





Inevitably the variety of ways that one can enter Software Engineering results in many of us learning and (in this case not learning) various different concepts. Perhaps one of the most useful concepts that a Software Engineer can understand and utilise is Regular Expressions. You may have come across them before and have been completely perplexed by the characters you see before you, or you have already used them and want to gain a more comprehensive understanding. This article aims to define what Regular Expressions are, the basics of them and how you can use them, and to provide useful resources for testing RegEx expressions and furthering your learning.
不可避免地,人们可以进入软件工程的各种方式导致我们许多人学习,并且(在这种情况下不是学习)各种不同的概念。 正则表达式可能是软件工程师可以理解和利用的最有用的概念之一。 您可能以前曾经接触过它们,并且对您之前看到的字符完全感到困惑,或者您已经使用过它们并且想要获得更全面的理解。 本文旨在定义正则表达式是什么,正则表达式的基础以及如何使用它们,并提供有用的资源来测试RegEx表达式并进一步学习。
Defining Regular Expressions
定义正则表达式
Regular expressions (or regex for short), allow us to define and set rules to check whether a pattern of characters exist in a text string or not. Regular expressions help us to match, locate and manage text, providing a quick and relatively easy way to manipulate data particularly in large complex programmes.
正则表达式(或简称regex)使我们能够定义和设置规则,以检查文本字符串中是否存在字符模式。 正则表达式帮助我们匹配,定位和管理文本,从而提供了一种快速且相对容易的方式来处理数据,尤其是在大型复杂程序中。
Regular Expression: A sequence or pattern of characters used to check the existence or non-existence of a pattern in a text string
正则表达式:字符序列或模式,用于检查文本字符串中模式的存在与否
Let’s take email addresses as a quick example. When you sign up for Medium.com you are required by nature to provide an email and password. Behind the scenes Medium.com should (you never know) be using a regular expression to validate that the format of the email address is valid or that the password is valid. Normally it appears as that annoying little message that says, “your password does not contain one of the following special characters:?,!,.,”, ’ etc.”. As a quick example, we could use the following regex to filter emails in a text string that end in “@gmail.com”:
让我们以电子邮件地址为例。 当您注册Medium.com时,自然需要您提供电子邮件和密码。 在后台,Medium.com应该(不知道)使用正则表达式来验证电子邮件地址的格式有效或密码有效。 通常,它看起来像是一条令人讨厌的小消息,上面写着:“您的密码不包含以下特殊字符之一:?,!,。,”,“等”。 作为一个简单的例子,我们可以使用以下正则表达式来过滤以“ @ gmail.com”结尾的文本字符串中的电子邮件:
(@gmail.*\.com$)
(@gmail。* \。com $)
In reality this might not be a practical use of a regex, but it demonstrates the ability of the regex to test a string for a pattern matching specific characters, in this case, text string’s ending in “@gmail.com”.
实际上,这可能不是正则表达式的实际用法,但是它证明了正则表达式能够测试字符串以查找与特定字符匹配的模式的能力,在这种情况下,文本字符串以“ @ gmail.com”结尾。
正则表达式基础 (RegEx Basics)
A regular expression is constructed by combining letters and characters. At a simple level if you wanted to test for the word ‘apple’ or ‘pear’ then you could just enter this:
通过组合字母和字符来构造正则表达式。 简单来说,如果您想测试“苹果”或“梨”一词,则可以输入以下内容:
r" appler" pearA string containing the word “apple” in the first test or a string containing the word “pear” in the second test would both pass. In this sense, most letters and characters will match, however there are characters and special characters that have specific meaning in a regex expression, these are listed below and will be discussed in further detail:
第一个测试中包含单词“ apple”的字符串或第二个测试中包含单词“ pear”的字符串都会通过。 从这个意义上讲,大多数字母和字符将匹配,但是在正则表达式中存在具有特定含义的字符和特殊字符,下面列出了这些字符和特殊字符,并将对其进行详细讨论:
- Metacharacters 元字符
- Special Sequences特殊序列
- Escape Sequences转义序列
- Character Classes角色类
- Occurrence Indicators发生指标
- Position Anchors位置锚
We will also discuss the concept of greedy vs non-greedy matching in regular expressions. This does seem like a lot to cover, but do not worry as there is a summary at the bottom of the article with the key definitions included, as well as various go-to resources to help you create and remember regular expressions.
我们还将讨论正则表达式中贪婪与非贪婪匹配的概念。 这似乎涵盖了很多内容,但是请不要担心,因为本文底部有一个摘要,其中包含关键的定义,以及各种帮助您创建和记住正则表达式的参考资源。
元字符 (Metacharacters)
Metacharacters are characters with a special meaning in a regular expression. The table below shows some common regex metacharacters and the definition of each metacharacter:
元字符是在正则表达式中具有特殊含义的字符。 下表显示了一些常见的正则表达式元字符和每个元字符的定义:
Metacharacter | Description. Finds any single character
^ Start of string
$ End of string
* Matches zero or more times
+ Matches one or more times
? Matches either 0 or 1times
{} Matches all inside a set amount of times
[] Specifies a set of characters to match
\ Escapes metacharacters to match them in patterns
| Specifies either a or b (a|b)
() Captures all enclosedTo help further your understanding of each metacharacter itself, below are examples of each metacharacter in action
为了帮助您进一步了解每个元字符本身,以下是正在使用的每个元字符的示例
.Regular Expression
r” .Test String
wordIn this example, the metacharacter ‘.’ will match any character in the test string. Therefore, the test string “word” will pass in all cases.
在此示例中,元字符“。” 将匹配测试字符串中的任何字符。 因此,测试字符串“ word”在所有情况下都会通过。
^Regular Expression
r” ^wordTest String
wordThe metacharacter “^” matches the start of the string without consuming any characters. This means that the regular expression is testing for “word” at the start of the test string. If we changed the test string to “aword” instead of “word” then the test string would not match the regular expression because “word” is not at the start of the string.
元字符“ ^”匹配字符串的开头,而不消耗任何字符。 这意味着正则表达式正在测试字符串的开头测试“单词”。 如果将测试字符串更改为“ aword”而不是“ word”,则测试字符串将与正则表达式不匹配,因为“ word”不在字符串的开头。
$Regular Expression
r” word$Test String
wordIn this example, the metacharacter tests for “word” at the end of the test string. In contrast to the above if we changed the test string to “aword” then the test string would pass because “word” is at the end of the string.
在此示例中,元字符在测试字符串的末尾测试“单词”。 与上述相反,如果我们将测试字符串更改为“ aword”,则测试字符串将通过,因为“ word”位于字符串的末尾。
+Regular Expression
r” a+Test String
aaAs the metacharacter “+” tests for one or more consecutive characters, the test string “aa” would pass as the regular expression has identified two “a” characters.
当元字符“ +”测试一个或多个连续字符时,测试字符串“ aa”将通过,因为正则表达式已识别出两个“ a”字符。
?Regular Expression
r” ba?Test String
ba b aThe metacharacter ‘?’ will test for a character one or more times. In this context the regular expression is testing for the character “ba” or more times and not the character “a” itself. In the text string “ba” passes as it matches the “ba?” regex but “b” will also pass because the regex is testing for the character “b” which is not followed by a special character.
元字符“?” 将一次或多次测试一个字符。 在这种情况下,正则表达式正在测试字符“ ba”或多次,而不是字符“ a”本身。 在文本字符串中,“ ba”与“ ba?”匹配时通过正则表达式,但“ b”也将通过,因为正则表达式正在测试字符“ b”,其后没有特殊字符。
[]Regular Expression
r” [abc]Test String
aa bb cccThe square bracket metacharacter is also known as character class and tests for a set of characters enclosed in the brackets. Therefore, the test string will pass completely as “a”, “b” and “c” are all specified as characters inside the square brackets.
方括号元字符也称为字符类,用于测试括号中包含的一组字符。 因此,测试字符串将完全通过,因为“ a”,“ b”和“ c”都被指定为方括号内的字符。
\Regular Expression
r” \AhelloTest String
helloThe backslash metacharacter will be discussed in more detail later on, but essentially indicates a special sequence. In this example “\A” specifies the start of a line therefore “hello” would pass the test.
反斜杠元字符将在后面进行更详细的讨论,但是本质上表示一个特殊的序列。 在此示例中,“ \ A”指定行的开头,因此“ hello”将通过测试。
|Regular Expression
r” a|bTest String
a hello bThe “|” regex indicates either or with this regex specifying either the characters “a” or “b”. Therefore, the test string would match both “a” and “b” in the test string but would not match the word “hello” or the space characters.
“ |” regex指示或与此正则表达式一起指定字符“ a”或“ b”。 因此,测试字符串将匹配测试字符串中的“ a”和“ b”,但不匹配单词“ hello”或空格字符。
{}Regular Expression
r” a{3}Test String
aaaThe curly bracket metacharacter specifies the number of occurrences of a character. In this example, the regular expression is looking for the pattern of 3 consecutive “a” characters, which the test string provides.
大括号元字符指定字符出现的次数。 在此示例中,正则表达式正在寻找测试字符串提供的3个连续“ a”字符的模式。
(…)Regular Expression
r” (abc)Test String
a b abcThis matches whatever regular expression is inside the parentheses, indicating the start and end of a group literally. The test string in this example would not match the character “a” or the character “b” but would match the characters “abc”.
这匹配括号内的任何正则表达式,从字面上指示组的开始和结束。 在此示例中,测试字符串与字符“ a”或字符“ b”不匹配,但与字符“ abc”匹配。
特殊序列 (Special Sequences)
A special sequence is a backslash ‘\’ followed by one of the characters in the list below, each which have a special meaning in a regular expression:
一个特殊的序列是一个反斜杠“ \”,后跟下面列表中的一个字符,每个字符在正则表达式中都有特殊含义:
Special Sequences | Description\A Matches character at beginning of string\b Matches character at beginning or end\B Matches character NOT at start or end\w Matches any word character\W Matches any non-word character\d Matches any digit, ie. 0-9\D Matches any non-digit character\s Matches any whitespace character\S Matches any non-whitespace character\0 Matches any NULL character \n Matches any new line character\f Matches any form-feed character\t Matches any tab character\v Matches newlines and vertical tabs\Z Matches specified character at end of a string转义序列 (Escape Sequences)
Escape sequences are used to match special characters in a regex. This means that we can use a special character with the “\” prefix. For example;
转义序列用于匹配正则表达式中的特殊字符。 这意味着我们可以使用带有“ \”前缀的特殊字符。 例如;
Escape Sequence | Description\. Matches “.”
\+ Matches “+”
\( Matches “(“角色类 (Character Classes)
Character classes specify in a regex the characters that you want to match between the square brackets. They allow us to find a range of characters in a text string. Here are some common brackets and a description of what that allows us to specify in a RegEx expression:
字符类在正则表达式中指定要在方括号之间匹配的字符。 它们使我们能够在文本字符串中查找一系列字符。 以下是一些常见的括号,并描述了允许我们在RegEx表达式中指定的内容:
Brackets | Description[abc] Finds any character within the brackets[^abc] Finds any character NOT within the brackets[a-z] Matches any characters between a and z[^a-z] Matches any character excpet those in range a-z[a-\A-Z] Matches any character in range a-z or A-Z[0-9] Finds a digit within the brackets[^0-9] Finds a digit NOT within the brackets[(] Matches the literal '('For example, if you want to match an “a”, or a “e” use [ae]. If we specified the world “hello” as he[ae]llo then either “hallo” or “hello” would match. Character classes are an extremely common use of regular expressions, and in the email example used at the start of this article we could test for cases when a user accidentally enter “@gmeil.com” rather than “@gmail.com”.
例如,如果要匹配“ a”或“ e”,请使用[ae]。 如果我们将世界“ hello”指定为helo,那么“ hallo”或“ hello”将匹配。 字符类是正则表达式的一种非常普遍的用法,在本文开头使用的电子邮件示例中,我们可以测试用户意外输入“ @ gmeil.com”而不是“ @ gmail.com”的情况。
发生指示器(或重复运算符) (Occurrence Indicators (or Repetition Operators))
Some metacharacters mentioned above also fall under the category of occurrence indicators. These are essentially metacharacters that match a number of instances of a character, character group or character class in a string. Multiple occurrence indicators are allowed within one regular expression. These indicators are listed below:
上面提到的某些元字符也属于出现指示符的类别。 这些本质上是与字符串中的字符,字符组或字符类的多个实例匹配的元字符。 一个正则表达式中允许使用多个出现指示符。 这些指标如下:
Occurrence Indicators | Description+ Matches one or more times? Matches zero or one time* Matches zero or more times{n} Matches exactly n number of times{n,} Matches at least n number of times{n,m} Matches from n to m times{,n} Matches up to n times位置锚 (Position Anchors)
Anchors do not match any characters but instead match a position, usually before, after or between characters.
定位符不匹配任何字符,而是匹配位置,通常在字符之前,之后或之间。
Anchors | Description^ Start of string$ End of string\A Start of string\Z End of string\b Matches between start/end of a word \B Inverse (non-start or non-end of a word)贪婪vs非贪婪匹配 (Greedy vs Non-Greedy Matching)
The repetition are greedy operators by default, meaning that the match as many possible characters first. This means that if you tested the following regex:
默认情况下,重复是贪婪的运算符,这意味着首先匹配尽可能多的字符。 这意味着,如果您测试了以下正则表达式:
Regular Expression{START}.*{END}
Test String{START} Hello world 2{END} and {START} hello world 2{END}The regex would return a full match:
正则表达式将返回完整匹配:
Full Match: {START} Hello world 2{END} and {START} hello world 2{END}However, we can manage this by putting an extra “?” after the reptition operators to limit its greediness. Now, when we test the regex expression below with the same test string we actually return two matches.
但是,我们可以通过添加一个额外的“?”来解决此问题。 以后的经营者限制其贪婪。 现在,当我们使用相同的测试字符串测试下面的正则表达式时,实际上返回了两个匹配项。
Regular Expression{START}.*?{END}
Test String{START} Hello world 1{END} and {START} hello world 2{END}Match 1: {START} Hello world 1{END}
Match 2: {START} Hello world 2{END}Now that we’ve gone through a whistlestop tour of regular expressions and the different metacharacters used, the next thing to do is to practice. Below are some resources which should hopefully help you to create and test your regular expressions.
既然我们已经进行了正则表达式和使用的不同元字符的全面介绍,接下来要做的就是练习。 下面是一些资源,它们有望帮助您创建和测试正则表达式。
资源资源 (Resources)
正则测试仪(RegEx Testers)
A variety of sources exist out there to test Regular Expressions, a few of which I have listed below. They are extremely useful for quickly writing and validating a regular expression, but you should always do further testing of the expression itself by incorporating the regular expression into testing of the solution being built.
可以使用多种资源来测试正则表达式,下面列出了其中的一些。 它们对于快速编写和验证正则表达式非常有用,但是您应该始终通过将正则表达式合并到正在构建的解决方案的测试中来进一步测试表达式本身。
RegEx101 — https://regex101.com/r/22QfRq/2
RegEx101- https: //regex101.com/r/22QfRq/2
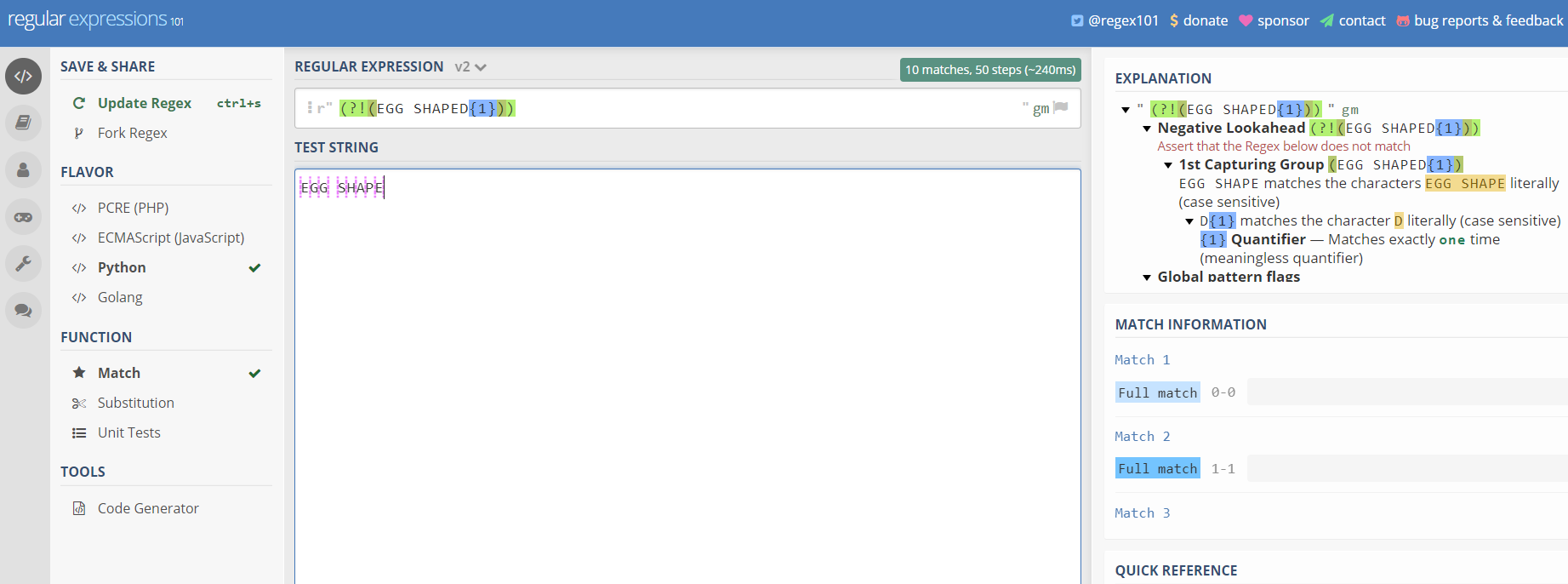
Perhaps my favourite regular expression editor, RegEx offers a clean and easy to use user interface. On the left hand side you can specify the language to the expression will be used in, in the middle you can build and test expressions and on right you can refer to a quick reference manual.
RegEx也许是我最喜欢的正则表达式编辑器,它提供了一个干净且易于使用的用户界面。 您可以在左侧指定要使用的表达式的语言,在中间可以构建和测试表达式,在右侧可以参考快速参考手册。
RegExr — https://regexr.com/
RegExr- https: //regexr.com/
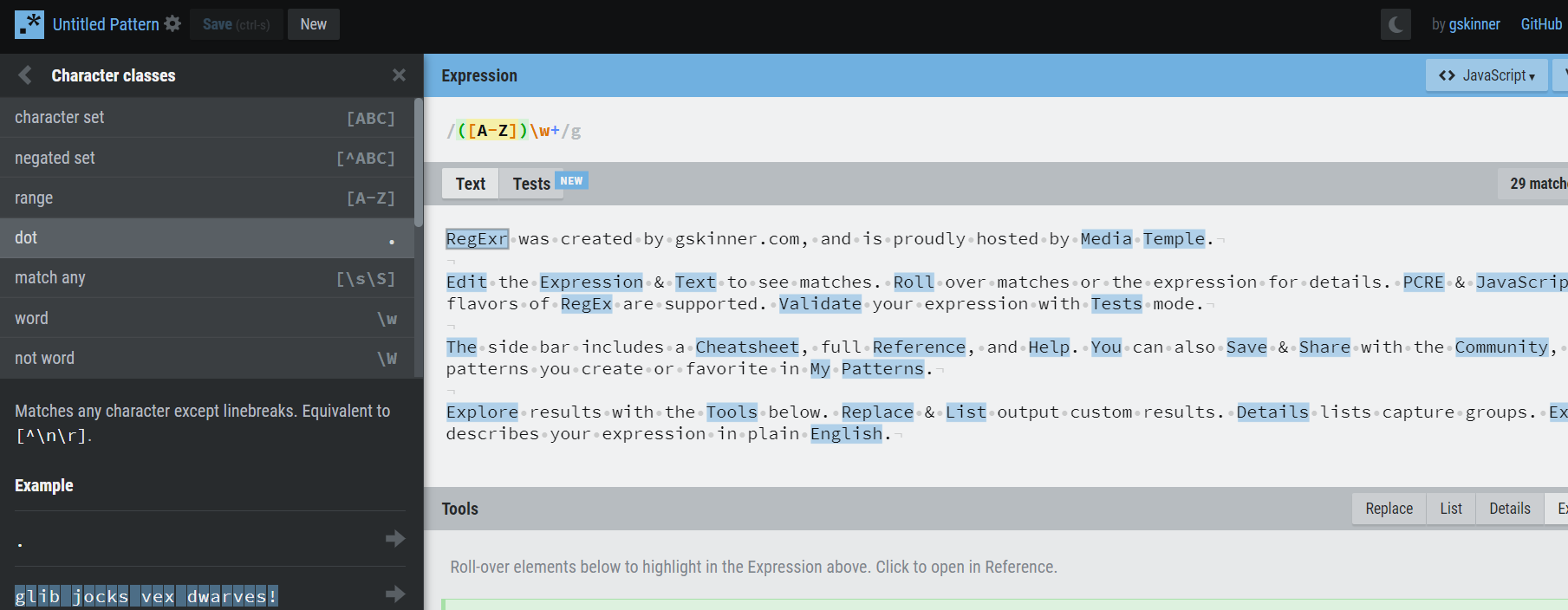
Useful for JavaScript and PCRE regular expressions, regexr provides a simple user interface with a reference guide on the left hand whilst the right hand side allows you to test expressions. This editor is somewhat limited in that it can only test JavaScript and PCRE.
regexr对JavaScript和PCRE正则表达式很有用,它提供了一个简单的用户界面,左侧带有参考指南,而右侧则允许您测试表达式。 该编辑器的局限性在于只能测试JavaScript和PCRE。
regextester — https://www.regextester.com/
regextester- https: //www.regextester.com/
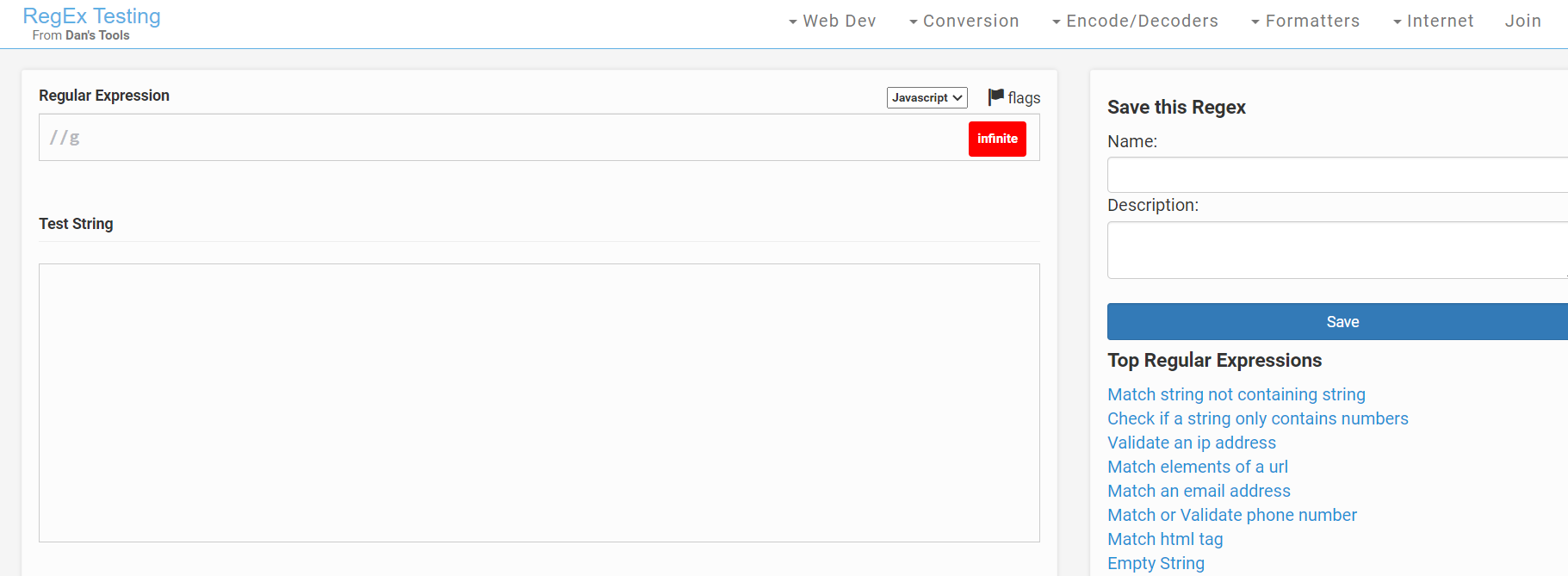
Again another useful editor, regextester allows you to write and save regular expressions as well as click on useful hyperlinks that show examples of common regular expressions.
regextester还是另一个有用的编辑器,它使您可以编写和保存正则表达式,还可以单击显示常用正则表达式示例的有用超链接。
At the end of the day, picking a regular expression editor is likely to come down to preference. My favourite is regex101 and this is by no means an exhaustive list of editors so it is worth looking around.
归根结底,选择正则表达式编辑器很可能会变成首选。 我最喜欢的是regex101,这绝不是详尽的编辑列表,因此值得一看。
正则表达式文档 (RegEx Documentation)
Likewise with RegEx testers, there are also various reference guides available that can help you construct RegEx expressions.
与RegEx测试器一样,也有各种参考指南可帮助您构造RegEx表达式。
Microsoft — https://docs.microsoft.com/en-us/dotnet/standard/base-types/regular-expression-language-quick-reference
w3Schools (Python) — https://www.w3schools.com/python/python_regex.asp
W3Schools的(Python) - https://www.w3schools.com/python/python_regex.asp
w3Schools (JavaScript) — https://www.w3schools.com/jsref/jsref_obj_regexp.asp
W3Schools的(JavaScript的) - https://www.w3schools.com/jsref/jsref_obj_regexp.asp
Python Regex Cheatsheet — https://www.debuggex.com/cheatsheet/regex/python
Python Regex速查表— https://www.debuggex.com/cheatsheet/regex/python
JavaScript Regex Cheatsheet — https://www.debuggex.com/cheatsheet/regex/javascript
JavaScript Regex备忘单— https://www.debuggex.com/cheatsheet/regex/javascript
PCRE Regex Cheatsheet — https://www.debuggex.com/cheatsheet/regex/pcre
PCRE Regex速查表— https://www.debuggex.com/cheatsheet/regex/ pcre
概要 (Summary)
总览(Overview)
- A Regular Expression is a text string that describes a pattern of characters that a regular expression engine attempts to match正则表达式是一个文本字符串,描述了正则表达式引擎尝试匹配的字符模式
- Regular expressions allow us to detect, extract, replace, and match strings in order to extract key information from text正则表达式使我们能够检测,提取,替换和匹配字符串,以便从文本中提取关键信息
- There are a variety of regular expression reference guides and online editors available, which allow you to test regular expressions before incorporating them into your solutions提供了多种正则表达式参考指南和在线编辑器,使您可以在将正则表达式合并到解决方案中之前对其进行测试。
特殊字符: (Special Characters:)
Metacharacters: Characeters with special meaning
元字符:具有特殊含义的字符
Special Sequences: A backslash “\” followed by a specific character
特殊序列:反斜杠“ \”后跟特定字符
Escape Sequences: Used to match a special character in a regex
转义序列:用于匹配正则表达式中的特殊字符
Character Classes: Specify characters to match within enclosed square brackets
字符类:指定字符以匹配方括号内的字符
Occurrence Indicators: Metacharacters that match a number of instances of a character
出现指示符:与多个字符实例匹配的元字符
Position Anchors: Match a position, usually before, after or between characters.
位置锚点:通常在字符之前,之后或之间匹配位置。
If you’ve taken the time to read this article then thank you for doing so. Hopefully this has provided some use to you and the resources section can guide your further learning.
如果您花时间阅读本文,那么谢谢您。 希望这对您有所帮助,资源部分可以指导您进一步学习。
翻译自: https://towardsdatascience.com/the-essentials-of-regular-expressions-b52af8fe271a















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









