






数据库范式
关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
第一范式(1NF)
是对属性的 原子性 的要求,要求属性具有原子性,不可再分解;
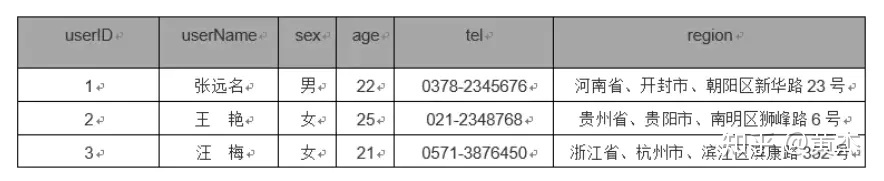
如这个user表就不符合第一范式,因为region列不具有原子性,能拆分成省份、市和具体地址
正确做法

第二范式(2NF)
2NF是对记录的 唯一性 ,要求记录有惟一标识,即实体的惟一性,即不存在部分依赖;
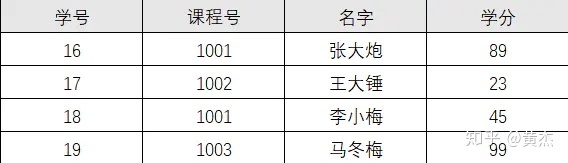
这个表明显说明了两个事务:学生信息, 课程信息;
由于非主键字段必须依赖主键,这里学分依赖课程号,名字依赖与学号,所以不符合二范式。
这么做可能会存在问题:
- 数据冗余:,每条记录都含有相同信息;
- 删除异常:删除所有学生成绩,就把课程信息全删除了;
- 插入异常:学生未选课,无法记录进数据库;
- 更新异常:调整课程学分,所有行都调整。
正确做法:
- 学生:Student(学号, 姓名);
- 课程:Course(课程号, 学分);
- 选课关系:StudentCourse(学号, 课程号, 成绩)。
第三范式(3NF)
3NF是对字段的冗余性 ,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
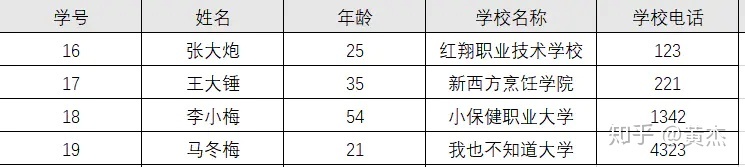
因为存在依赖传递: (学号) → (姓名)→(所在学校) → (学校电话) 。
可能会存在问题:
- 数据冗余:有重复值;
- 更新异常:有重复的冗余信息,修改时需要同时修改多条记录,否则会出现数据不一致的情况 。
正确做法:
- 学生:(学号, 姓名, 年龄, 所在学院);
- 学院:(学院, 电话)。
面试官:回答的不错,那你平时设计的时候都遵守三大范式吗?不遵守的话什么时候会去突破范式?
没有规矩不成方圆,一般下我会遵守三大范式。
没有冗余的数据库设计可以做到三大范式都遵守。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。
具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余,达到以空间换时间的目的。
面试官:好,那你最后再说下,遵守范式化设计和不遵守范式化设计,也就是反范式化设计的优缺点?
范式化设计的优点在于:
- 可以尽量的减少数据冗余,数据表更新快体积小
- 范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化更小
缺点在于:
- 对于查询需要对多个表进行关联(导致性能降低)
- 更难进行索引优化
Mysql语法
语法应该会问join,其他不会问
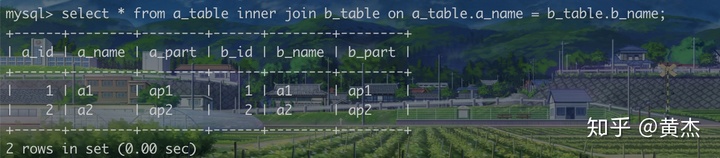
内连接
- select * from A INNER JOIN B ON 条件
- 返回两个集合交集的部分
左连接
- select * from A left join B on 条件
- 左表会显示全部元素,右表会显示符合条件的部分+其他不符合条件的部分[NULL表示]
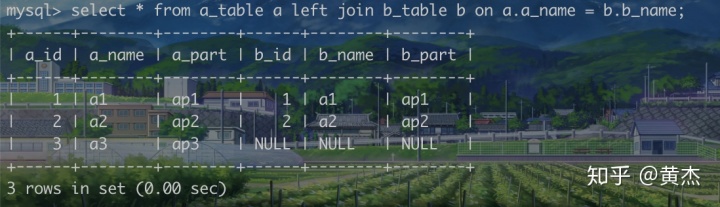
右连接
- select * from A right join B on 条件
- 右表会显示全部,左表会显示符合提交的部分+其他不符合条件的部分[NULL表示]

练习题
1. distinct关键词
这是一张成绩单表,通过一条sql查询出所有学科都及格(60分)的学生。
我写了的用到了子查询,然后问我不用子查询怎么做?
姓名 学科 分数
张三 英语 60
张三 数学 70
张三 语文 58
李四 英语 80
//创建测试用例
create table Student(
id int(11) primary key auto_increment,
name varchar(20),
course varchar(20),
score int(11)
)ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
insert into Student (name,course,score) values ('张三','数学',60);
insert into Student (name,course,score) values ('张三','英语',70);
insert into Student (name,course,score) values ('张三','语文',50);
insert into Student (name,course,score) values ('李四','英语',80);
select distinct name from Student where score > 60;2. 第二高薪水
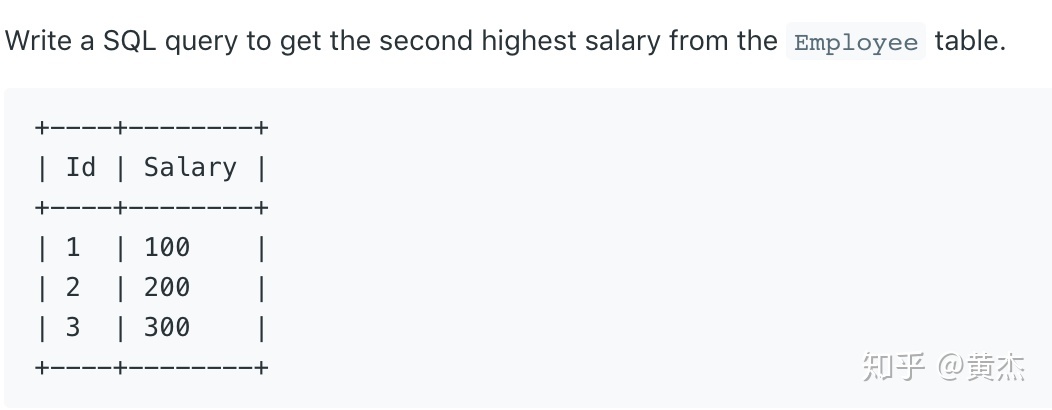
# 从所有小于最大值的salary中找到的最大的——second
SELECT MAX(Salary) FROM Employee
Where Salary <
(SELECT MAX(Salary) FROM Employee);3. 学生平均分
group by
我们需要得到所有功课平均分达到60分的同学和他们的均分:[https://www.cnblogs.com/hhe0/p/9556070.html]
CREATE TABLE `courses` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增id',
`student` VARCHAR(255) DEFAULT NULL COMMENT '学生',
`class` VARCHAR(255) DEFAULT NULL COMMENT '课程',
`score` INT(255) DEFAULT NULL COMMENT '分数',
PRIMARY KEY (`id`),
UNIQUE KEY `course` (`student`, `class`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SELECT `student`, AVG(`score`) AS`avg_score`
FROM `courses`
GROUP BY `student`
HAVING AVG(`score`) >= 60
ORDER BY `avg_score` DESC;














 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









