





语义分析 文本矛盾点解析
Yesterday I wrote about three course modules in Oslo, and the fact that most of the presentation material is online. Today I will be writing about one lesson in the curriculum about ‘Parsing’. First I will share a few general thoughts. Consider this in a format as learning notes, from this presentation.
昨天我在奥斯陆写了三个课程模块,而且大多数演示材料都在线。 今天,我将在“解析”课程中写一堂课。 首先,我将分享一些一般想法。 从此演示文稿中,将其视为学习笔记的格式。
In a discussion on Stackoverflow there were several interesting answers to this:
在关于Stackoverflow的讨论中,对此有几个有趣的答案:
“I’d explain parsing as the process of turning some kind of data into another kind of data. In practice, for me this is almost always turning a string, or binary data, into a data structure inside my Program. For example, turning:
“我将解析解释为将某种数据转换为另一种数据的过程。 实际上,对我而言,这几乎总是将字符串或二进制数据转换为程序内部的数据结构。 例如,转向:
":Nick!User@Host PRIVMSG #channel :Hello!"into (C)
进入(C)
struct irc_line {
char *nick;
char *user;
char *host;
char *command;
char **arguments;
char *message;
} sample = { "Nick", "User", "Host", "PRIVMSG", { "#channel" }, "Hello!" }“
“
Another user explained it as:
另一位用户解释为:
“Parsing is the process of analyzing text made of a sequence of tokens to determine its grammatical structure with respect to a given (more or less) formal grammar. The parser then builds a data structure based on the tokens. This data structure can then be used by a compiler, interpreter or translator to create an executable program or library.”
“解析 是分析由一系列标记组成的文本以确定相对于给定(或更少)形式语法的语法结构的过程。 然后,解析器基于令牌构建数据结构。 然后,编译器,解释器或翻译器可以使用此数据结构来创建可执行程序或库。”
Even providing a model:
甚至提供一个模型:
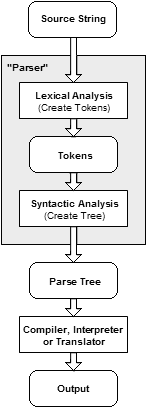
Slightly more complicated, but perhaps accurate:
稍微复杂一点,但也许准确:
“In computer science, parsing is the process of analysing text to determine if it belongs to a specific language or not (i.e. is syntactically valid for that language’s grammar). It is an informal name for the syntactic analysis process.”
“在计算机科学中,解析是分析文本以确定其是否属于特定语言(即, 对于该语言的语法在语法上有效 )的过程。 这是句法分析过程的非正式名称。”
The same user made an argument as to what is not:
同一用户对什么不是参数提出了争论:
Parsing is not transform one thing into another. Transforming A into B, is, in essence, what a compiler does. Compiling takes several steps, parsing is only one of them.
解析不是将一件事变成另一件事。 本质上,将A转换为B是编译器的工作。 编译需要几个步骤,解析只是其中之一。
Parsing is not extracting meaning from a text. That is semantic analysis, a step of the compiling process.
解析不是从文本中提取含义。 那就是语义分析 ,这是编译过程的一步。
On Wikipedia it is:
在Wikipedia上是:
“Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part (of speech).”
解析 , 语法分析或句法分析是按照自然语法,计算机语言或数据结构分析一串符号的过程,符合形式语法规则。 解析一词来自拉丁语pars ( orationis ),意思是(语音的一部分)。”
As a general explanation that works, we have several, however we might want to consider this more closely.
作为可行的一般解释,我们有几种解释,但是我们可能需要更仔细地考虑。
There is additionally a video accompanying this, although this video is in Norwegian.
尽管此视频是挪威语的 ,但还附带有一个视频。
依赖解析 (Dependency parsing)
There is a relationships between words, i.e., dependency relations.
单词之间存在关系,即依赖关系。
A dependency structure can be defined as a labeled, directed graph G.
依赖项结构可以定义为标记的有向图G。

The Principles outlined in the IN2110 presentation are as follows:
IN2110演示文稿中概述的原理如下:
“Syntactic structure is complete (Connectedness).
“句法结构完整( 连通性 )。
Syntactic structure is hierarchical (Acyclicity).
句法结构是分层的(非 循环性 )。
Every word has at most one syntactic head (Single-Head).”
每个单词最多具有一个语法头( Single-Head )。”
Connectedness can be enforced by adding a special root node (node 0).
可以通过添加特殊的根节点(节点0)来增强连接性。
树库:普遍依赖 (Treebanks: Universal Dependencies)
“Universal Dependencies (UD) is a framework for consistent annotation of grammar (parts of speech, morphological features, and syntactic dependencies) across different human languages. UD is an open community effort with over 300 contributors producing more than 150 treebanks in 90 languages. If you’re new to UD, you should start by reading the first part of the Short Introduction and then browsing the annotation guidelines.”
“ 通用依赖关系(UD) 是一个框架,用于在不同人类语言之间一致地注释语法(词性,词法特征和句法依赖关系)。 UD是一个开放的社区活动,有300多个贡献者以90种语言生成了150多个树库。 如果您不熟悉UD,则应先阅读简短介绍的第一部分,然后浏览注释准则。”

(程度)跨语言一致性 ((Degrees of) Cross-Linguistic Consistency)
On this topic there is an interesting paper that may be worth checking out from Google Research.
关于这个主题,有一篇有趣的论文可能值得从Google Research查阅。
Sentences across certain languages could all for example start with a big letter and end with punctuation.
例如,某些语言的句子都可以以一个大字母开头并以标点符号结尾。

回顾过去(90年代) (Back in the days (90s))
How were parsing different in the 1990's?
解析在1990年代有何不同?
- Parsers assigned linguistically detailed syntactic structures (based on linguistic theories). 解析器分配了详细的语言句法结构(基于语言理论)。
- Grammar-driven parsing: possible trees defined by the grammar. 语法驱动的解析:语法定义的可能树。
- Problems with coverage. 覆盖问题。
- Only around 70% of all sentences were assigned an analysis. 所有句子中只有大约70%被分配了分析。
- Most sentences were assigned very many analyses by a grammar and there is no way of choosing between them. 大多数句子都被一个语法分配了很多分析,并且没有办法在它们之间进行选择。
输入数据驱动的(统计)解析 (Enter data-driven (statistical) parsing)
Compared to this what is modern parsing like in 2020?
与此相比,2020年的现代解析是什么样的?
- Today data-driven/statistical parsing is available for a range of languages and syntactic frameworks. 如今,数据驱动/统计解析可用于多种语言和语法框架。
- Data-driven approaches: possible trees defined by the treebank (may also involve a grammar). 数据驱动的方法:由树库定义的可能的树(也可能涉及语法)。
- Produce one analysis (hopefully the most likely one) for any sentence and get most of them correct. 对任何句子进行一项分析(希望是最有可能的一项分析),并使其大部分正确。
- Still an active field of research, improvements are still possible. 仍然是一个活跃的研究领域,改进仍然是可能的。
Further to this what is data-driven dependency parsing?
除此之外,什么是数据驱动的依赖项解析?
Data-driven dependency parsing
数据驱动的依赖项解析
- M defined by formal conditions on dependency graphs (labeled directed graphs that are): I connected I acyclic I single-head I (projective) M由依存关系图(带标签的有向图)的形式条件定义:I连接I非循环I单头I(射影)
- I may be defined in different ways I parsing method (deterministic, non-deterministic) I machine learning algorithm, feature representations. 我可能以不同的方式定义我的解析方法(确定性,非确定性),机器学习算法,特征表示。
Two main approaches:
两种主要方法:
- Graph-based. 基于图。
Transition-based models.
基于过渡的模型。
The IN2110 lecture focus on transition-based approaches.
IN2110讲座重点介绍基于过渡的方法。
Transition-based approaches.
基于过渡的方法。
Basic idea: define a transition system for mapping a sentence to its dependency graph.
基本思想 :定义一个将句子映射到其依赖图的转换系统。
Learning: induce a model for predicting the next state transition, given the transition history.
学习 :根据给定的转换历史,得出一个用于预测下一个状态转换的模型。
Parsing: Construct the optimal transition sequence, given the induced model.
解析:给定诱导模型,构造最佳过渡序列 。
Shift-Reduce解析的改编。 (An Adaptation of Shift–Reduce Parsing.)
- Originally developed for non-ambiguous languages: deterministic. 最初是为非歧义语言开发的:确定性。
- Shift (‘read’) tokens from input buffer, one at a time, left-to-right; 从输入缓冲区从左到右一次移位(“读取”)令牌;
- Compare top n symbols on stack against rule RHS: reduce to LHS. 比较规则RHS堆栈上的前n个符号:简化为LHS。
- Dependencies: create arcs between top of stack and front of buffer. 相关性:在堆栈顶部和缓冲区前端之间创建弧。
Architecture: Stack and Buffer Configurations.
体系结构:堆栈和缓冲区配置。
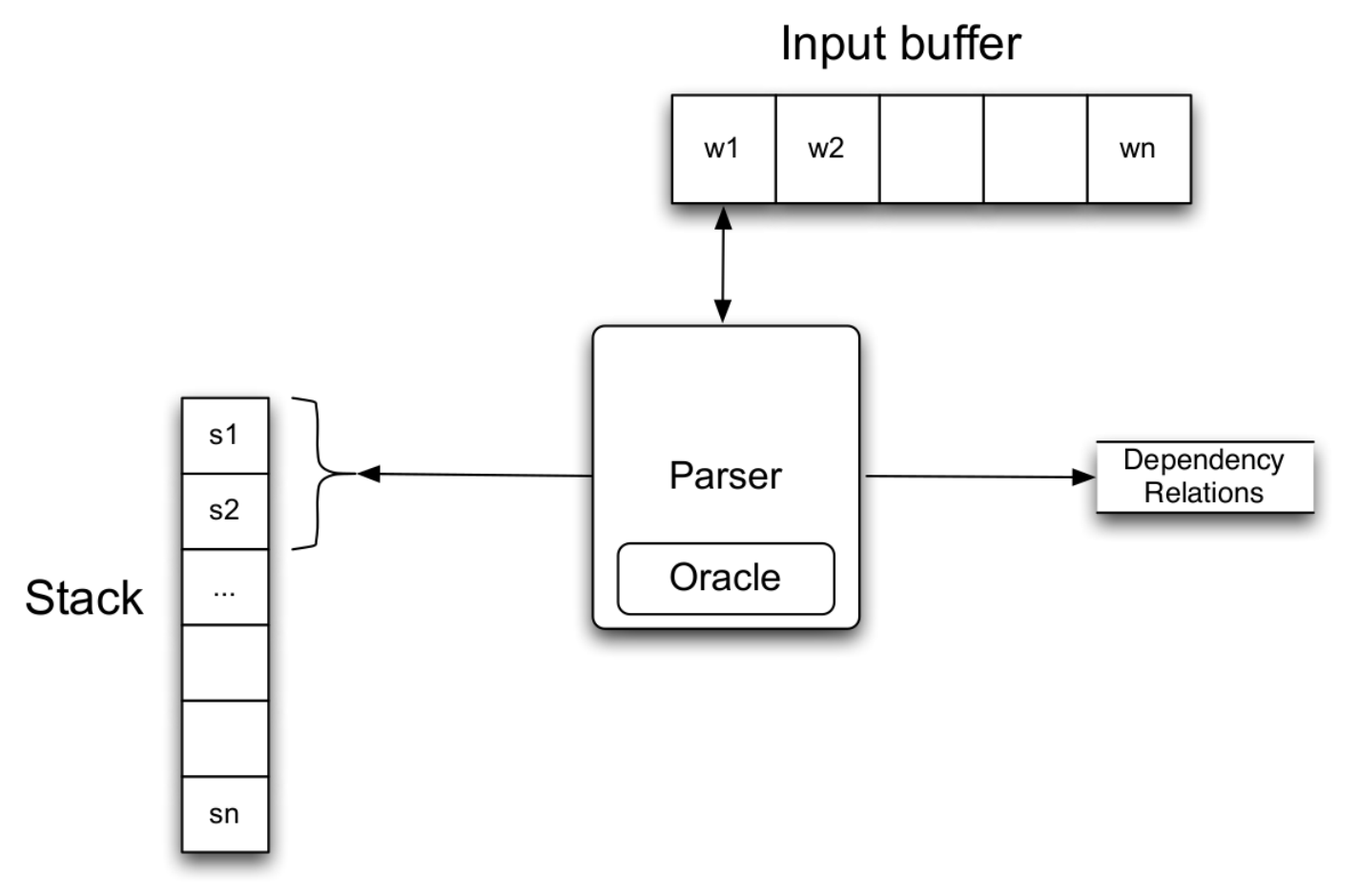
So within this workspace one has to navigate in parsing:
因此,在此工作空间中,必须进行解析:
- Transition system ensures formal wellformedness of dependency trees; 过渡系统确保依赖树的形式良好;
- The arc-eager system can generate all projective trees (and only those); 弧线渴望系统可以生成所有投射树(并且仅生成那些);
- A specific sequence of transitions determines the final parsing result. 特定的过渡顺序决定了最终的解析结果。
Towards a Parsing Algorithm:
迈向解析算法:
- Abstract goal: Find transition sequence that yields the ‘correct’ tree. 抽象目标:找到产生“正确”树的过渡序列。
- Learn from treebanks: output dependency tree with high probability. 向树库学习:高概率输出依赖树。
- Probability distributions over transitions sequences (rather than trees). 过渡序列(而不是树)上的概率分布。
架构摘要 (Architecture Summary)
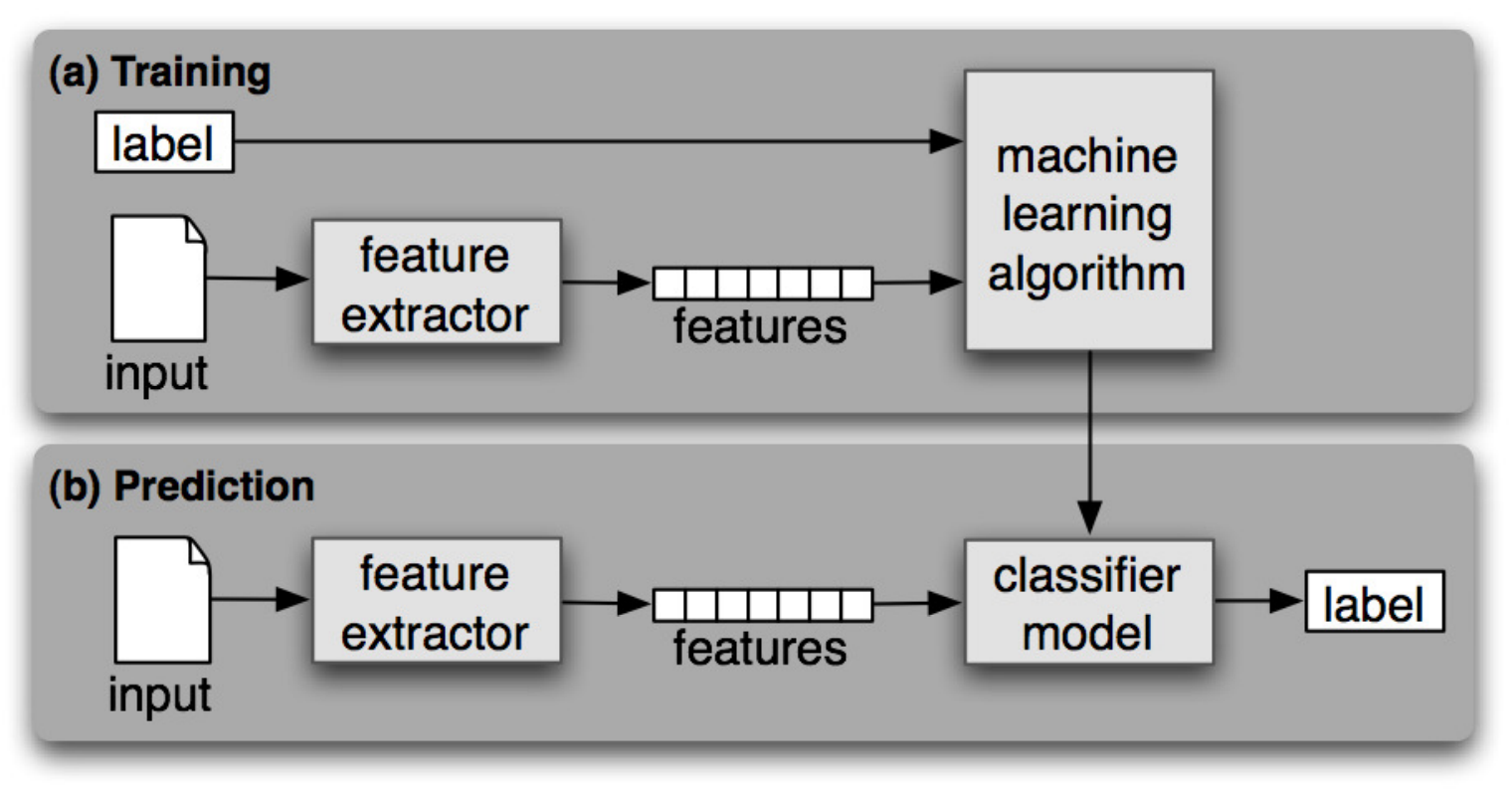
Data is labeled in the test set and attempted predictions are made.
在测试集中标记数据并进行尝试的预测。
数据驱动的依赖解析器 (Data-driven dependency parsers)
There are a number of freely available dependency parsers:
有许多免费的依赖项解析器:
- Pre-trained models and trainable for any language (given available training data) 预先训练的模型并且可以针对任何语言进行训练(如果有可用的训练数据)
- Stanford CoreNLP (English) 斯坦福大学CoreNLP(英语)
- SpaCy (A number of languages) SpaCy(多种语言)
- Google SyntaxNet I UDParse I etc. Google SyntaxNet I UDParse I等
There does however need to be evaluation.
但是,确实需要进行评估。
I wrote about this previously in regards to how it might need to change in NLP:
之前我就如何更改NLP中的内容写过文章:
However, the status is that currently the metrics are often what counts.
但是,目前的状态是通常很重要的指标。
UAS: Unlabeled Attachment Score I For each token, does it have correct head (source of incoming edge)?
UAS :未标记的附着分数I对于每个令牌,它是否具有正确的头(传入边缘的来源)?
LAS: Labeled Attachment Score I In addition to the head, is the dependency type (edge label) correct?
LAS :带标签的附件分数I除头部之外,依存关系类型(边缘标签)是否正确?
结论 (In Conclusion)
Data-Driven Dependency Parsing:
数据驱动的依赖关系解析:
- No notion of grammaticality (no rules): more or less probable trees. 没有语法概念(没有规则):或多或少的可能树。
- Much room for experimentation: Feature models and types of classifiers. 有很大的实验空间:特征模型和分类器类型。
- Decent results with Maximum Entropy or Support Vector Machines. 使用最大熵或支持向量机可获得不错的结果。
- In recent years, further advances with deep neural network classifiers. 近年来,深度神经网络分类器取得了进一步的进步。
Variants on Data-Driven Dependency Parsing:
数据驱动的依赖项解析的变体:
- Other transition systems (e.g. arc-standard; like ‘classic’ shift-reduce). 其他过渡系统(例如,弧形标准;例如“经典”移位减少)。
- Different techniques for non-projective trees; e.g. swap transitions. 非投影树的不同技术; 例如交换过渡。
- Can relax transition system further, to output general, non-tree graphs. 可以进一步放松过渡系统,以输出一般的非树图。
- Beam search: exploring the top-n transitions out of each configuration. 光束搜索:探索每种配置的前n个过渡。
I currently need to work with a corpus of documents and thought it was interesting to consider parsing as a problem.
我目前需要处理大量文档,并且认为将解析视为问题很有趣。
This is #500daysofAI and you are reading article 433. I am writing one new article about or related to artificial intelligence every day for 500 days.
这是#500daysofAI,您正在阅读文章433。我连续500天每天都在撰写一篇有关人工智能或与人工智能有关的新文章。
翻译自: https://medium.com/swlh/a-few-thoughts-on-parsing-text-b496a0f99dde
语义分析 文本矛盾点解析















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









