行它。 有两种模式,训练模式(允许探索),用于训练大量情节中的特工。 和测试模式(不允许进行探索)用于评估代理的性能。
The run function will be called by the runner function in order to execute episodes into batches to monitor the results during training by performing a test run after each batch and gather the results.
运行函数将由跑步函数调用,以便将批次执行为几集,以通过在每个批次之后执行测试运行并收集结果来监视训练期间的结果。
def runner(
environment,
agent,
max_step_per_episode,
n_episodes,
n_episodes_test=1,
combination=1,
):
# Train agent
result_vec = [] #initialize the result list
for i in range(round(n_episodes / 100)): #Divide the number of episodes into batches of 100 episodes
if result_vec:
print("batch", i, "Best result", result_vec[-1]) #Show the results for the current batch
# Train Agent for 100 episode
run(environment, agent, 100, max_step_per_episode, combination=combination)
# Test Agent for this batch
test_results = run(
environment,
agent,
n_episodes_test,
max_step_per_episode,
combination=combination,
test=True
)
# Append the results for this batch
result_vec.append(test_results)
# Plot the evolution of the agent over the batches
plot_multiple(
Series=[result_vec],
labels = ["Reward"],
xlabel = "episodes",
ylabel = "Reward",
title = "Reward vs episodes",
save_fig=True,
path="env",
folder=str(combination),
time=False,
)
#Terminate the agent and the environment
agent.close()
environment.close()And here is the main script which controls those functions.
这是控制这些功能的主要脚本。
from env.FlightModel import FlightModel
from env.FlightEnv import PlaneEnvironment
from utils import runner
# Instantiate our Flight Model
FlightModel = FlightModel()
# Instantiane our environment
environment = PlaneEnvironment()
# Instantiate a Tensorforce agent
agent = Agent.create(agent="ppo",environment=environment)
# Call runner
runner(
environment,
agent,
max_step_per_episode=1000,
n_episodes=10000)Let’s take a look at the results of this basic script:
让我们看一下这个基本脚本的结果:
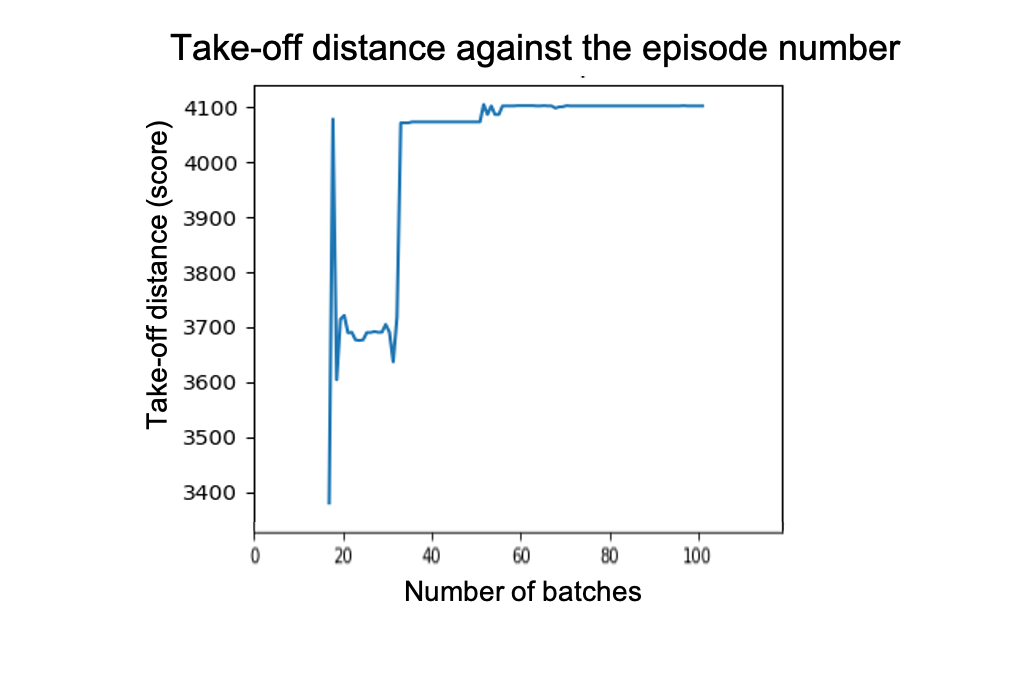
The results are not very impressive. Not only does the agent gets worse over time by needing more runway to take-off, but the best take-off distance is also far from the real-life results of about 1.7km.
结果不是很令人印象深刻。 随着时间的推移,代理商不仅需要更长的跑道来使情况变得更糟,而且最佳的起飞距离也离实际结果约1.7公里远。
超参数调整 (Hyperparameters tuning)
In order to improve our results, let’s take a look at our agent’s main hyperparameters (for a deeper understanding of those hyperparameters, please read this article and the original paper on PPO):
为了改善我们的结果,让我们看一下代理的主要超参数(要更深入地了解这些超参数,请阅读本文和有关PPO的原始文章 ):
- Discount: This parameter describes how much the agent will look into the future instead of only looking over the next few actions for reward anticipation. 折扣:此参数描述了代理商对未来的展望,而不是仅查看接下来的一些行动以期望获得奖励。
- Exploration: This parameter is the probability that a random action will be taken instead of the action decided by the agent’s policy, as the name implies this allows the agent to try actions it would not normally go for. 探索:此参数是将采取随机操作而不是由代理策略决定的操作的概率,顾名思义,该参数允许代理尝试通常不会执行的操作。
- Subsampling fraction: This is the relative fraction of batch timesteps to subsample (in order to reduce the volume of data used) 二次抽样分数:这是批次时间步与二次抽样的相对分数(以减少使用的数据量)
- Entropy regularization: This parameter helps the policy not to be “too certain” and freeze right at the beginning. 熵正则化:此参数有助于策略不要“太确定”并在一开始就冻结。
- L2 regularization: This is the amount of random noise to add to the loss in order for the agent not to overfit. L2正则化:这是为了使代理不过度拟合而增加到损耗中的随机噪声量。
- Likelihood ratio clipping: This parameter defines how much the surrogate objective used in PPO will be clipped to keep the change in policy into a safe range. 似然比限制:此参数定义将限制PPO中使用的替代目标以将策略更改保持在安全范围内。
In order to find the best values for these parameters we will be running a series of episodes for different values of them and observe the best combination by using the take-off distance as a score. The script we are going to use for this is basically a grid-search. We will directly freeze the other hyperparameters to their default values or to arbitrary values which we won’t try to optimize in this example.
为了找到这些参数的最佳值,我们将针对它们的不同值运行一系列情节,并以起飞距离为分数来观察最佳组合。 我们将用于此的脚本基本上是网格搜索。 我们将直接将其他超参数冻结为它们的默认值或任意值,在本示例中我们将不尝试对其进行优化。
def GridSearchTensorForce(
environment, param_grid_list, max_step_per_episode, n_episodes
):
#compute the different parameters combination
lists = param_grid_list.values()
param_combinations = list(itertools.product(*lists))
total_param_combinations = len(param_combinations)
print("Number of combinations", total_param_combinations)
# Initialize lists to gather the results over the different combinations
scores = []
names = []
scores_vec = {}
# Loop over the different parameters combination
for i, params in enumerate(param_combinations, 1):
print("Combination", i, "/", total_param_combinations)
# Fill the parameters dictionnary with the current parameters combination
param_grid = {}
for param_index, param_name in enumerate(param_grid_list):
param_grid[param_name] = params[param_index]
# Create the agent with the current parameters combination
agent = Agent.create(
agent="ppo",
environment=environment,
# Automatically configured network
network=dict(
type=param_grid["network"],
size=param_grid["size"],
depth=param_grid["depth"],
),
# Optimization
batch_size=param_grid["batch_size"],
update_frequency=param_grid["update_frequency"],
learning_rate=param_grid["learning_rate"],
subsampling_fraction=param_grid["subsampling_fraction"],
optimization_steps=param_grid["optimization_steps"],
# Reward estimation
likelihood_ratio_clipping=param_grid["likelihood_ratio_clipping"],
discount=param_grid["discount"],
estimate_terminal=param_grid["estimate_terminal"],
# Critic
critic_network="auto",
critic_optimizer=dict(
optimizer="adam",
multi_step=param_grid["multi_step"],
learning_rate=param_grid["learning_rate_critic"],
),
# Preprocessing
preprocessing=None,
# Exploration
exploration=param_grid["exploration"],
variable_noise=param_grid["variable_noise"],
# Regularization
l2_regularization=param_grid["l2_regularization"],
entropy_regularization=param_grid["entropy_regularization"],
# TensorFlow etc
name="agent_" + str(i),
device=None,
parallel_interactions=1,
seed=124,
execution=None,
# Save the agents training every 1000 episodes
recorder=dict(directory=directory, frequency=1000),
summarizer=None,
# Save the network
saver=dict(directory=directory, filename="agent_" + str(i)),
)
# Load the Agent from a previous save if needed
# agent = Agent.load(directory="data/checkpoints")
# Create a folder for the i-th parameter combination if it doesn't exist
try:
os.mkdir(os.path.join("env", "Graphs", str(i)))
except:
pass
# Run the agent with the i-th parameters combination and get its results
pos, results_vec = runner(
environment, agent, max_step_per_episode, n_episodes, combination=i
)
# Append the i-th parameters combinations results to the scores.
scores.append(pos)
scores_vec[i] = results_vec
names.append(str(param_grid))
# Create a dictionnary of hyperparameters and their results
dict_scores = dict(zip(names, scores))
best_model = min(dict_scores, key=dict_scores.get)
# Show the best hyperparameters combination and their result
print("best model", best_model, "best model number", np.argmin(scores))
print("best model score", dict_scores[best_model])We then use this function to iterate over a range of hyperparameters and compute the best combination. Each combination will be run over the span of 100 batches of 100 episodes.
然后,我们使用此函数遍历一系列超参数并计算最佳组合。 每个组合将在100个批次的100个批次中运行。
from env.FlightModel import FlightModel
from env.FlightEnv import PlaneEnvironment
from utils import gridsearch_tensorforce
# Instantiate our Flight Model
FlightModel = FlightModel()
# Instantiane our environment
environment = PlaneEnvironment()
# Initiate a parameters range dictionnary
param_grid_list = {}
# Set the ranges for the desired agent
param_grid_list["PPO"] = {
"batch_size": [10],
"update_frequency": [20],
"learning_rate": [1e-3],
"subsampling_fraction": [0.1, 0.2, 0.3],
"optimization_steps": [100],
"likelihood_ratio_clipping": [0.1, 0.2, 0.3],
"discount": [0.99],
"estimate_terminal": [False],
"multi_step": [30],
"learning_rate_critic": [1e-3],
"exploration": [0.01],
"variable_noise": [0.0],
"l2_regularization": [0.1, 0.01, 0.001],
"entropy_regularization": [0.1, 0.01, 0.001],
"network": ["auto"],
"size": [32, 64, 128],
"depth": [2, 4, 6 , 8],
}
gridsearch_tensorforce(
environment, param_grid_list["PPO"], max_step_per_episode = 1000, n_episodes = 10000
)Let’s begin by examining the non-network parameters results (subsampling fraction, likelihood ratio clipping, l2 regularization, entropy regularization).
让我们开始检查非网络参数的结果(二次采样分数,似然比限幅,l2正则化,熵正则化)。
The following graphs represent the mean of the take-off distances amongst all configurations with the same value of a given parameter (e.g. in the first graph the blue curve represents the mean take-off distance for all episodes where the subsampling fraction was of 0.2). We can see the evolution of this distance as the agent learns over episodes with the same parameters. The colored area around the curves represents standard deviation.
下图表示给定参数值相同的所有配置之间的起飞距离平均值(例如,在第一张图中,蓝色曲线表示二次采样分数为0.2的所有情节的平均起飞距离) 。 当代理人学习具有相同参数的情节时,我们可以看到此距离的演变。 曲线周围的彩色区域代表标准偏差。
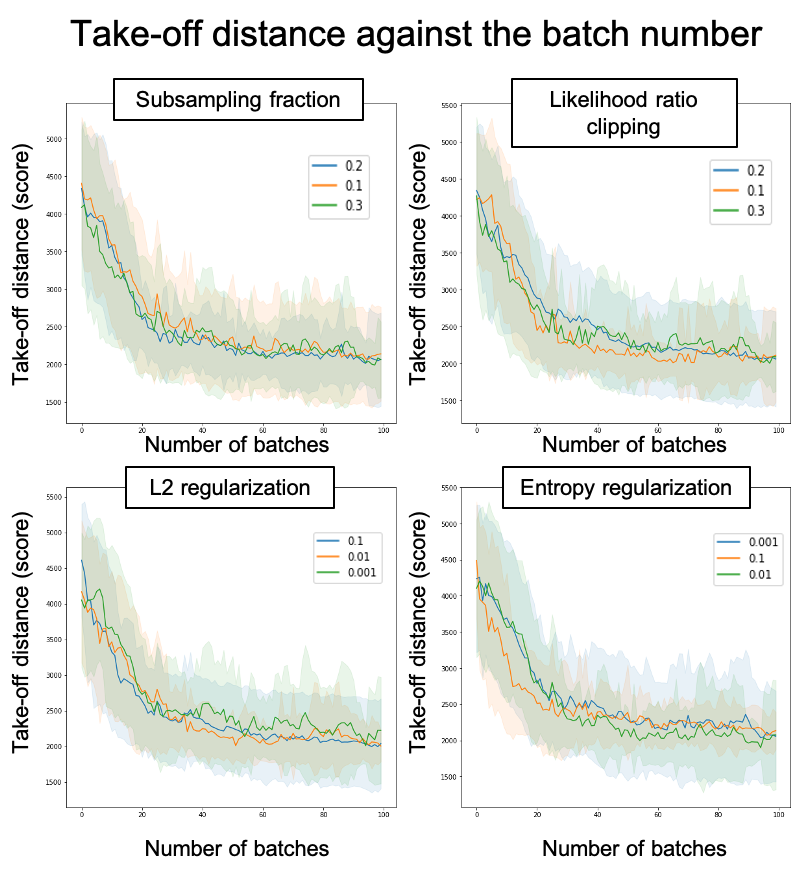
From these graphs we can get the best values for the studied parameters while also observing that they don’t have a very important impact on the results:
从这些图中,我们可以获得研究参数的最佳值,同时还观察到它们对结果的影响不是很重要:
- Subsampling fraction : 0.3 二次取样分数:0.3
- Likelihood ratio clipping : 0.1 可能性比限幅:0.1
- l2 regularization : 0.1 l2正则化:0.1
- Entropy regularization : 0.01 熵正则化:0.01
We then do the same for the network parameters (size of each layer, and depth of the neural network)
然后,我们对网络参数(每层的大小和神经网络的深度)执行相同的操作
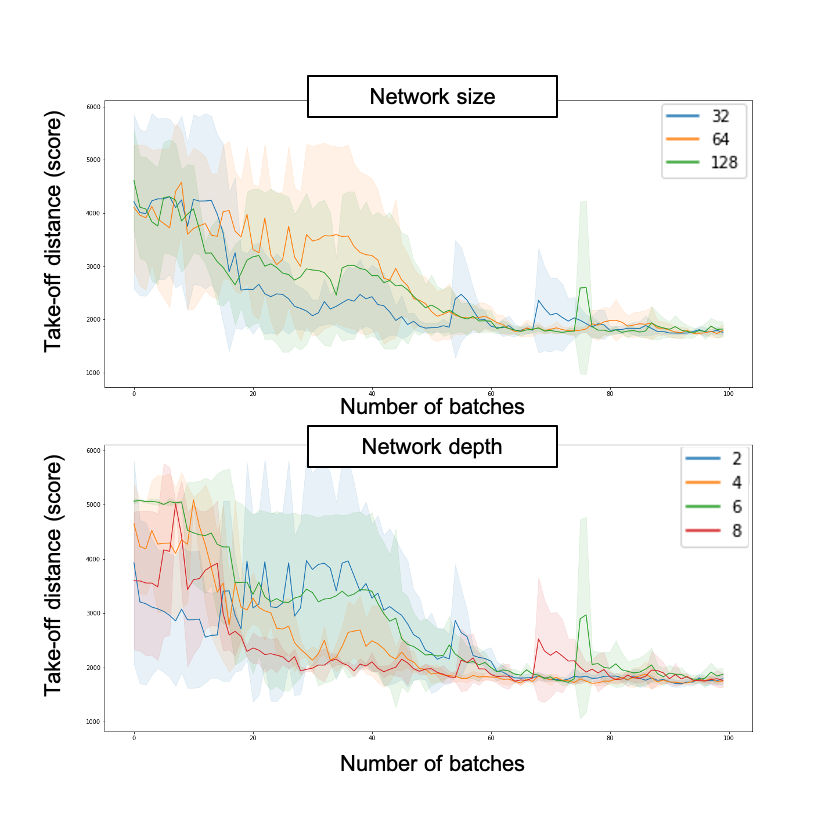
The best network parameters are :
最佳网络参数是:
- Size: 32 (better accuracy could be achieved using 64 however 32 allows for similar results and a better computing efficiency) 大小:32(使用64可以实现更高的精度,但是32可以实现类似的结果并具有更好的计算效率)
- Depth: 4 (again, not the absolute best results but the best mean results and a good computing efficiency) 深度:4(同样,不是绝对的最佳结果,而是最佳的平均结果和良好的计算效率)
Let’s now take a look at the last two parameters, discount, and exploration :
现在,让我们看一下最后两个参数,折扣和探索:
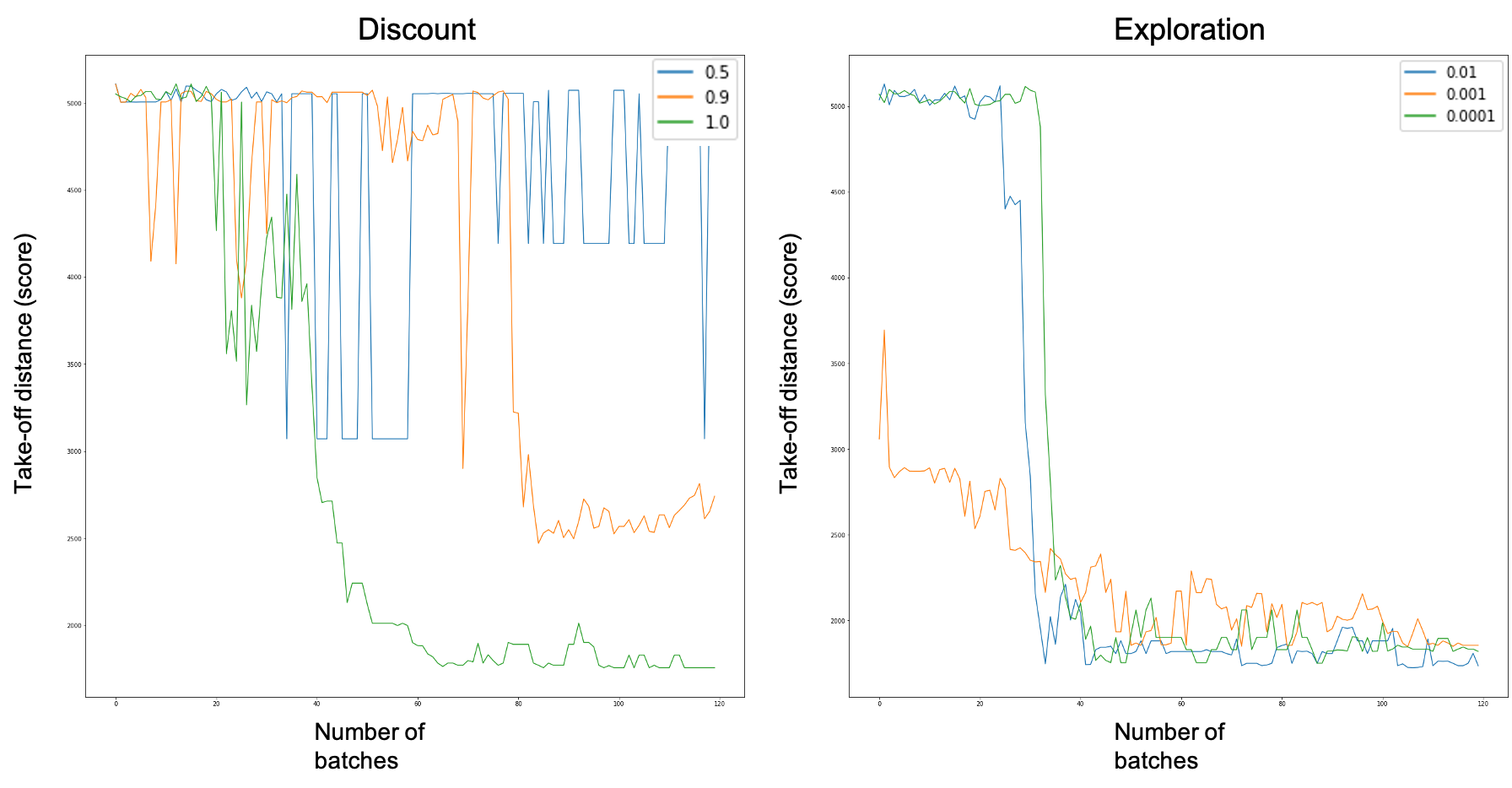
For the discount factor, we can see that for the value of 0.5, it does not really improve over the span of the study, for the 0.9 discount it does reach a plateau of around 2000m take-off distance; and finally, the 1.0 discount reaches a plateau of 1700m while also taking less time to converge than the 0.9 discount factor (around 50 episodes rather than around 80). We will thus select the 1.0 discount factor.
对于折现系数,我们可以看到,对于0.5的值,在整个研究范围内并没有真正改善,对于0.9折现,它确实达到了约2000m起飞距离的平台; 最后,1.0折让达到了1700m的稳定水平,同时收敛所需的时间也比0.9折让要少(大约50集,而不是80集)。 因此,我们将选择1.0折扣系数。
For the exploration factor, the results are more tied and all 3 factors (1%, 0.1%, and 0.01%) all seem to do quite well in the end (even though 0.1% seems to converge more slowly). However the 1% exploration factor seems to be the best at the end of the study, we will thus select this value.
对于探索因子,结果更加紧密,所有三个因子(1%,0.1%和0.01%)最终似乎都做得很好(尽管0.1%似乎收敛较慢)。 但是,在研究结束时1%的勘探因子似乎是最好的,因此我们将选择此值。
结果 (Results)
Using the fixed hyperparameters, the environment we defined, and the agent we trained we can now observe how CaptAIn is doing.
使用固定的超参数,我们定义的环境以及我们训练的代理,我们现在可以观察CaptAIn的工作方式。
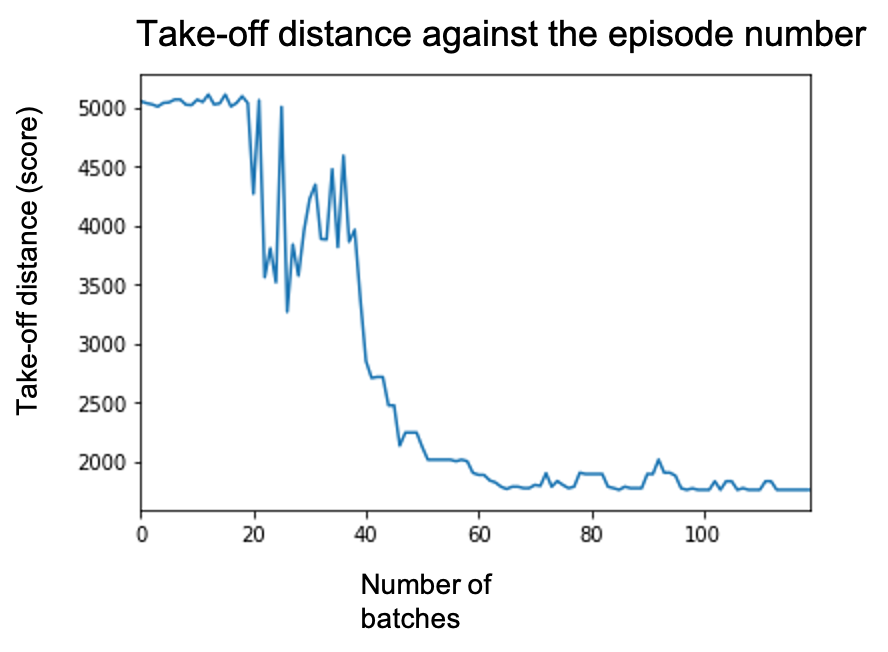
On this graph, we can see the take-off distance achieved after each batch for a hundred batch of a hundred episodes each. We can see the take-off distance is decreasing overall with some periodic degradation due to exploration. The final take-off distance achieved is of 1725 meters.
在此图上,我们可以看到每一批一百集一百集后的起飞距离。 我们可以看到,由于探索,起飞距离总体上在减小,并伴有周期性的下降。 最终的起飞距离为1725米。
This value is comparable to the ones achieved by actual A320 (the plane we are modeling) therefore the results are encouraging! Let’s now take a look at how the agent does it, a.k.a its policy. We start by taking a look at the training phase :
该值与实际A320(我们正在建模的飞机)所达到的值相当,因此结果令人鼓舞! 现在让我们看一下代理如何执行它,也就是它的策略 。 我们首先看一下培训阶段:
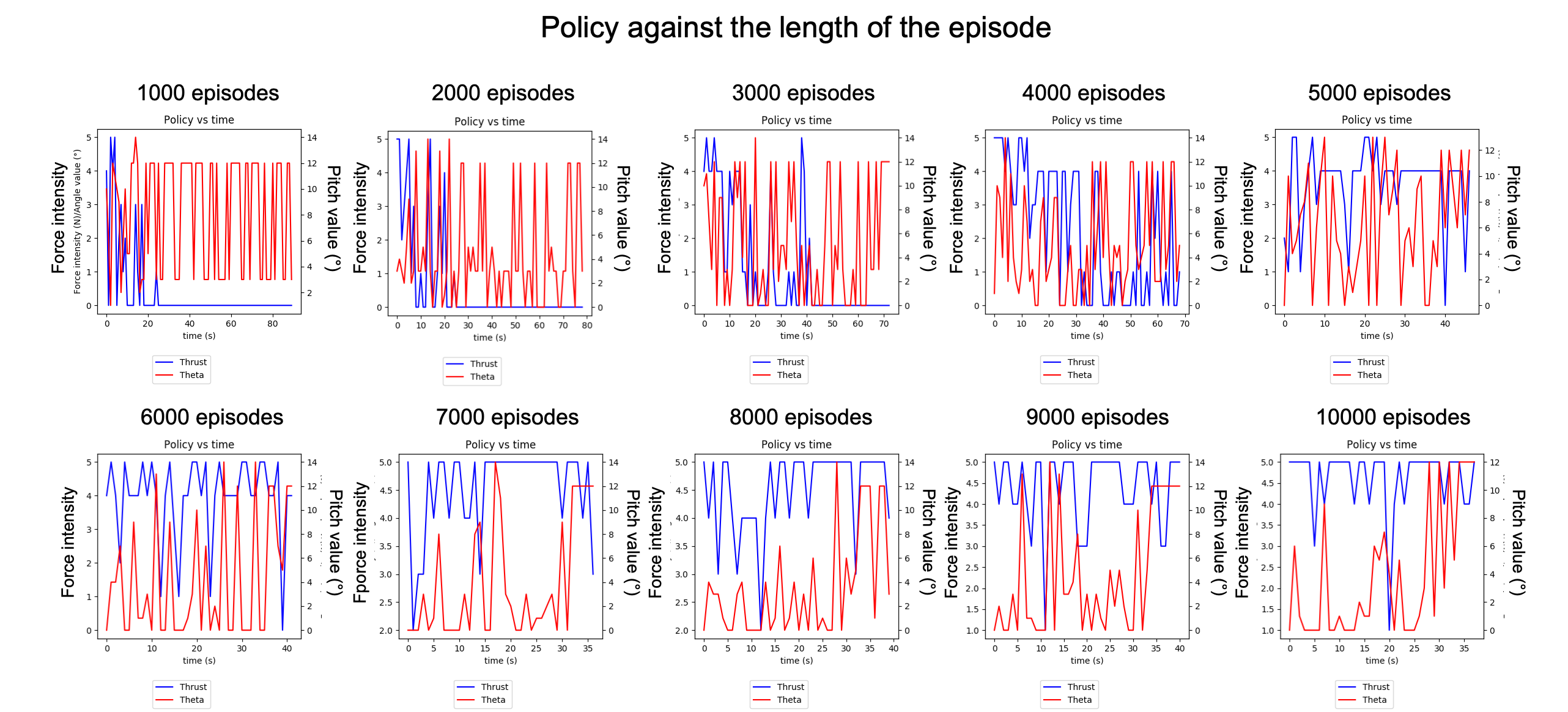
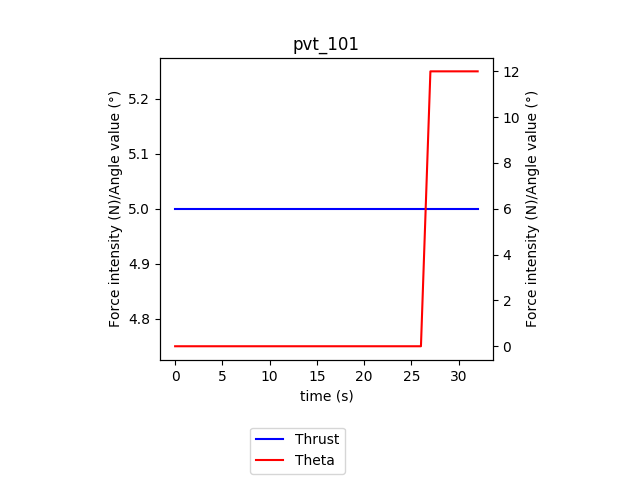
This is the evolution of the policy every thousand episodes. Each graph represents what the agent did in terms of Thrust and Pitch at each timestep of the episode. The blue curve (with values on the left) is the Thrust and the red curve (with values on the right) is the Pitch angle. At first, the agent performs seemingly random actions and does not manage to take-off.
这是每千集政策的演变。 每个图表示情节在每个情节的推力和俯仰方面的行为。 蓝色曲线(左值)是推力,红色曲线(右值)是俯仰角。 起初,代理执行看似随机的动作并且无法成功起飞。

We can then see how the agent progressively converges towards applying full thrust for the whole episode and only rotating once the plane has reached enough speed. The high variability in the actions is due to exploration and stochasticity inherent to training the agent. We will now switch to test mode to observe the actual policy (without exploration).
然后,我们可以看到特工如何逐渐收敛,以在整个情节中施加全部推力,并仅在飞机达到足够的速度时才旋转。 动作的高度可变性是由于训练代理所固有的探索性和随机性。 现在,我们将切换到测试模式以观察实际策略(无探索)。
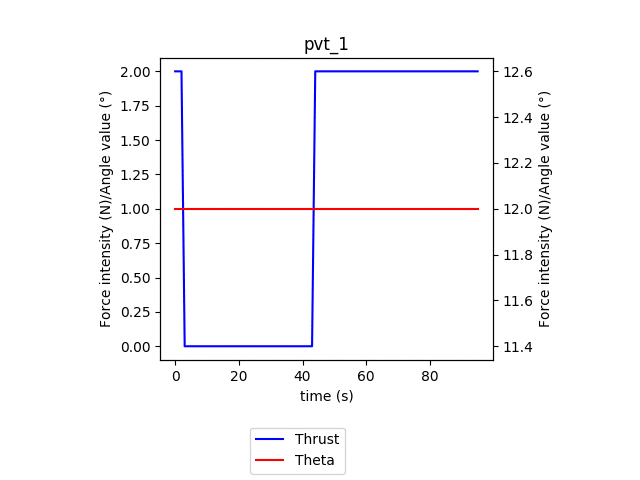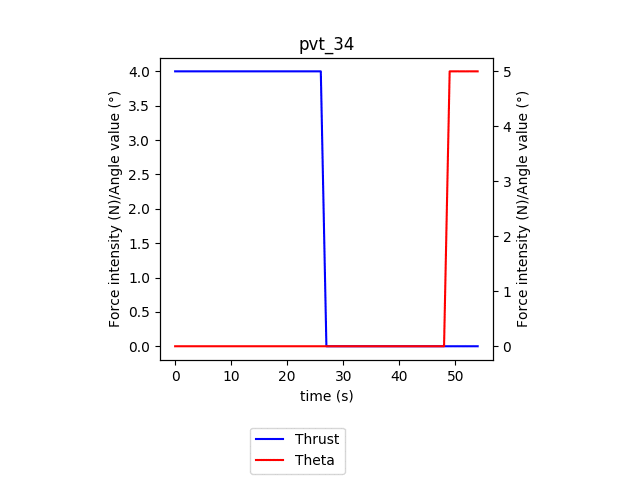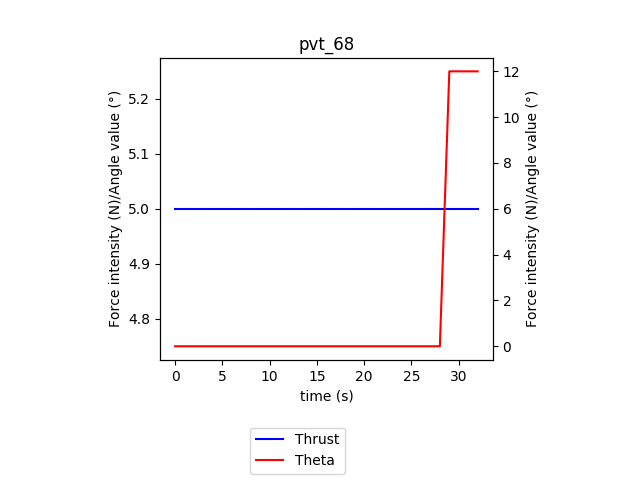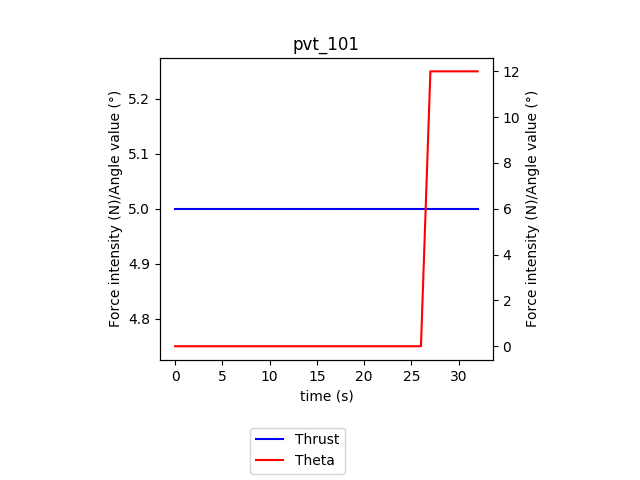
In this animation, we can see the evolution of the policy for every batch of 100 episodes over 100 batches. Similarly to the training phase, we observe the agent converge towards its final policy: applying full power for the whole episode and only rotating after gaining sufficient speed (at around 30s). We can also observe the take-off time reducing from the max allowed time for an episode of 100s to 33s.
在此动画中,我们可以看到100批次中每100集的每批次策略的演变。 与训练阶段类似,我们观察到特工朝着其最终政策收敛:在整个情节中施加全部力量,只有在获得足够的速度(大约30秒)后才旋转。 我们还可以观察到起飞时间从100s的最大允许时间减少到33s。
Here is how it goes :
这是怎么回事:

To conclude CaptAIn has managed to take-off, and even better, as good as the actual pilots! Even though this does not seem very impressive as a human would have quite easily figured out that applying full power and rotating the plane after some speed would be the way, we have to remember that CaptAIn has never seen a plane taking-off and has discovered it entirely on its own!
总而言之,CaptAIn已成功起飞,甚至比实际飞行员还要好! 尽管这似乎并不令人印象深刻,因为人类会很容易想到,施加全功率并以一定速度旋转飞机会是这种方式,但我们必须记住,CaptAIn从未见过飞机起飞并发现了它完全靠自己!

Now that we have seen how to create a custom environment in Tensorforce and use it to train and optimize an agent, you can now use the framework we have defined to apply Reinforcement Learning to your own environments and problems!
现在我们已经了解了如何在Tensorforce中创建自定义环境并使用它来训练和优化代理,您现在可以使用我们定义的框架将Reinforcement Learning应用于您自己的环境和问题!
下一步 (Next steps)
CaptAIn has just learned how to take-off, it remains to be seen how to make him achieve level flight and landing. However, those tasks were not as easy as taking-off (like in reality) and require some more complex approaches than just using pre-defined agents and “simple” rewards. In order to keep the present article on the subject of how to do a simple RL problem from scratch, we will go over reward engineering on a following article in order for captAIn to land!
CaptAIn刚刚学会了如何起飞,如何使他达到水平飞行和降落还有待观察。 但是,这些任务并不像起飞那样容易(就像现实中那样),并且需要一些比仅使用预定义的代理和“简单”奖励更为复杂的方法。 为了使本文章从头开始解决简单的RL问题,我们将在下一篇文章上进行奖励工程,以使captAIn降落!
Thanks for reading, I truly enjoyed sharing my journey into Reinforcement Learning and I would greatly appreciate your returns. Stay tuned for next part!
感谢您的阅读,我非常享受分享我的强化学习之旅的过程,也非常感谢您的回报。 敬请期待下一部分!
Yann Berthelot
扬·贝特洛(Yann Berthelot)
资源资源 (Resources)
https://www.coursera.org/learn/complete-reinforcement-learning-system/home/welcome : Great MOOC on RL theory (but lacks a little bit or real implementation, it is mostly maths, henceforth the importance of trying your own projects !)
https://www.coursera.org/learn/complete-reinforcement-learning-system/home/welcome :关于RL理论的很棒的MOOC(但缺少一点或没有真正的实现,这主要是数学,因此从此尝试尝试自己的项目!)
https://tensorforce.readthedocs.io/en/latest/ : Tensorforce documentation, pretty complete but sometimes not really self-explanatory.
https://tensorforce.readthedocs.io/en/latest/:Tensorforce文档,虽然很完整,但有时并不是很容易理解。
https://medium.com/aureliantactics/ppo-hyperparameters-and-ranges-6fc2d29bccbe : Nice article on PPO Hyperparameters
https://medium.com/aureliantactics/ppo-hyperparameters-and-ranges-6fc2d29bccbe :关于PPO超参数的不错的文章
https://towardsdatascience.com/the-complete-reinforcement-learning-dictionary-e16230b7d24e : Clear explanation of most RL terms
https://towardsdatascience.com/the-complete-reinforcement-learning-dictionary-e16230b7d24e :大部分RL术语的清晰解释
https://arxiv.org/pdf/1707.06347.pdf : The PPO paper.
https://arxiv.org/pdf/1707.06347.pdf:PPO论文。
https://toppng.com/black-and-white-airplane-PNG-free-PNG-Images_71843 : The PNG used for the plane animations
https://toppng.com/black-and-white-airplane-PNG-free-PNG-Images_71843 :用于飞机动画的PNG
人工智能中的rl是什么意思


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}