





streams.exe
Dealing with huge files has always been a challenging task to take care of. The memory consumption that this kind of processing requires is something to take into account independently from the language we are using and Node.js is no exception.
处理海量文件一直是一项艰巨的任务。 这种处理所需的内存消耗是独立于我们使用的语言来考虑的,Node.js也不例外。
Let’s see how node’s streams can make this task bearable even for a process with minimal memory availability. Specifically we’ll take advantage of streams in order to run a process that converts a Google Takeout Location History JSON into a GeoJSON.
让我们看看即使对于内存可用性最低的进程,节点的流如何使此任务可以承受。 具体来说,我们将利用流的优势来运行将Google Takeout位置记录JSON转换为GeoJSON的过程 。
问题 (The problem)
We have as an input an array of locations that are not defined according to any of the Geographic Information System standards so we want to define them.
我们输入了一系列未根据任何地理信息系统标准定义的位置,因此我们要定义它们。
Google Takeout Location History input example:
Google导出位置记录输入示例:
{
"locations": [
{
"timestampMs": "1507330772000",
"latitudeE7": 419058658,
"longitudeE7": 125218684,
"accuracy": 16,
"velocity": 0,
"altitude": 66,
}
]
}GeoJson output example:
GeoJson输出示例:
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [ 12.5218684, 41.9058658 ]
},
"properties": {
"timestamp": "2017-10-06T22:59:32.000Z",
"accuracy": 16,
"velocity": 0,
"altitude": 66
}
}
]
}The transformation that we want to perform is quite straightforward, we would like to apply to the entries of the locations array the following function.
我们要执行的转换非常简单,我们希望将以下函数应用于locations数组的条目。
const toGeoJson = googleTakeoutLocation => ({
type: 'Feature',
geometry: {
type: 'Point',
coordinates: [
googleTakeoutLocation.longitudeE7 / 10000000,
googleTakeoutLocation.latitudeE7 / 10000000,
]
},
properties: {
timestamp: new Date(Number(googleTakeoutLocation.timestampMs)),
accuracy: googleTakeoutLocation.accuracy
velocity: googleTakeoutLocation.velocity
altitude: googleTakeoutLocation.altitude
}
})This could be achieved using a simple Array.map(), however if we try to process a 2GB Google Takeout Location History JSON in order to apply a map() over the locations array we are going to face the following outcome:
可以使用一个简单的Array.map()来实现,但是,如果我们尝试处理2GB的Google Takeout位置记录JSON,以便将一个map()应用于locations数组,我们将面临以下结果:
Error message: Cannot create a string longer than 0x3fffffe7 characters
错误消息: 无法创建长度超过0x3fffffe7个字符的字符串
Error code: ERR_STRING_TOO_LONG
错误代码: ERR_STRING_TOO_LONG
解决方案 (The solution)
The only way of dealing with these huge files is using a divide and conquer approach. Instead of loading them in memory all at once we are going to create a stream of data that is going to flow from the input file to the output one. This technique will allow us to manipulate small bits of data at a time, resulting in a slow but reliable processing that is not going to eat up all our memory.
处理这些巨大文件的唯一方法是使用分而治之的方法。 与其立即将它们全部加载到内存中,我们不打算创建一个数据流,该数据流将从输入文件流到输出文件。 这种技术将使我们能够一次处理少量数据,从而导致缓慢而可靠的处理,而不会耗尽我们的所有内存。
Node.js Streams are the best tool to implement this technique. They allow us to create different pipes through which our data stream will flow and it can be steered and manipulated according to our needs.
Node.js流是实现此技术的最佳工具。 它们使我们可以创建不同的管道,数据流将通过这些管道流动,并且可以根据我们的需求进行操纵和操纵。
There are four streams (pipes) types:
有四种流(管道)类型:
Readable: data emitters, a given data source becomes a stream of data.
可读:数据发射器,给定的数据源成为数据流。
Writable: data receivers, a given stream of data ends up into a data destination.
可写的:数据接收者,给定的数据流最终到达数据目的地。
Transform: data transformers, a given data stream is mutated into a new one.
转换:数据转换器,将给定的数据流变异为新的数据流。
Duplex: data emitters and receivers at the same time
双工:数据发射器和接收器同时
In order to accomplish our goal, what we will rely on is:
为了实现我们的目标,我们将依靠的是:
One readable stream (pipe) in order to get the data out of the Google Takeout Locations JSON.
一种可读流(管道),用于从Google Takeout Locations JSON中获取数据。
A set of different transform streams (pipes) in order to modify our locations.
一组不同的转换流(管道)以修改我们的位置。
One writable stream (pipe) in order to store mutated locations into a GeoJSON output file.
一个可写流(管道),用于将变异的位置存储到GeoJSON输出文件中。
Here is how the different pipes of our stream processing approach are going to look:
这是我们的流处理方法的不同管道的外观:
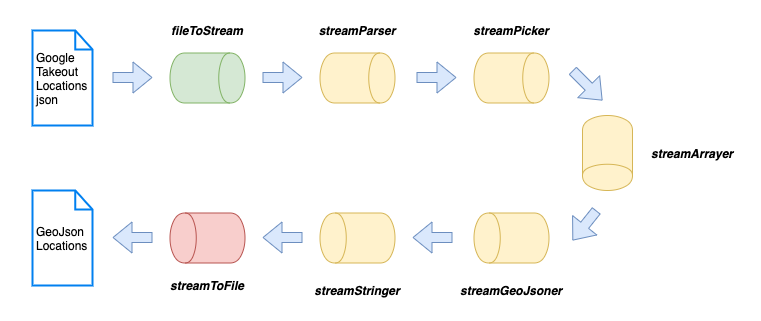
Let’s see why we need so many pipes and what role each one of them plays:
让我们看看为什么我们需要这么多管道,以及每个管道扮演什么角色:
[Read] fileToStream → Input file to stream.
[读取] fileToStream →输入要流的文件。
[Transform] streamParser → Consumes text, and produces a stream of data items corresponding to high-level tokens.
[转换] streamParser →使用文本,并生成与高级令牌相对应的数据项流。
[Transform] streamPicker → It is a token item filter, it selects objects from a stream ignoring the rest and produces a stream of objects (the locations field in our case).
[转换] streamPicker →这是一个令牌项目过滤器,它从流中选择对象而忽略其余对象,并生成对象流(在本例中为location字段)。
[Transform] streamArrayer → It assumes that an input token stream represents an array of objects and streams out those entries as assembled JavaScript objects (locations array entries in our case).
[Transform] streamArrayer →假定输入令牌流表示对象数组,并将这些条目作为组合JavaScript对象(在本例中为location数组条目)输出。
[Transform] streamGeoJsoner → It transforms google takeout locations into GeoJson locations.
[转换] streamGeoJsoner →它将Google外卖地点转换为GeoJson地点。
[Transform] streamStringer → It stringifies GeoJson locations.
[Transform] streamStringer →它将GeoJson的位置字符串化。
[Write] streamToFile → Stream to Output file.
[Write] streamToFile → 流到输出文件。
The actual transformation to GeoJSON happens at point five and it looks like this:
到GeoJSON的实际转换发生在第5点,它看起来像这样:
const streamGeoJsoner = new Transform({
objectMode: true,
transform({ key, value }, _, done) {
const googleTakeoutLocation = toGeoJson(value);
count++;
done(null, { key: count++, value: googleTakeoutLocation })
}
});As you can see we are implementing our own version of a transform pipe in order to deal with objects coming from the pipe number 4 (streamArrayer) and to apply to them the mutation defined above in the article (toGeoJson).
如您所见,我们正在实现我们自己的版本的转换管道,以便处理来自第4号管道( streamArrayer )的对象,并将上述文章中定义的变异应用于它们( toGeoJson )。
Now that we have all the pieces (pipes) in our hands it is time to connect them and make our data flow into them. We are going to do that using the pipeline utility as follows:
现在我们已经掌握了所有的部分(管道),是时候将它们连接起来并使数据流入其中了。 我们将使用管道实用程序执行以下操作:
pipeline(
fileToStream,
streamParser,
streamPicker,
streamArrayer,
streamGeoJsoner,
streamStringer,
streamToFile
);Running the above pipeline is what is going to make us reach our goal, any google takeout location JSON, no matter how big it is, can be translated into a GeoJSON avoiding huge memory consumption.
运行上面的管道将使我们达到目标,任何Google外卖位置JSON(无论大小)都可以转换为GeoJSON,从而避免占用大量内存。
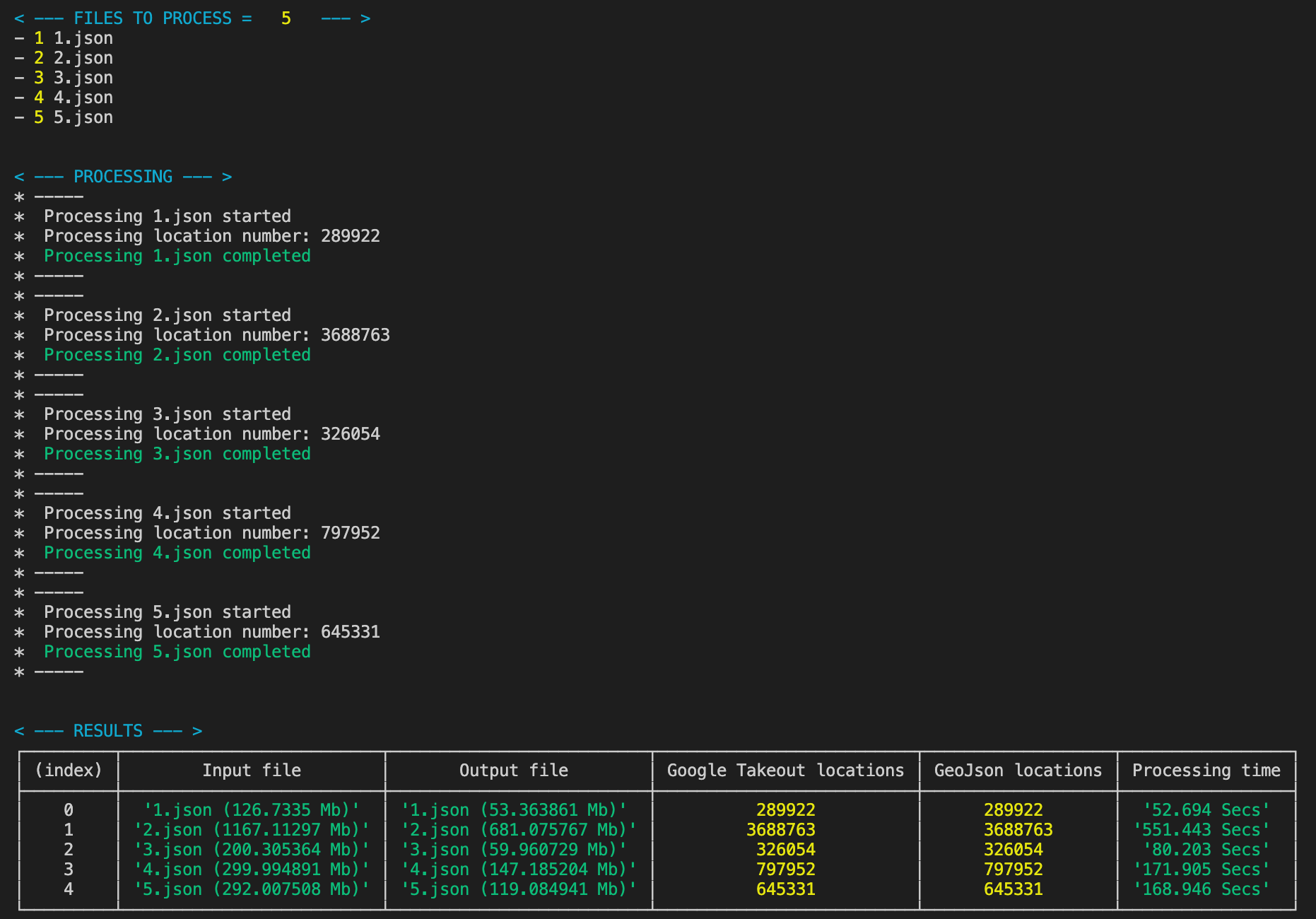
If you are interested in the whole code you can find it here. What follows is the outcome of the described solution over 5 different input files - check out the logs and have a look at file size and processing time.
如果您对整个代码感兴趣,可以在这里找到。 接下来是上述解决方案在5个不同输入文件上的结果-检查日志并查看文件大小和处理时间。
streams.exe















 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









