





机器学习中激活函数和模型
In this post, we’re going to discuss the most widely-used activation and loss functions for machine learning models. We’ll take a brief look at the foundational mathematics of these functions and discuss their use cases, benefits, and limitations.
在本文中,我们将讨论用于机器学习模型的最广泛使用的激活和损失函数。 我们将简要介绍这些功能的基础数学,并讨论它们的用例,好处和局限性。
Without further ado, let’s get started!
事不宜迟,让我们开始吧!
什么是激活功能? (What is an Activation Function?)
To learn complex data patterns, the input data of each node in a neural network passes through a function the limits and defines that same node’s output value. In other words, it takes in the output signal from the previous node and converts it into a form interpretable by the next node. This is what an activation function allows us to do.
为了学习复杂的数据模式,神经网络中每个节点的输入数据都要通过一个函数限制,并定义相同节点的输出值。 换句话说,它接收来自前一个节点的输出信号,并将其转换为下一个节点可解释的形式。 这就是激活功能允许我们执行的操作。
需要激活功能 (Need for an Activation function)
Restricting value: The activation function keeps the values from the node restricted within a certain range, because they can become infinitesimally small or huge depending on the multiplication or other operations they go through in various layers (i.e. the vanishing and exploding gradient problem).
限制值:激活函数将节点的值限制在一定范围内,因为根据它们在各个层中经历的乘法或其他运算(即消失和爆炸梯度问题),它们的值可能无限小或很大。
Add non-linearity: In the absence of an activation function, the operations done by various functions can be considered as stacked over one another, which ultimately means a linear combination of operations performed on the input. Thus, a neural network without an activation function is essentially a linear regression model.
增加非线性:在没有激活功能的情况下,可以将各种功能完成的操作视为彼此叠加,这最终意味着对输入执行的操作的线性组合。 因此, 没有激活函数的神经网络本质上是线性回归模型 。
激活功能的类型 (Types of Activation functions)
Various types of activation functions are listed below:
下面列出了各种类型的激活功能:
乙状结肠激活功能 (Sigmoid Activation function)
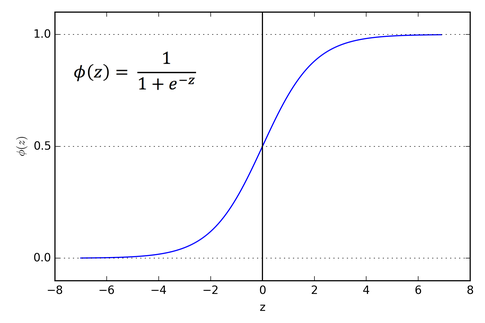
The sigmoid function was traditionally used for binary classification problems (goes along the lines of “if x≤0.5, y=0 else y=1”). But, it tends to cause vanishing gradients problem, and if the values are too close to 0 or +1, the curve or gradient is almost flat and thus the learning would be too slow.
S型函数通常用于二进制分类问题(沿“如果x≤0.5,y = 0,否则y = 1”)。 但是,它往往会导致梯度消失的问题 ,并且,如果值太接近0或+1,则曲线或梯度几乎是平坦的,因此学习会太慢。
It’s also computationally expensive, since there are a lot of complex mathematical operations involved.
由于涉及许多复杂的数学运算,因此它在计算上也很昂贵。
Tanh激活功能 (Tanh Activation Function)
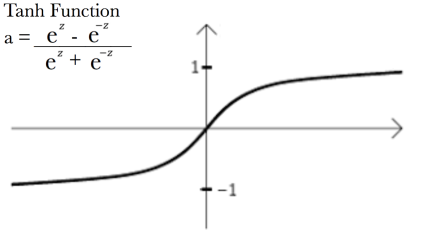
The tanh function was also traditionally used for binary classification problems (goes along the lines of “if x≤0, y=0 else y=1”).
传统上,tanh函数也用于二进制分类问题(沿“如果x≤0,y = 0,否则y = 1”的线)。
It’s different than sigmoid in the sense that it’s zero-centred, and thus restricts input values between -1 and +1. It’s even more computationally expensive than sigmoid since there are a lot of complex mathematical operations involved, which need to be performed for every input and iteration, repeatedly.
它在以零为中心的意义上不同于Sigmoid,因此将输入值限制在-1和+1之间。 它比Sigmoid的计算成本更高,因为其中涉及许多复杂的数学运算,每个输入和迭代都需要重复执行这些运算。
ReLU激活功能 (ReLU Activation Function)
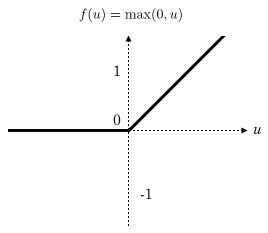
ReLU is a famous, widely-used non-linear activation function, which stands for Rectified Linear Unit (goes along the lines of “if x≤0, y=0 else y=1”).
ReLU是一个著名的,广泛使用的非线性激活函数,代表整流线性单位(沿“如果x≤0,y = 0,否则y = 1”的线)。
Thus, it’s only activated when the values are positive. ReLU is less computationally expensive than tanh and sigmoid because it involves simpler mathematical operations.
因此,仅当值为正时才激活它。 ReLU在计算上比tanh和Sigmoid 便宜 ,因为它涉及更简单的数学运算。
But it faces what’s known as the “dying ReLU problem”—that is, when inputs approach zero, or are negative, the gradient of the function becomes zero, and thus the model learns slowly. ReLU is considered a go-to function if one is new to activation function or is unsure about which one to choose.
但是它面临着所谓的“即将死去的ReLU问题”,也就是说,当输入接近零或为负时,函数的梯度变为零,因此模型学习缓慢 。 如果对激活功能不熟悉或不确定要选择哪个功能,则ReLU被认为是一项入门功能。
泄漏ReLU激活功能 (Leaky-ReLU Activation function)
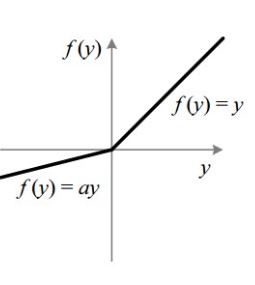
The leaky ReLU function proposes a solution to the dying ReLU problem. It has a small positive slope in the negative plane, so it enables the model to learn, even for negative input values.
泄漏的ReLU函数为即将死去的ReLU问题提出了解决方案。 它在负平面上具有小的正斜率,因此即使对于负输入值,它也使模型能够学习。
Leaky ReLUs are widely used with generative adversarial networks. Parametric leaky ReLUs use a value “alpha”, which is usually around 0.1, to determine the slope of the function in the negative plane.
泄漏的ReLU被广泛用于生成对抗网络 。 参数泄漏ReLU使用值“ alpha”(通常约为0.1)来确定函数在负平面中的斜率。
Softmax激活功能 (Softmax Activation Function)
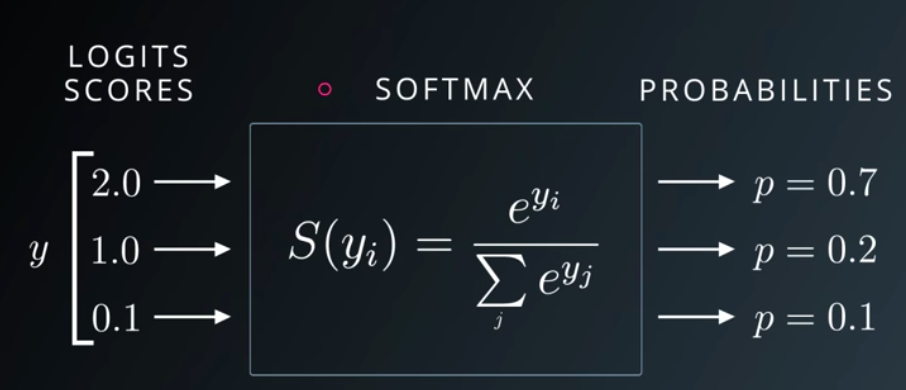
The softmax function is a function that helps us represent inputs in terms of a discrete probability distribution. According to the formula, we need to apply an exponential function to each element of the output layer and normalize the values to ensure their summation is 1. The output class is the one with the highest confidence score.
softmax函数是帮助我们以离散概率分布表示输入的函数。 根据公式,我们需要对输出层的每个元素应用指数函数,并对值进行归一化以确保其总和为1。输出类是置信度得分最高的类。
This function is mostly used as the last layer in classification problems—especially multi-class classification problems—where the model ultimately outputs a probability for each of the available classes, and the most probable one is chosen as the answer.
此功能通常用作分类问题(尤其是多分类问题)的最后一层,在该问题中,模型最终为每个可用分类输出概率,然后选择最有可能的一个作为答案。
The future of machine learning is on the edge. Subscribe to the Fritz AI Newsletter to discover the possibilities and benefits of embedding ML models inside mobile apps.
机器学习的未来处于边缘。 订阅Fritz AI新闻简报,发现将ML模型嵌入移动应用程序的可能性和好处 。
什么是损失函数? (What is a Loss Function?)
To understand how well/poorly our model is working, we monitor the value of loss functions for several iterations. It helps us measure the accuracy of our model and understand how our model behaves for certain inputs. Thus, it can be considered as the error or deviation in the prediction from the correct classes or values. The larger the value of the loss function, the further our model strays from making the correct prediction.
为了了解我们的模型工作的好坏,我们监视损失函数的值进行多次迭代。 它可以帮助我们评估模型的准确性,并了解模型在某些输入下的行为。 因此, 可以将其视为与正确的类或值的预测中的误差或偏差 。 损失函数的值越大,我们的模型就越无法做出正确的预测。
损失函数的类型 (Types of loss functions)
Depending on the type of learning task, loss functions can be broadly classified into 2 categories:
根据学习任务的类型,损失函数可以大致分为两类:
Regression loss functions
回归损失函数
Classification loss functions
分类损失函数
回归损失函数 (Regression Loss Functions)
In this sub-section, we’ll discuss some of the more widely-used regression loss functions:
在本小节中,我们将讨论一些更广泛使用的回归损失函数:
平均绝对误差或L1损耗(MAE) (Mean Absolute Error or L1 Loss (MAE))
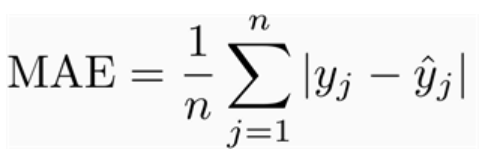
The mean absolute error is the average of absolute differences between the values predicted by the model and the actual values. There’s an issue with MAE though—if some values are underestimated (negative value of error) and some are almost equally overestimated (positive value of error), they might cancel each other out, and we may get the wrong idea about the net error.
平均绝对误差是模型预测的值与实际值之间的绝对差的平均值。 但是,MAE存在一个问题-如果某些值被低估(错误的负值),而有些值几乎同样被高估了(错误的正值),它们可能会相互抵消,并且我们可能会得出关于净错误的错误观念。
均方误差或L2损耗(MSE) (Mean Squared Error or L2 Loss(MSE))
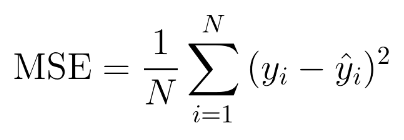
The mean squared error is the average of the squared differences between the values predicted by the model and the actual values. Squaring the error also helps us avoid the nullification issue faced by MAE.
均方误差是模型预测的值与实际值之间的平方差的平均值。 对错误进行平方也有助于我们避免MAE面临的无效问题。
MSE is also used to emphasize the error terms in cases where the input and output values have small scales. Thus, due to squaring the error terms, large errors have relatively greater influence when using MSE than smaller errors.
在输入和输出值的比例较小的情况下,MSE还用于强调误差项。 因此,由于对误差项进行平方,因此使用MSE时,大误差比小误差具有更大的影响。
However, this can be a gamble when there are a lot of outliers in your data. Since the outliers would have greater weight due to higher error values being squared, it can make the error or loss function biased. Thus, outlier eradication should be performed before applying MSE.
但是,当数据中有很多异常值时,这可能是一场赌博。 由于较高的误差值会导致异常值具有更大的权重,因此会使误差或损失函数产生偏差。 因此,应在应用MSE之前执行离群值消除。
胡贝尔损失 (Huber loss)
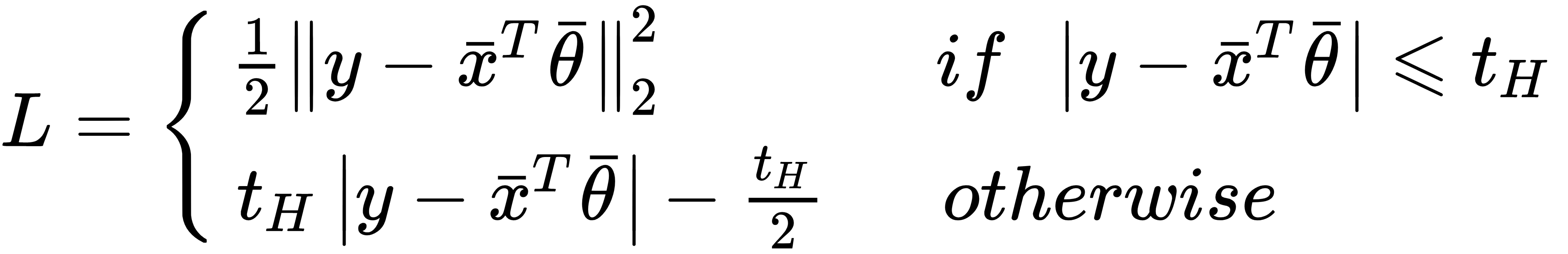
Huber loss is an absolute error, and as you can see from the formula above, it becomes quadratic as the error grows smaller and smaller. In the above formula, y is the expected value, xᵗ ϴ is the predicted value, and tₕ is a user-defined hyper-parameter.
Huber损耗是绝对误差,从上式可以看出,随着误差变得越来越小,它变为二次方。 在上式中,y是期望值,xᵗ是预测值,tₕ是用户定义的超参数。
分类损失函数 (Classification Loss Functions)
In this sub-section, we’ll discuss some of the more widely-used loss functions for classification tasks:
在本小节中,我们将讨论用于分类任务的一些更广泛使用的损失函数:
交叉熵损失 (Cross-Entropy loss)
This loss is also called log loss. To understand cross-entropy loss, let’s first understand what entropy is. Entropy refers to the disorder or uncertainty in data. The larger the entropy value, the higher the level of disorder.
此丢失也称为对数丢失。 为了了解交叉熵损失,让我们首先了解什么是熵。 熵是指数据的混乱或不确定性。 熵值越大,无序程度越高。
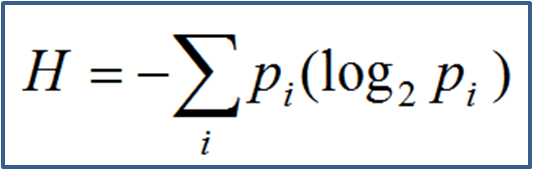
As you can see in the above formula, the entropy is basically the negative summation of the product of the probability of occurrence of an event with its log over all possible outcomes. Thus, cross entropy as a loss function signifies reducing entropy or uncertainty for the class to be predicted.
如上式所示,熵基本上是事件发生概率与所有可能结果的对数的乘积的负和。 因此,作为损失函数的交叉熵表示要预测的类别的熵或不确定性降低。
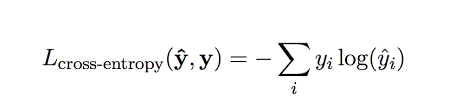
Cross-entropy loss is therefore defined as the negative summation of the product of the expected class and the natural log of the predicted class over all possible classes. The negative sign is used because the positive log of numbers < 1 returns negative values, which is confusing to work with while evaluating model performance.
因此,交叉熵损失定义为在所有可能类别上,预期类别与预测类别的自然对数之积的负和。 使用负号是因为数字<1的正对数会返回负值,这在评估模型性能时会造成混淆。
For example, if the problem at hand is binary classification, the value of y can be 0 or 1. In such a case, the above loss formula reduces to:
例如,如果眼前的问题是二进制分类,则y的值可以为0或1。在这种情况下,上述损耗公式可简化为:
-(ylog(p)+(1−y)log(1−p))
-(ylog(p)+(1-y)log(1-p))
where p is the value of predicted probability that an observation O is of class C.
其中p是观测值O属于C类的预测概率的值。
Thus, the loss function over the complete set of samples would be:
因此,整个样本集的损失函数为:
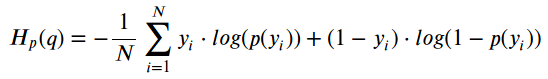
铰链损失 (Hinge loss)
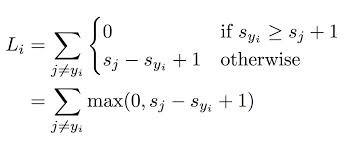
Hinge loss helps in penalizing the wrongly-predicted values, as well as the values that were correctly predicted but with a lower probability score. Hinge loss is primarily used with Support Vector Machines (SVMs), since it supports the formation of a large-margin classifier by penalizing wrongly-predicted values, as well as the correctly-predicted ones with low probability.
铰链损失有助于惩罚错误预测的值以及正确预测但具有较低概率分数的值。 铰链损耗主要与支持向量机(SVM)一起使用,因为它通过惩罚错误预测的值以及低概率正确预测的值来支持大利润分类器的形成。
结论 (Conclusion)
In this post we discussed about various activation functions like sigmoid, tanh, ReLU, leaky-ReLU and softmax, along with their primary use cases. These are the most widely-used activation functions and are essential for developing efficient neural networks.
在这篇文章中,我们讨论了各种激活函数,例如Sigmoid,tanh,ReLU,leaky-ReLU和softmax,以及它们的主要用例。 这些是使用最广泛的激活函数,对于开发有效的神经网络至关重要。
We also discussed a few major loss functions like mean squared error, mean absolute error, huber loss, cross-entropy loss, and hinge loss.
我们还讨论了一些主要的损失函数,例如均方误差,平均绝对误差,huber损失,交叉熵损失和铰链损失。
I hope this article has helped you learn and understand more about these fundamental ML concepts. All feedback is welcome. Please help me improve!
我希望本文能帮助您学习和了解有关这些基本ML概念的更多信息。 欢迎所有反馈。 请帮我改善!
Until next time!😊
直到下次!😊
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to exploring the emerging intersection of mobile app development and machine learning. We’re committed to supporting and inspiring developers and engineers from all walks of life.
编者注: 心跳 是由贡献者驱动的在线出版物和社区,致力于探索移动应用程序开发和机器学习的新兴交集。 我们致力于为各行各业的开发人员和工程师提供支持和启发。
Editorially independent, Heartbeat is sponsored and published by Fritz AI, the machine learning platform that helps developers teach devices to see, hear, sense, and think. We pay our contributors, and we don’t sell ads.
Heartbeat在编辑上是独立的,由以下机构赞助和发布 Fritz AI ,一种机器学习平台,可帮助开发人员教设备看,听,感知和思考。 我们向贡献者付款,并且不出售广告。
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Fritz AI Newsletter), join us on Slack, and follow Fritz AI on Twitter for all the latest in mobile machine learning.
如果您想做出贡献,请继续我们的 呼吁捐助者 。 您还可以注册以接收我们的每周新闻通讯(《 深度学习每周》 和《 Fritz AI新闻通讯》 ),并加入我们 Slack ,然后继续关注Fritz AI Twitter 提供了有关移动机器学习的所有最新信息。
翻译自: https://heartbeat.fritz.ai/exploring-activation-and-loss-functions-in-machine-learning-39d5cb3ba1fc
机器学习中激活函数和模型














 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









