





uber开源
I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Time series storage and analysis is one of the most common scenarios in machine learning and one that very often requires a specialized type of storage. From time-series forecasting to all sorts of predictions, time-series data is essential to train and validate many machine learning models. Together with social networks or internet of things(IOT) scenarios, machine learning use cases are among the top contributors to the evolution of time series databases and frameworks. That market has seen an incredible level of innovation in the last few years but is still struggling to adapt to massive scale scenarios. The importance of time series analysis have influenced the release of open source stacks such as Graphite or Prometheus. However, many of the top internet have regularly outgrown those stacks and pursued the path of building their own time series infrastructure. Uber is one of the companies that have contributed the most to the time series data infrastructure space. Over a year ago, Uber open source one of the most innovative time series analysis stacks in the market: M3.
时间序列存储和分析是机器学习中最常见的场景之一,并且经常需要专门的存储类型。 从时间序列预测到各种预测,时间序列数据对于训练和验证许多机器学习模型至关重要。 与社交网络或物联网(IOT)场景一起,机器学习用例是时间序列数据库和框架发展的主要贡献者。 在过去的几年中,该市场的创新水平令人难以置信,但仍在努力适应大规模方案。 时间序列分析的重要性影响了诸如Graphite或Prometheus之类的开源堆栈的发布。 但是,许多顶级互联网通常会超过这些堆栈,并寻求建立自己的时间序列基础结构的路径。 Uber是在时序数据基础架构领域贡献最大的公司之一。 一年多以前,Uber开源了市场上最具创新性的时间序列分析堆栈之一: M3 。
Time is a core element of the Uber experience across its different apps. As a result, time series analysis seems to be a multiple more relevant than on other types of large scale businesses. Initially, Uber relied on traditional time series stacks such as Graphite, Nagios, StatsD and Prometheus to power their time series metrics. While that technology stack worked for a while, it was not able to keep up with Uber’s stratospheric growth and, by 2015, the company was in need of a proprietary time series infrastructure. That was the origin of M3 which was designed with five key guiding principles:
时间是Uber跨不同应用程序体验的核心要素。 结果,时间序列分析似乎比其他类型的大型企业更重要。 最初,Uber依靠Graphite , Nagios , StatsD和Prometheus等传统时间序列堆栈来增强其时间序列指标。 尽管该技术堆栈工作了一段时间,但它无法跟上Uber的平流层增长,到2015年,该公司需要专有的时间序列基础架构。 这就是M3的起源,它是根据五项主要指导原则设计的:
Improved reliability and scalability: to ensure we can continue to scale the business without worrying about loss of availability or accuracy of alerting and observability.
改进的可靠性和可伸缩性:确保我们可以继续扩展业务,而不必担心可用性的损失或警报和可观察性的准确性。
Capability for queries to return cross-data center results: to seamlessly enable global visibility of services and infrastructure across regions.
查询返回跨数据中心结果的能力:无缝实现跨区域的服务和基础架构的全局可见性。
Low latency service level agreement: to make sure that dashboards and alerting provide a reliable query latency that is interactive and responsive.
低延迟服务水平协议:确保仪表板和警报提供交互式和响应性的可靠查询延迟。
First-class dimensional “tagged” metrics: to offer the flexible, tagged data model that Prometheus’ labels and other systems made popular.
一流的维度“标记”指标:提供Prometheus的标记和其他系统流行的灵活的标记数据模型。
Backwards compatibility: to guarantee that hundreds of legacy services emitting StatsD and Graphite metrics continue to function without interruption.
向后兼容:确保数百个发出StatsD和Graphite指标的旧服务继续运行而不会中断。
M3 (M3)
High scalability and low latency are key principles of the M3 architecture. Any given second, M3 processes 500 million metrics and persists another 20 million aggregated metrics. Extrapolating those numbers to a 24-hour cycle indicate that M3 processes around 45 TRILLION metrics per day which is far beyond the performance of any conventional time series infrastructure. To handle that throughput, M3 relied on an architecture based on the following components:
高可伸缩性和低延迟是M3架构的关键原理。 M3每秒处理5亿个指标,并保留另外2000万个汇总指标。 将这些数字外推到24小时周期,表明M3每天处理约45个TRILLION指标,这远远超出了任何常规时间序列基础结构的性能。 为了处理该吞吐量,M3依赖于基于以下组件的体系结构:
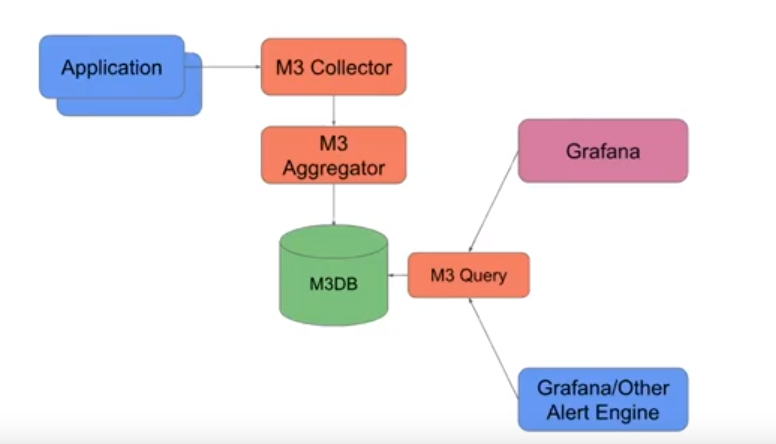
· M3DB: M3DB is a distributed time series database that provides scalable storage and a reverse index of time series. It is optimized as a cost effective and reliable real-time and long term retention metrics store and index.
· M3DB: M3DB是一个分布式时间序列数据库,提供可伸缩的存储和时间序列的反向索引。 它被优化为具有成本效益的,可靠的实时和长期保留指标存储和索引。
· M3Query: M3 Query is a service that houses a distributed query engine for querying both real-time and historical metrics, supporting several different query languages. It is designed to support both low latency real-time queries and queries that can take longer to execute, aggregating over much larger datasets, for analytical use cases.
· M3Query: M3 Query是一项服务,其中包含一个分布式查询引擎,用于查询实时和历史指标,并支持多种不同的查询语言。 它旨在支持低延迟的实时查询和执行可能需要较长时间的查询,以汇总更大的数据集以用于分析用例。
· M3 Aggregator: M3 Aggregator is a service that runs as a dedicated metrics aggregator and provides stream based down sampling, based on dynamic rules stored in etcd.
· M3聚合器: M3聚合器是一项服务,可作为专用的度量标准聚合器运行,并基于etcd中存储的动态规则提供基于流的向下采样。
· M3 Coordinator: M3 Coordinator is a service that coordinates reads and writes between upstream systems, such as Prometheus, and M3DB.
· M3协调器: M3协调器是一项服务,用于协调上游系统(例如Prometheus)和M3DB之间的读写。
· M3QL: A query language optimized for time series data.
· M3QL:一种针对时间序列数据优化的查询语言。
The relationship between the core M3 components is shown in the following figure:
下图显示了核心M3组件之间的关系:
Let’s explore some of the previous architecture building blocks in more details.
让我们更详细地探讨一些以前的体系结构构建块。
M3DB (M3DB)
M3DB is the core storage model in the M3 infrastructure. The stack was built in Go and designed for large-scale time series analysis from the ground up. The storage model is both distributed and strongly consistent which facilitates scalabilities while maintaining robust write dynamics. M3DB uses both in-memory and disk storage models depending on whether the records are frequently accessed or just used for long-term calculations respectively. From the management standpoint, M3DB is highly configurable and supported on a wide range of runtime environments.
M3DB是M3基础架构中的核心存储模型。 该堆栈是在Go中构建的,旨在从头开始进行大规模时间序列分析。 存储模型既是分布式的又是高度一致的,这有利于可扩展性,同时保持强大的写入动态。 M3DB同时使用内存和磁盘存储模型,具体取决于记录是被频繁访问还是仅用于长期计算。 从管理的角度来看,M3DB是高度可配置的,并在各种运行时环境中受支持。
One of the main contributions of M3DB is its clever storage model. Most transformations within a specific query are applied across different series for each time interval. For that reason, M3DB stores data in a columnar format facilitating the memory locality of the data. Additionally, data is split across time into blocks, enabling most transformations to work in parallel on different blocks, thereby increasing our computation speed.
M3DB的主要贡献之一是其聪明的存储模型。 在每个时间间隔内,特定查询中的大多数转换将跨不同系列应用。 因此,M3DB以列格式存储数据,以利于数据的存储位置。 此外,数据可以按时间划分为多个块,从而使大多数转换可以在不同的块上并行进行,从而提高了计算速度。

M3QL (M3QL)
Since the early days, M3 supported Prometheus Query Language(PromQL) and Graphite’s path navigation language. To extend the data access capabilities of M3, Uber decided to build M3QL a pipe-based language that complements the capabilities of path navigation with richer data access routines. Just like other pipe-based languages, M3QL allows users to read queries from left to right offering a rich syntax as shown in the following figure.
从早期开始,M3就支持Prometheus查询语言(PromQL)和Graphite的路径导航语言。 为了扩展M3的数据访问能力,Uber决定构建一种基于管道的语言M3QL,以更丰富的数据访问例程对路径导航功能进行补充。 就像其他基于管道的语言一样,M3QL允许用户从左到右读取查询,提供丰富的语法,如下图所示。

M3查询引擎 (M3 Query Engine)
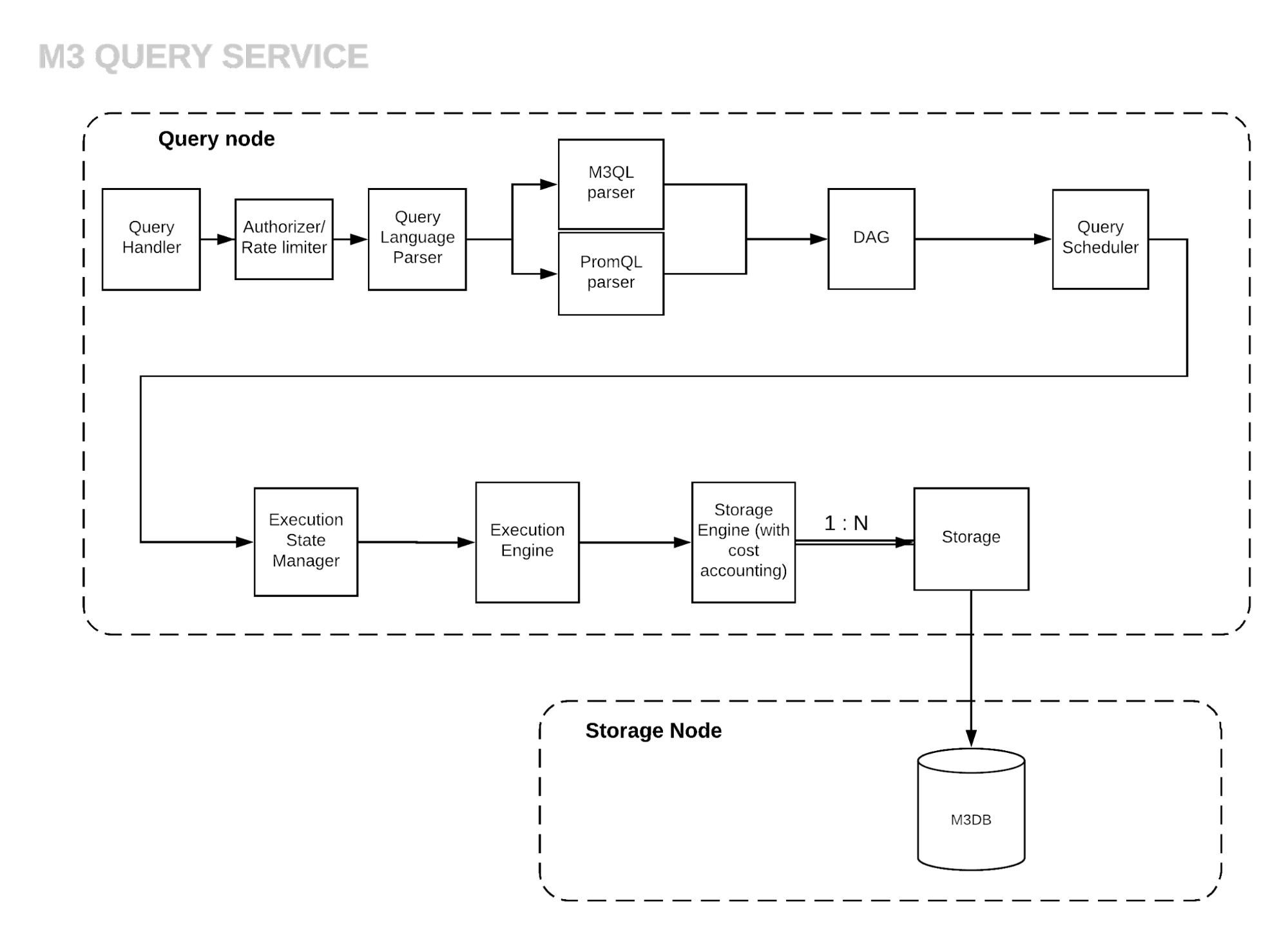
Just like other M3 components, the query engine was written in Go from the ground up and optimize for high throughput. Recent metrics from Uber are benchmarking 2500 queries per second being processed by M3’s query engine. The query engine workflow is structured into three main phases: parsing, execution and data retrieval. The query parsing and execution components work together as part of a common query service, and retrieval is done through a thin wrapper over the storage nodes. To support multiple query languages such as M3QL or PromQL, M3 introduces an intermediate representation based on a directed acyclic graph(DAG) which abstracts the query that needs to be executed. The current implementation of the query engine is tied to M3DB but the design can support other time series databases.
就像其他M3组件一样,查询引擎是从头开始用Go编写的,并针对高吞吐量进行了优化。 来自Uber的最新指标正在对M3的查询引擎每秒处理的2500个查询进行基准测试。 查询引擎工作流分为三个主要阶段:解析,执行和数据检索。 查询解析和执行组件作为公共查询服务的一部分一起工作,并且检索是通过存储节点上的精简包装来完成的。 为了支持诸如M3QL或PromQL之类的多种查询语言,M3引入了基于有向无环图(DAG)的中间表示形式,该表示形式抽象了需要执行的查询。 查询引擎的当前实现与M3DB绑定,但是该设计可以支持其他时间序列数据库。
M3协调员 (M3 Coordinator)
M3 is a very complete platform but also enables the integration with mainstream time series analysis systems such as Prometheus. M3Coordinator is a service which provides APIs for reading/writing to M3DB at a global and placement specific level. It also acts as a bridge between Prometheus and M3DB. Using this bridge, M3DB acts as a long term storage for Prometheus using the remote read/write endpoints.
M3是一个非常完整的平台,但也可以与主流时间序列分析系统(例如Prometheus)集成。 M3Coordinator是一项服务,提供用于在全局和特定于位置的级别对M3DB进行读写的API。 它还充当Prometheus和M3DB之间的桥梁。 使用此桥,M3DB可以用作使用远程读/写端点的Prometheus的长期存储。
Getting started with M3 is relatively easy as the entire platform is packaged as Docker containers. The infrastructure has been tested on major cloud platforms such as Google Cloud and the entire source code is available in their GitHub repository.
M3入门相对容易,因为整个平台都打包为Docker容器。 该基础架构已在主要的云平台(例如Google Cloud)上进行了测试,完整的源代码可在其GitHub存储库中找到 。
M3 is certainly one of the most advanced infrastructures for time series analysis in the current market. While M3 might lack the support of commercial alternatives, it comes with the robustness developed during years of supporting Uber’s time series analysis processes. Doesn’t get much better than that.
M3无疑是当前市场中用于时间序列分析的最先进的基础架构之一。 虽然M3可能缺乏商业替代品的支持,但它伴随着支持Uber时间序列分析流程多年发展而来的强大功能。 没有比这更好的了。
uber开源















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









