





The algorithms of Machine Learning try to learn from the data, and the more data available to learn and the richer and fuller the algorithm, the better it works. In this post, we will delve into the operation of some of the most used algorithms.
机器学习算法尝试从数据中学习,可学习的数据越多,算法越丰富和充分,它的效果就越好。 在本文中,我们将深入研究一些最常用的算法的操作。
Ideally, the training data (In) would be labelled (0n). For example, imagine that we want to have an algorithm that detects if a tumour is benign or malignant based on certain of its characteristics.
理想情况下,训练数据(In)应标记为(0n)。 例如,假设我们要有一种基于某些特征来检测肿瘤是良性还是恶性的算法。
Some of these characteristics could be tumour size, density, colour or other clinical data. Suppose we have a history with the characteristics of multiple tumours that we have studied in the past, this would be (In), and we already know if each one of these tumours was malignant or benign, (0n).
这些特征中的一些可能是肿瘤大小,密度,颜色或其他临床数据。 假设我们有一个过去曾研究过的具有多种肿瘤特征的病史,那就是(In),并且我们已经知道这些肿瘤中的每一个是恶性还是良性(0n)。

First, what we would do is provide our algorithm with all this data to “train” it and learn from patterns, relationships and past circumstances. In this way, we will get a trained model.
首先,我们要做的是向我们的算法提供所有这些数据,以“训练”它并从模式 ,关系和过去的情况中学习。 这样,我们将获得训练有素的模型。
Once we have this trained model, we can ask him to make a prediction by giving the characteristics of a new tumour (I), which we do not know if it is benign or malignant. The model will be able to give us a prediction (P) based on the knowledge it extracted from training data.
一旦有了经过训练的模型,我们可以要求他通过给出新肿瘤的特征做出预测(I),我们不知道它是良性还是恶性的。 该模型将能够基于从训练数据中提取的知识为我们提供预测(P)。
What defines a “good” or “bad” algorithm is the precision with which it makes the predictions in a given domain and context, and based on available training data.
定义“好”或“坏”算法的是在给定的域和上下文中并基于可用的训练数据进行预测的精度 。
Precisely the main task of data scientists is to “tune” and adjust the algorithms to suit each problem and, on the other hand, to clean and prepare the data so that the algorithm can learn as much as possible from them.
准确地说,数据科学家的主要任务是“调整”并调整算法以适合每个问题,另一方面,清理和准备数据,以便算法可以从中学习尽可能多的信息。
Next, we will discuss the characteristics of some of the most widespread algorithms and how they are able to learn from the data.
接下来,我们将讨论一些最广泛使用的算法的特征以及它们如何从数据中学习。
线性回归 (Linear regression)
Linear regression is one of the most widespread and easy to understand classical algorithms. The aim is to model the relationship between a dependent variable “y” and one or more independent variables “x”.
线性回归是最广泛且易于理解的经典算法之一。 目的是对因变量“ y”和一个或多个自变量“ x”之间的关系建模 。
Intuitively, we can imagine that it is about finding the red line that best “fits” with the set of given blue dots. To do this, we can use methods like “least squares” that seek to minimise the vertical distance of all blue points to the red line.
凭直觉,我们可以想象这是找到最能“匹配”给定蓝点集合的红线。 为此,我们可以使用“最小二乘”之类的方法,以最小化所有蓝点到红线的垂直距离。

Once this “red line” is obtained, we will be able to make hypothetical predictions about what would be the value of “y” given “x”. It is likely that we always make certain mistakes in prediction.
一旦获得此“红线”,我们将能够对给定“ x”的“ y”的值做出假设性的预测。 我们很可能在预测中总是犯某些错误。
Linear regression is a guided method, in the sense that we need an initial set sufficiently representative of “blue dots” to “learn” from them and to make good predictions.
线性回归是一种指导方法 ,从某种意义上说,我们需要一个足以代表“蓝点”的初始集合,以便从中“学习”并做出良好的预测。
Some interesting applications of linear regression are the study of the evolution of prices or markets. A classic example is the prediction of the price of housing where the variables “x” would be the characteristics of a house: size, the number of rooms, height, materials… and the “y” would be the price of that dwelling.
线性回归的一些有趣应用是对价格或市场演变的研究。 一个典型的例子是对房屋价格的预测,其中变量“ x”将是房屋的特征:大小,房间数量,高度,材料……而“ y”将是该房屋的价格。
If we could analyse the characteristics and the price of a sufficient set of houses, we could predict what would be the price of a new dwelling based on its characteristics.
如果我们能够分析足够数量的房屋的特征和价格,则可以根据其特征预测新住宅的价格。

逻辑回归 (Logistic regression)
Logistic regression has certain similarities in its approach to linear regression, but it is oriented to solve problems of classification and not of prediction.
逻辑回归在线性回归方法上有某些相似之处,但其目的是解决分类问题而不是预测问题 。

The idea is to be able to assign one category or another given some input characteristics. For this, it relies on a logistic function such as the “sigmoide” function, which takes as input any real number and returns a real number between 0 and 1 that we can read as a probability.
这个想法是能够在给定某些输入特征的情况下分配一个类别或另一个类别。 为此,它依赖于逻辑函数(例如“ sigmoide”函数),该函数将任何实数作为输入,并返回介于0和1之间的实数,我们可以将其视为概率。
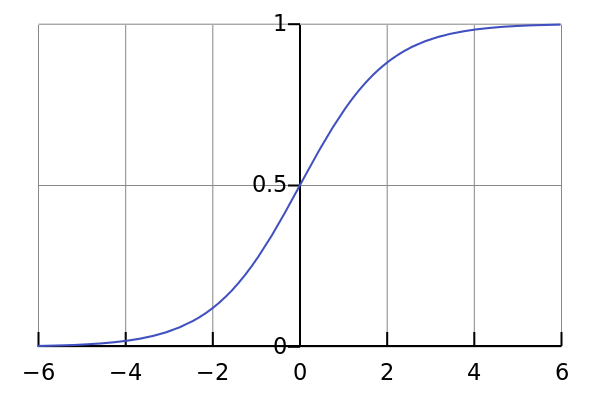
To apply logistic regression we will also need a set of data previously classified to train our algorithm. Logistic regression has multiple applications, such as risk assessment, tumour classification or SPAM detection.
为了应用逻辑回归,我们还需要一组先前分类的数据来训练我们的算法。 Logistic回归具有多种应用, 例如风险评估,肿瘤分类或SPAM检测 。
聚类K均值 (Clustering K-means)
K-means is an iterative non-guided algorithm, capable of finding clusters or relations between the data that we have without having to train it previously.
K-means是一种迭代式非导引算法,无需预先训练即可在我们拥有的数据之间找到聚类或关系 。
The idea behind this algorithm is relatively simple:
该算法的思想相对简单:
- In the first place, we will indicate how many clusters we want to identify and initialize, through some random mechanism, a point or centroid for each cluster in our data space. 首先,我们将通过某种随机机制指出要为数据空间中的每个集群标识和初始化的集群数量。
- For each input data, we will see which is the closest centroid in distance and we will assign it to that cluster. 对于每个输入数据,我们将看到距离上最接近的质心,并将其分配给该聚类。
- We will take all the points assigned to each cluster and calculate what would be its midpoint in space. 我们将获取分配给每个群集的所有点,并计算其空间中点。
- We will move the corresponding centroids to the midpoints calculated in the previous step for each cluster. 我们将把相应的质心移到上一步为每个群集计算的中点。
- Repeat iteratively from step 2 until converging. 从步骤2开始反复重复,直到收敛为止。
In this way, we will assign each point in the input space or entry value to a cluster and we will have achieved our goal.
这样,我们将输入空间或输入值中的每个点分配给一个群集,我们就可以实现我们的目标。
Its use is very widespread and is used in many fields, for example in search engines to see the similarities that exist between some elements and others. However, this algorithm is computationally complex and may require a lot of computing power.
它的使用非常广泛,并且已在许多领域中使用,例如在搜索引擎中,以查看某些元素与其他元素之间存在的相似性。 但是,该算法计算复杂,可能需要大量的计算能力。
支持向量机 (SVM)
SVM stands for Support Vector Machine. This supervised algorithm is generally used to solve classification problems.
SVM代表支持向量机。 这种监督算法通常用于解决分类问题 。
The idea of the algorithm is to be able to find, with the training data, a hyperplane that maximises the distance to the different classes, which is known as the “maximum margin”.
该算法的思想是能够利用训练数据找到一个超平面,该超平面将到不同类别的距离最大化,这被称为“最大余量”。

Once this hyperplane is found, we can use it to classify new points.
一旦找到此超平面,我们就可以使用它对新点进行分类。
SVM has multiple applications, for example for image recognition, text classification or applications in the area of biotechnology.
SVM具有多种应用,例如图像识别,文本分类或生物技术领域的应用。
随机森林 (Random forest)
Random Forest is one of the most powerful and used algorithms nowadays. It consists of a combination of multiple decision trees that together form a “forest”.
随机森林(Random Forest)是当今最强大且使用最广泛的算法之一 。 它由多个决策树的组合组成,一起形成一个“森林”。
A decision tree is a metaphor of a real tree, since, graphically, the parts of a decision tree have some resemblance to the branches of a tree.
决策树是真实树的隐喻,因为在图形上,决策树的各个部分与树的分支有些相似。
Given an input value, we will classify it by saying that it goes to one branch or another based on a condition. Decision trees can be more or less deep and complex, and the difficulty is to define them correctly so that we can correctly classify our problem data.
给定一个输入值,我们将根据条件将其转到一个分支或另一个分支进行分类。 决策树可能或多或少地复杂,而困难在于正确定义它们,以便我们可以正确地对问题数据进行分类。
Random Forest makes use of a set of decision trees and each is assigned a portion of the sample data or training. The end result will be the combination of the criteria of all the trees that form the forest.
随机森林利用一组决策树,每个决策树都分配了一部分样本数据或训练。 最终结果将是构成森林的所有树木的标准的组合。
This approach is ideal for splitting and parallelizing the work of computing, which allows us to be able to execute it very quickly using several processors.
这种方法非常适合拆分和并行化计算工作,这使我们能够使用多个处理器非常快速地执行它。

This algorithm has many applications, for example in the automotive world for the prediction of breakages of mechanical parts, or in the world of health for the classification of diseases of patients. This algorithm is also used in voice, image and text recognition tools.
该算法具有许多应用,例如在汽车领域用于预测机械零件的损坏,或在健康领域用于患者疾病的分类。 该算法还用于语音,图像和文本识别工具。
结论 (Conclusion)
These are some of the best-known algorithms, but there are many more. On the other hand, the configuration options and adjustments that we can make in each algorithm are very large, this has given rise to new profiles specialised in advanced data analytics and Machine Learning.
这些是一些最著名的算法,但是还有更多。 另一方面, 我们在每种算法中可以进行的配置选项和调整非常大 ,这导致了专门用于高级数据分析和机器学习的新配置文件的出现。
To sum up, we can say that Machine Learning is a huge field within Artificial Intelligence and, undoubtedly, the one that is having most results and applications nowadays.
综上所述,我们可以说机器学习是人工智能领域中的一个巨大领域 ,毫无疑问,这是当今成果和应用最多的领域。
Accessing this knowledge is easier than ever, and the technological possibilities allow us to have a great capacity of computation and storage of data. This allows us to apply these algorithms much easier in any business or industry, from startups to large companies.
获取这些知识比以往任何时候都更加容易,并且技术上的可能性使我们能够拥有很大的计算和存储数据的能力。 这使我们能够轻松地将这些算法应用于从初创企业到大型公司的任何企业或行业 。
Originally published at https://en.paradigmadigital.com.
最初在 https://en.paradigmadigital.com上 发布 。
翻译自: https://medium.com/swlh/machine-learning-for-dummies-65e7cd24ab61















 4992
4992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









