





基于kb的问答系统
介绍 (Introduction)
Q-learning is an algorithm in which an agent interacts with its environment and collects rewards for taking desirable actions.
Q学习是一种算法,其中代理与它的环境进行交互,并为采取期望的行动而收集奖励。
The simplest implementation of Q-learning is referred to as tabular or table-based Q-learning. There are tons of articles, tutorials, etc. already available on the web which describe Q-learning so I won’t go into excruciating detail here. Instead, I want to show how efficiently table-base Q-learning can be done using tinymind. In this article, I will describe how tinymind implements Q-learning using C++ templates and fixed-point (Q-format) numbers as well as go thru the example in the repo.
Q学习的最简单实现称为表格或基于表的Q学习。 网络上已经有大量的文章,教程等描述了Q学习,所以在这里我不再赘述。 相反,我想展示使用tinymind如何高效地进行基于表的Q学习。 在本文中,我将描述tinymind如何使用C ++模板和定点( Q格式 )数字实现Q学习,并通过回购中的示例进行介绍。
迷宫问题 (The Maze Problem)
A common table-based Q-learning problem is to train a virtual mouse to find its way out of a maze to get the cheese (reward). Tinymind contains an example program which demonstrates how the Q-learning template library works.
基于表的常见Q学习问题是训练虚拟鼠标从迷宫中脱出以获取奶酪(奖励)。 Tinymind包含一个示例程序,该程序演示了Q学习模板库的工作方式。
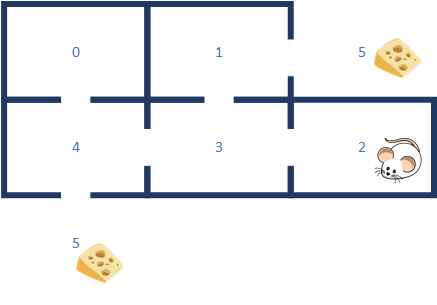
In the example program, we define the maze:
在示例程序中,我们定义迷宫:
/*
Q-Learning unit test. Learn the best path out of a simple maze.
5 == Outside the maze
________________________________________________
| | |
| | |
| 0 | 1 / 5
| | |
|____________/ ________|__/ __________________|_______________________
| | | |
| | / |
| 4 | 3 | 2 |
| / | |
|__/ __________________|_______________________|_______________________|
5
The paths out of the maze:0->4->5
0->4->3->1->5
1->5
1->3->4->5
2->3->1->5
2->3->4->5
3->1->5
3->4->5
4->5
4->3->1->5We define all of our types in a common header so that we can separate the maze learner code from the training and file management code. I have done this so that we can measure the amount of code and data required for the Q-learner alone. The common header defines the maze as well as the type required to hold states and actions:
我们在公共标头中定义所有类型,以便我们可以将迷宫学习者代码与培训和文件管理代码分开。 我这样做是为了使我们可以衡量仅Q学习器所需的代码和数据量。 通用头定义了迷宫以及保存状态和动作所需的类型:
// 6 rooms and 6 actions
#define NUMBER_OF_STATES 6
#define NUMBER_OF_ACTIONS 6typedef uint8_t state_t;
typedef uint8_t action_t;We train the mouse by dropping it into a randomly-selected room (or on the outside of it where the cheese is). The mouse starts off by taking a random action from a list of available actions at each step. The mouse receives a reward only when he finds the cheese (e.g. makes it to position 5 outside the maze). If the mouse is dropped into position 5, he has to learn to stay there and not wander back into the maze.
我们通过将鼠标放到随机选择的房间(或放在奶酪所在的外部)中来训练鼠标。 鼠标通过在每个步骤从可用动作列表中采取随机动作来开始。 仅当他找到奶酪时(例如,使其在迷宫外的位置5定位),鼠标才会获得奖励。 如果将鼠标放到位置5,则他必须学会留在位置5,而不能游回迷宫。
建立例子 (Building The Example)
Starting from cppnnml/examples/maze, I will create a directory to hold the executable file and build the example.
从cppnnml / examples / maze开始,我将创建一个目录来保存可执行文件并构建示例。
mkdir -p ~/maze
g++ -O3 -o ~/maze/maze maze.cpp mazelearner.cpp -I../../cppThis builds the maze leaner example program and places the executable file at ~/maze. We can now cd into the directory where the executable file was generated and run the example program.
这将构建迷宫式更精巧的示例程序,并将可执行文件放置在〜/ maze中。 现在我们可以cd到生成可执行文件的目录中,并运行示例程序。
cd ~/maze
./mazeWhen the program finishes running, you’ll see the last of the output messages, something like this:
程序完成运行后,您将看到最后一条输出消息,如下所示:
take action 5
*** starting in state 3 ***
take action 4
take action 5
*** starting in state 2 ***
take action 3
take action 2
take action 3
take action 4
take action 5
*** starting in state 3 ***
take action 4
take action 5
*** starting in state 5 ***
take action 5Your messages may be slightly different since we’re starting our mouse in a random room on every iteration. During example program execution, we save all mouse activity to files (maze_training.txt and maze_test.txt). Within the training file, the mouse takes random actions for the first 400 episodes and then the randomness is decreased from 100% random to 0% random for another 100 episodes. To see the first few training iterations you can do this:
您的消息可能会略有不同,因为每次迭代时我们都会在随机的房间内启动鼠标。 在示例程序执行期间,我们将所有鼠标活动保存到文件(maze_training.txt和maze_test.txt)中。 在训练文件中,鼠标在前400个情节中采取随机动作,然后对于其他100个情节,随机性从100%随机降低为0%随机。 要查看前几次训练迭代,可以执行以下操作:
head maze_training.txtYou should see something like this:
您应该会看到以下内容:
1,3,4,0,4,5,
4,5,
2,3,1,3,4,3,1,5,
5,5,
4,5,
1,5,
3,2,3,4,3,4,5,
0,4,0,4,0,4,0,4,5,
1,3,1,5,
5,4,0,4,3,1,3,1,5,Again, your messages will look slightly different. The first number is the start state and every comma-separated value after that is the random movement of the mouse from room to room. Example: In the first line above we started in room 1, then moved to 3, then 4, then 0, then back to 4, then to 5. Since 5 is our goal state, we stopped. The reason this looks so erratic is for the first 400 iterations of training we make a random decision from our possible actions. Once we get to state 5, we get our reward and stop.
同样,您的消息看起来会略有不同。 第一个数字是开始状态,之后的每个逗号分隔值是鼠标在不同房间之间的随机移动。 示例:在上面的第一行中,我们从1号房间开始,然后移至3号,然后是4号,然后是0号,然后又回到4号,然后是5号。由于5是我们的目标状态,因此我们停止了。 看起来如此古怪的原因是对于训练的前400次迭代,我们从可能的动作中做出随机决定。 一旦进入状态5,我们将获得奖励并停止。
During the test runs, we’ve decreased our randomness down to 0% and so we rely upon the Q-table to decide which action to take from the state our mouse is in.
在测试运行期间,我们已将随机性降低到0%,因此我们依靠Q表来决定从鼠标所处的状态采取哪种动作。
可视化培训和测试 (Visualizing Training And Testing)
I have included a Python script to plot the training and test data. If we plot the training data for start state == 2 (i.e. the mouse is dropped into room 2 at the beginning):
我包括一个Python脚本来绘制训练和测试数据。 如果我们绘制起始状态== 2的训练数据(即,鼠标首先放在房间2中):

Each line on the graph represents an episode where we’ve randomly placed the mouse into room 2 at the start of the episode. You can see that in the worst case run, we took 32 random moves to find the goal state (state 5). This is because at each step, we’re simply generating a random number to choose from the available actions (i.e. which room should be move to next). If we use the script to plot the testing data for start state == 2:
图中的每一行代表一个情节,在情节开始时我们将鼠标随机放置在2号房间中。 您可以看到,在最坏的情况下,我们随机进行了32次移动以找到目标状态(状态5)。 这是因为在每个步骤中,我们只是生成一个随机数以从可用操作中进行选择(即应将哪个房间移至下一个房间)。 如果我们使用脚本绘制开始状态== 2的测试数据:
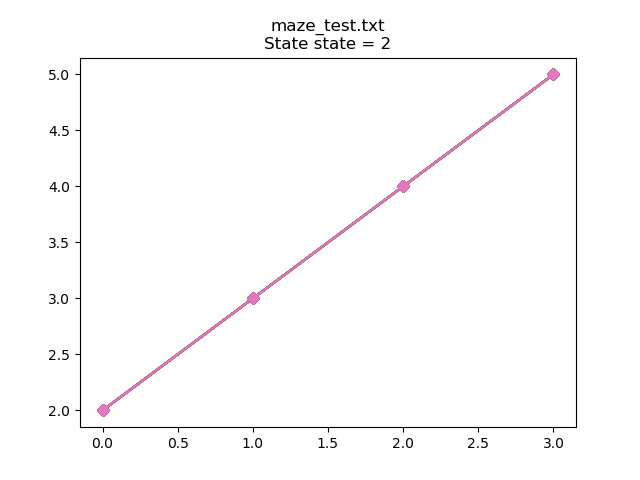
You can see that once trained, the Q-learner has learned, thru random experimentation, to follow an optimal path to the goal state: 2->3->4->5.
您可以看到,经过训练后,Q-学习者通过随机实验学会了遵循最佳状态进入目标状态的途径:2-> 3-> 4-> 5。
What happens when we drop the virtual mouse outside of the maze where the cheese is? If we plot the training data:
当我们将虚拟鼠标放到奶酪所在的迷宫之外时,会发生什么? 如果我们绘制训练数据:
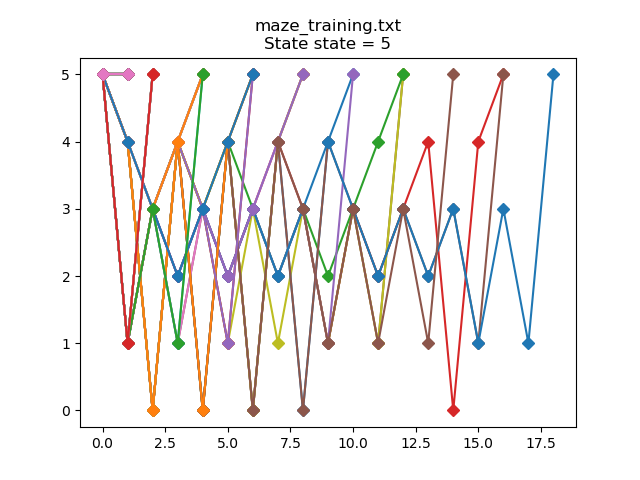
The mouse is making random decisions during training and so wanders back into the maze in most episodes. After training:
鼠标在训练过程中会做出随机决定,因此在大多数情节中都会游走回到迷宫中。 训练结束后:
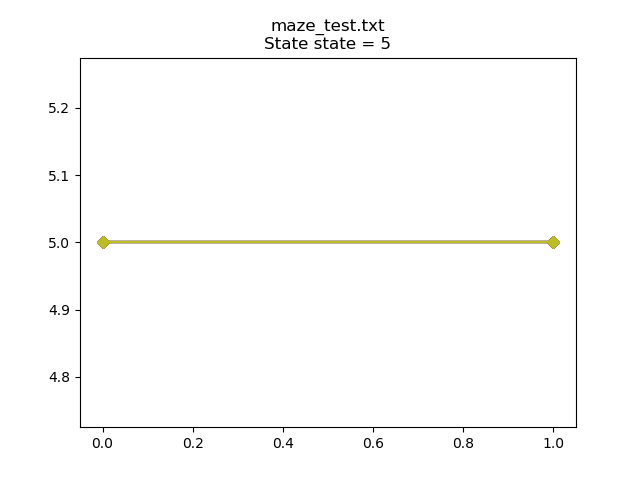
Our virtual mouse has learned to stay put and get the reward.
我们的虚拟鼠标学会了保持原状并获得奖励。
确定Q学习器的大小 (Determining The Size Of The Q-Learner)
We can determine how much code and data are taken up by the Q-learner by compiling just the machine learner code and using the size program:
通过仅编译机器学习者代码并使用size程序,我们可以确定Q学习者占用了多少代码和数据:
g++ -c mazelearner.cpp -O3 -I../../cpp && mv mazelearner.o ~/maze/.
cd ~/maze
size mazelearner.oThe output you should see is:
您应该看到的输出是:
text data bss dec hex filename
540 8 348 896 380 mazelearner.oThe total code + data footprint of the Q-learner is 896 bytes. This should allow a table-based Q-learning implementation to fit in any embedded system available today.
Q学习器的总代码+数据占用空间为896字节。 这应该允许基于表的Q学习实现适合当今可用的任何嵌入式系统。
结论 (Conclusion)
Table-based Q-learning can be done very efficiently using the capabilities provided within tinymind. We don’t need floating point or fancy interpreted programming languages. One can instantiate a Q-learner using C++ templates and fixed point numbers. Clone the repo and try the example for yourself!
使用tinymind提供的功能可以非常有效地完成基于表的Q学习。 我们不需要浮点或花哨的解释性编程语言。 可以使用C ++模板和定点数实例化Q学习器。 克隆仓库并亲自尝试示例!
翻译自: https://medium.com/swlh/table-based-q-learning-in-under-1kb-3cc0b5b54b43
基于kb的问答系统















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









