





 本文分析了一对情侣间的WhatsApp消息,揭示了他们的沟通模式、常用词汇和表情符号,以及消息发送的时间分布,展示了如何使用Python和数据科学方法洞察人际关系。
本文分析了一对情侣间的WhatsApp消息,揭示了他们的沟通模式、常用词汇和表情符号,以及消息发送的时间分布,展示了如何使用Python和数据科学方法洞察人际关系。
Communication in a relationship is key, so they say. Without communication, any relationship is as good as dead. In this era and age, technology as taken the center stage as far as communication is concerned. In this article, we will analyze WhatsApp messages between my fiance and I and at the end of the day you can apply the knowledge on your on WhatsApp data. We will use Python in this analysis and specifically deal with: Pandas Tables, Data Visualization, Data Cleaning and much more.
他们说,关系中的沟通是关键。 没有沟通,任何关系都好不容易了。 在这个时代,就通讯而言,技术已成为焦点。 在本文中,我们将分析未婚夫与我之间的WhatsApp消息,最终您可以将知识应用到WhatsApp数据上。 在此分析中,我们将使用Python并专门处理以下内容:熊猫表,数据可视化,数据清理等等。
Before we go through this I will like to mention that we have been in this relation for a year and half now and the chats available are from Dec, 18 2019 to Aug 10, 2020 (236 days or 7 months, 23 days). In between this period I traveled out of my home country and I left her back home. We are natively Kenyans but I am currently in South Africa.
在我们进行此操作之前,我想提到我们已经有一年半的关系了,可用的聊天时间是2019年12月18日至2020年8月10日(236天或7个月23天)。 在此期间,我出了家乡,离开了她的家。 我们是肯尼亚人,但我目前在南非。
Lets now go ahead to analyze the data. I will like us to go through this in steps so that it is clear to you.
现在让我们继续分析数据。 我希望我们逐步进行此操作,以便您清楚地看到。
步骤1:获取WhatsApp数据 (Step 1 : Getting the WhatsApp Data)
WhatsApp allows user to download the entire chat history into a text file. To do that open the conversation you are interested to get the data for. On the top right corner click the 3 dots > More > Export chat > WITHOUT MEDIA. After that a text file will download and it will contain all the messages in the conversion from the start to the end. For the sake of clarity, I saved mine as whatsapp.txt .
WhatsApp允许用户将整个聊天记录下载到文本文件中。 为此,请打开您感兴趣的对话以获取数据。 在右上角单击3个点>更多>导出聊天>无媒体 。 之后,将下载一个文本文件,它将包含转换中从头到尾的所有消息。 为了清楚起见,我将我的文件另存为whatsapp.txt 。
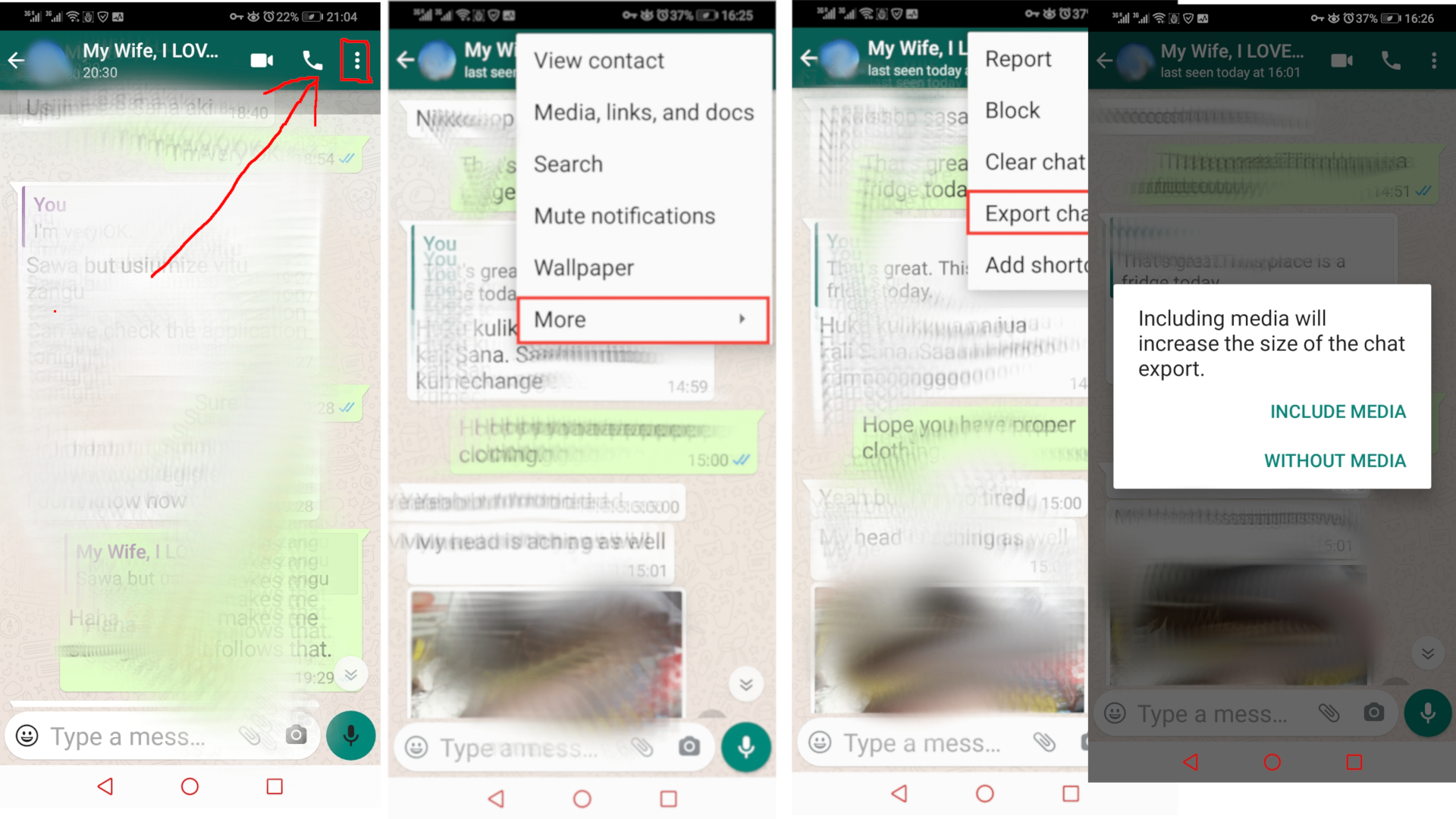
第2步:查看数据 (Step 2 : A Look at the Data)
On opening the file whatsapp.txt you are greeted with such a file
打开文件whatsapp.txt您会收到这样的文件

Line 1: This is a message by WhatsApp ensuring you that the messages are end-to-end encrypted. This is a special case and we will skip it in the analysis.
第1行:这是WhatsApp发出的一条消息,确保您已对消息进行端到端加密。 这是一种特殊情况,我们将在分析中将其跳过。
Line 2 through 5: Typically, every line represents a single message from the sender. It will contain the date, time, sender and then the message.
第2至5行:通常,每行代表发件人发送的一条消息。 它将包含日期,时间,发件人 ,然后是消息 。
Note: There are two senders (my fiance and I). I saved my fiance’s name as My Wife, I LOVE YOU ❤ and my WhatsApp username is koech christian.
注意 :有两个发件人(我的未婚夫和我)。 我将未婚夫的名字保存为我的妻子,我爱你❤ ,我的WhatsApp用户名是koech christian 。
第3步:处理数据并将其保存为CSV (Step 3: Processing Data and Saving it into CSV)
For every single line, we need to extract the date and time the message was sent, the sender and the message itself.
对于每一行,我们都需要提取消息的发送日期和时间,发件人和消息本身。
Line 2 : This is an empty list to hold our data.
第2行:这是保存数据的空列表。
Line 3 and 4: Here, we are reading our file in read mode (r) and loop through each line at a time.
第3和4行 :在这里,我们以读取模式(r)读取文件,并一次遍历每一行。
To understand lines 6–8, let us take one of our lines as an example:
为了理解第6-8行 ,让我们以其中一行作为示例:
line = 12/18/19, 08:15 - koech christian: Have woken up my dear.In 6, we will strip the line of trailing white spaces and split the line by the hyphen (-)Result:
12/18/19, 08:15 #send_time
koech christian: Have woken up my dear. #message_sectionNote: send_time still has both the date and the time while message_section has the sender and the message.Code line 7: We will split the content of message_section by the first occurrence of a full colon (:) hence maxsplit = 1. If we don't do this split function may split at the middle of the message in case a sender uses a full colon.You now know what 8 does.Line 9 through 15: We pass our values of interest into a dictionary followed by appending it into data.
第9至15行 :我们将感兴趣的值传递到字典中,然后将其附加到数据中。
Line 19 and 20: Write data into a CSV file called
messages.csv.第19和20行 :将数据写入一个名为
messages.csv的CSV文件。Exceptions raised by line 1 will be handle by
try...except...第1行引发的异常将通过
try...except...处理try...except...
第4步:查看CSV文件 (Step 4 : A Look at the CSV file)
Lets load the CSV file (messages.csv) we saved in Step 3 and have a look at how a few lines look like.
让我们加载在第3步中保存的CSV文件( messages.csv ),然后看几行。
Output:
输出:
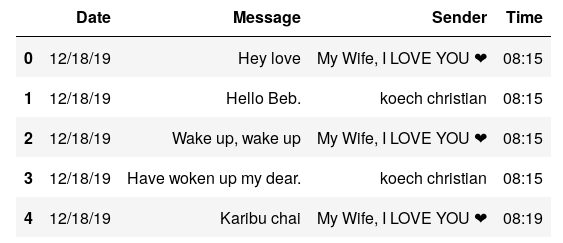
The next thing is to analyze the data but before that I just want to make my guesses and probably what I expect. First, I know it is silly, but I punctuate the end of my sentences and she doesn’t LoL!. She sleeps so early even without saying good night so I bet I will be ending the conversation most days on any given day. She also wakes up earlier than I do and I will expect that she will be starting most of the “good morning” messages.
接下来的事情是分析数据,但在此之前,我只想做出自己的猜测以及可能的期望。 首先,我知道这很愚蠢,但是我在句子结尾打了个小标点,而她却不满意! 即使不说晚安,她也睡得这么早,所以我敢打赌,在任何一天的大部分时间里,我都会结束对话。 她还比我早起床,我希望她会开始大多数“早安”信息。
When we are back in Kenya she rarely chats on WhatsApp with me. This means that the number of messages before I traveled to South Africa (days before Feb 2, 2020) will surely be fewer than the messages we send to each other when I am here.
当我们回到肯尼亚时,她很少和我聊天。 这意味着在我前往南非之前(2020年2月2日之前的几天),邮件的数量肯定会少于我在这里时向彼此发送的邮件的数量。
步骤5:数据分析 (Step 5: Analysis of Data)
In the analysis of the data we will use the Pandas library for descriptive statistics and Pyplot module in Matplotlib to visualize the results of our analysis.
在数据分析中,我们将使用Pandas库进行描述性统计,并使用Matplotlib中的Pyplot模块来可视化我们的分析结果。
Lets dive in!
让我们潜入!
活动日 (Active days)
Out of 236 days for which we have the data, how many days did we actually exchanged WhatsApp messages?
在我们拥有数据的236天中,我们实际上交换了WhatsApp消息多少天?
Output:
输出:
Active days: 222
First Day: 2019-12-18
Last Day: 2020-08-10
Difference of Dates: 236Again let us go through what the code is actually doing
再次让我们看一下代码的实际作用
Line 1: Convert date string into Python datetime object.
第1行 :将日期字符串转换为Python datetime对象。
Line 3 and 4 : Determine the number of active days by simply counting the number of unique values in the Date column.
第3行和第4行 :通过简单地计算“ 日期”列中唯一值的数量来确定活动天数。
Line 6 through 10: Get the first and last day for the chat history. The messages contained in the conversation are from Dec 18, 2019 through Aug 8, 2020.
第6行到第10行 :获取聊天记录的第一天和最后一天。 对话中包含的消息是从2019年12月18日到2020年8月8日。
Line 12–15: Get the difference between the first and the last date determined in 6–10.
第12-15行 :获取6-10中确定的第一个日期和最后一个日期之间的差。
From here, we can see that we have chatted on WhatsApp 222 of 236 days (94% of the time). In fact, the 14 days which makes the difference exist by choice. We used another medium of communication (when I was back in Kenya). For the time I have been in South Africa, we have 100% active days. We will discover that in a moment.
从这里,我们可以看到我们在236天 (94%的时间)的WhatsApp 222上进行了聊天。 实际上,有区别的14天可以选择存在。 我们使用了另一种沟通方式(当我回到肯尼亚时)。 在我去南非的时候,我们有100%的活跃日。 稍后我们将发现。
谁收到的信息最多? (Who has the most messages?)
I guess I am the one with the most messages but the difference won’t be big. Lets see.
我想我是消息最多的人,但差别不会很大。 让我们来看看。
Output:
输出:
Total Messages: 34491
My Wife, I LOVE YOU ❤ 18030
koech christian 16461
Oops! 34491 messages in total and she wrote the most of the messages. She got to hear this.
糟糕! 她总共写了34491条消息,其中大部分是她写的。 她听到了。
第一条和最后一条消息(一天的开始和结束) (First and Last Messages (Start and End of the Day))
As I said, I am sure about this: she will mostly start the day and I will mostly close the day. That lady always sleep before even saying good night and always apologizes in the morning.
就像我说的,我对此很确定:她将主要开始新的一天,而我将主要结束一天。 那位女士总是在睡觉之前甚至不说晚安,并总是在早上道歉。
Morning and Night Messaging (Line 1–7)
早晚消息(第1-7行)
Line 2: In this line we sort the DataFrame by Date and Time so that we bring the the first day message on top of the day chat. We also drop duplicates so that we remain with the earliest message on the DataFrame on every given day. Lastly, we count the early messages per Sender.
第2行 :在这一行中,我们按日期和时间对DataFrame进行排序,以便将第一天的消息置于当天聊天的顶部。 我们还会删除重复项,以便在每一给定的日期将最早的消息保留在DataFrame中。 最后,我们计算每个发件人的早期消息。
- Line 3: Output (Morning messaging) 第三行:输出(早晨消息)
My Wife, I LOVE YOU ❤ 157
koech christian 63- Line 11: Output (Last messages of the day) 第11行:输出(当天的最后一条消息)
koech christian 156
My Wife, I LOVE YOU ❤ 64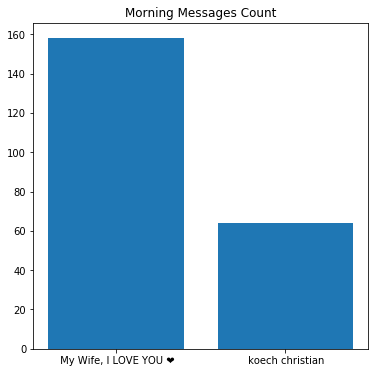

Amazing discovery! It is true that she writes the first message most days and I do write the last message most nights. What is even surprising is how symmetric they are. It is as if we are doing our “morning runs” and “night runs” equally.
惊人的发现! 的确,她大部分时间都写第一条消息,而我多数晚上才写最后的消息。 甚至令人惊讶的是它们的对称性。 好像我们在平等地进行“早晨跑步”和“夜间跑步”。
Since we started this relationship till now, I have never understood why she always sleep without saying good night. I was so uncomfortable at the start but I finally accepted her for who she is at that level.
自从我们开始这段恋情以来,我一直不明白为什么她总是不说晚安就睡觉。 一开始我很不舒服,但是我终于接受了她,因为她在那个级别。
每天随时间变化的消息数 (Number of Messages per Day over Time)
Well, for this one I know what to expect but I don’t know how an ideal relationship should be. Should the rate of messaging deteriorate as the relationship becomes grounded or deterioration suggest a failing relationship? I don’t know but for me I think there are some factors playing. First of all, I have been working on reducing my phone addiction. This could be a cause to declining trend.
好吧,对于这个,我知道会发生什么,但我不知道理想的关系应该如何。 随着关系的建立,消息传递的速率是否应该恶化,或者恶化表明关系失败? 我不知道,但对我来说,我认为有一些因素在起作用。 首先,我一直在努力减少手机成瘾。 这可能是趋势下降的原因。
I also expect few message when I am home (Kenya) and more messages here (South Africa) because WhatsApp is the main channel of communication now.
我还希望自己在家(肯尼亚)时收到很少的消息,而在这里(南非)则收到更多消息,因为WhatsApp现在是主要的沟通渠道。
Lets see.
让我们来看看。

It looks like my predictions were right. A rise in number of messages per day since I traveled and continued decline. To really understand this, lets plot a trend line on the plot above and also a vertical line for the day I traveled out of my home country.
看来我的预测是正确的。 自从我旅行以来,每天的邮件数量增加,并且持续下降。 为了真正理解这一点,让我们在上面的图上绘制一条趋势线,并在我出国旅行的那天绘制一条垂直线。
趋势平滑 (Trend Smoothing)
There are so many methods for developing smooth trend lines. These methods includes resampling and rolling windows.
建立平滑趋势线的方法有很多。 这些方法包括重新采样和滚动窗口。
Resampling
重采样
It is often useful to resample time series data to a lower or higher frequency. Resampling to a lower frequency (downsampling) usually involves an aggregation operation — for example, computing total monthly messages from daily count.
将时间序列数据重新采样到较低或较高的频率通常很有用。 重采样到较低的频率( 下采样 )通常涉及聚合操作-例如,从每日计数中计算每月的总消息量。
Resampling to a higher frequency (upsampling) is less common and often involves interpolation or other data filling method — for example, interpolating daily data into hourly intervals for input to a model.
重采样到较高频率( 上采样 )的情况比较少见,并且通常涉及插值或其他数据填充方法,例如,将每日数据插值到小时间隔中以输入模型。
Pandas resample() method, which splits the data index into time bins and groups the data by time bin. The resample() method returns a Resampler object, similar to a pandas group-by() function. Aggregation method such as mean(), median(), sum(), etc., can then be applied to the data group for each time bin.
Pandas resample()方法将数据索引分为多个时间段,并按时间段对数据进行分组。 resample()方法返回一个Resampler对象,类似于pandas group-by()函数。 然后可以将诸如mean() , median() , sum()等聚合方法应用于每个时间段的数据组。
Rolling windows
卷帘窗
Rolling window operations are another important transformation for time series data. Similar to downsampling, rolling windows split the data into time windows and and the data in each window is aggregated with a function such as mean(), median(), sum(), etc. However, unlike downsampling, where the time bins do not overlap and the output is at a lower frequency than the input, rolling windows overlap and “roll” along at the same frequency as the data, so the transformed time series is at the same frequency as the original time series.
滚动窗口操作是时间序列数据的另一个重要转换。 与下采样类似,滚动窗口将数据拆分为时间窗口,并且每个窗口中的数据都使用诸如mean() , mean() median() , sum()等函数进行聚合。但是,与下采样不同,时间段不会重叠,并且输出的频率低于输入的频率,滚动窗口会以与数据相同的频率重叠并“滚动”,因此转换后的时间序列与原始时间序列的频率相同。
For our data, we will use the rolling windows to fit the trend line
对于我们的数据,我们将使用滚动窗口来拟合趋势线
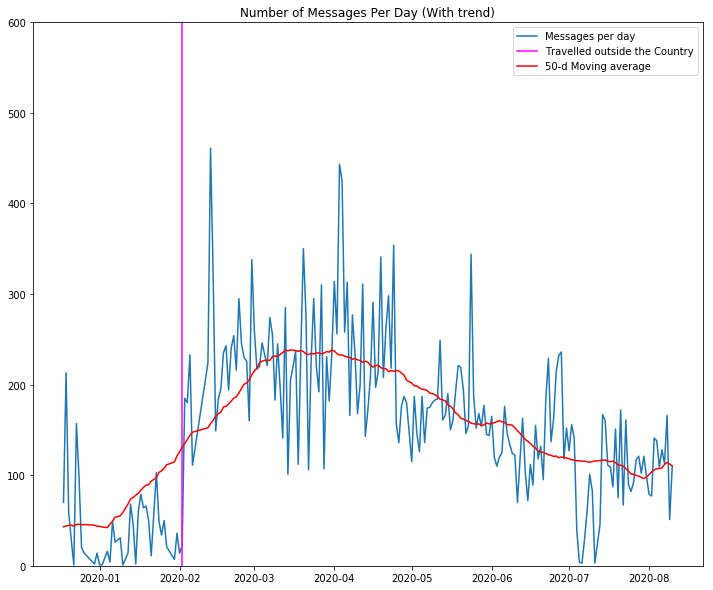
From the above Figure, we can see that the trend line (with a window size of 50 days) actually matches our prediction. Before I traveled (left of magenta vertical line), we used WhatsApp less often than after my travel (right hand side). It is also clear that the number of messages per day is declining over time.
从上图可以看出,趋势线(窗口大小为50天)实际上与我们的预测相符。 在旅行之前(洋红色垂直线的左侧),我们使用WhatsApp的频率比旅行之后(右侧)的使用频率低。 同样很明显,每天的消息数量随着时间的推移而下降。
一天中最大和最小数量的邮件 (The Largest and Smallest Number of Messages in a Day)
Largest: 461 messages in a day. Date: 2020–02–13
最大:一天中有461条消息。 日期:2020-02-13
Smallest: 1 message a day. Dates: 2019–12–22, 2020–01–01 among others
最小:每天1条消息。 日期:2019–12–22、2020–01–01等
实际词句分析 (Analysis of Actual Words and Sentences)
It could be very interest if we get to know the common words/emojis used by each of us. In this section we are doing exactly that.
如果我们了解我们每个人使用的常用单词/表情符号,可能会非常感兴趣。 在本节中,我们正是这样做的。
Total Number of Words Per Sender
每个发送者的单词总数
In this section, we will count all the words for all messages per sender (note that we are skipping some filler words like a, and, & the as shown in line 10 and 16 below)
在本节中,我们将所有计数为每发送方的所有消息的话(注意,我们跳过像一些填充词a , and ,与the中所示线10和16的下方)
Output:
输出:
Number of words(Myself): 105612
Number of words(mylove): 113716Again! She wins here!.
再次! 她在这里赢了!
Lets go through above code snippet so that you understand what it does.
让我们看一下上面的代码片段,以便您了解它的作用。
If…else… statement in line 6 and 12 is used to condition the filter on the Sender.
第6和12行中的if ... else ...语句用于在发送方上调节过滤器。
Line 8 and 14 ideally does the same thing. Lets see an example.
理想情况下,第8行和第14行执行相同的操作。 让我们来看一个例子。
message = "Okay. Bye for now 💕💕💕💕"word_list = message.strip().lower().translate(str.maketrans('', '', string.punctuation)).split(" ")print(word_list)Result: ['okay', 'bye', 'for', 'now', '💕💕💕💕']In this portion of code, we strip the message of trailing white spaces, change words to lower cases, strip message of punctuation marks (note that period was stripped) and lastly split the the message by white space so that we have a list of words.
在这部分代码中,我们将带尾空格的消息剥离 ,将单词更改为小写 字母 , 剥离标点符号的消息 (请注意句点已被剥离),最后将消息按空格分隔 ,从而得到一个单词列表。
What are the Most Common Words? What are the Unique Words Used Over Time?
最常用的词是什么? 随着时间的流逝,独特的单词是什么?
Counter module from collections library makes things simple for us. In line 4 and 5 we take the count of words. The result is a list of word-count tuple pairs, for example,
collections库中的Counter模块对我们来说很简单。 在第4行和第5行中,我们计算单词数。 结果是一个单词计数元组对的列表,例如,
text = "dog is a pet, hen is a bird"result = Counter(text.split()).most_common()print(result)[('is', 2), ('a', 2), ('dog', 1), ('pet,', 1), ('hen', 1), ('bird', 1)]From here, determining the number of unique words can be done by simply getting the length of the resulting list (Line 7–9).
从这里开始,只需获得结果列表的长度即可确定唯一单词的数量( 第7-9行 )。
Output of Line 7–9:
7-9行的输出:
Unique words used:
Unique words She used: 8783
Unique words I used: 7281Again, she wins. I don’t know if this is a good measure of intelligence but I believe she is the smarter one. No wonder!
她又赢了。 我不知道这是否可以很好地衡量智力,但我相信她是比较聪明的人。 难怪!
Next, we want to get the most common used words
接下来,我们要获得最常用的单词
Note that we already have the most common words in the two variables most_common_me and most_common_her . In the following code snippet we will just pick the top 10.
请注意,在两个变量most_common_me和most_common_her ,我们已经有了最常用的词。 在下面的代码片段中,我们将选择前十名。
Once we have the list of most common words and the counts we can now have them on a Pandas DataFrame and also make some bar plots to visualize this as below
一旦我们有了最常用的单词和计数的列表,我们现在就可以将它们放在Pandas DataFrame上,并绘制一些条形图以使其可视化,如下所示
Results:
结果:

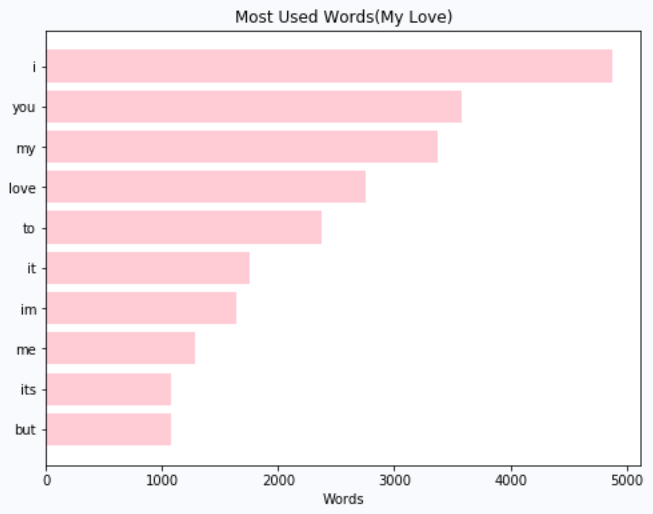
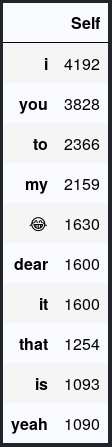
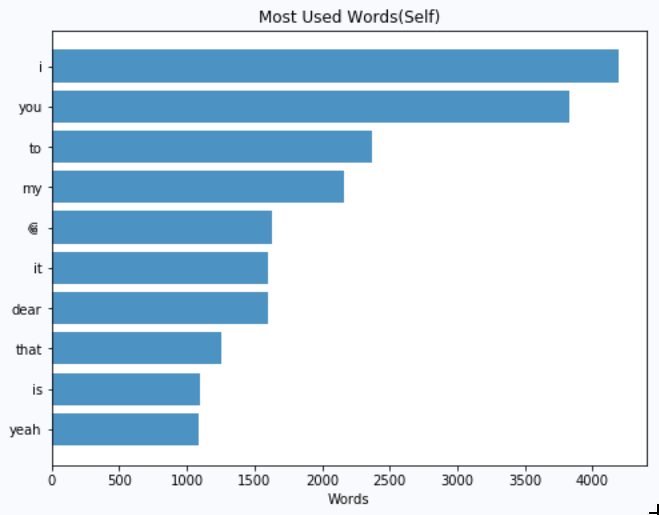
Honestly, data don’t lie. From her stats, I am not surprised that I, you, my and love are on top of the list. She uses them a lot and I always don’t get surprised when she writes a message like “I love you my love” LoL!. On the other hand, all I know best is how to laugh. No wonder 😂 is on top of top 10. But trust me I don’t use a whole lot of emojis I probably know only two emojis: 😂 and 🙈.
老实说,数据不会说谎。 从她的统计数据来看, I, you, my和love都位居榜首,我并不感到惊讶。 她经常使用它们,当她写“ 我爱你我的爱人 ”这样的消息时,我总是不会感到惊讶。 另一方面,我最清楚的是如何笑。 难怪😂在前十名中排名最高。但是请相信我,我不会使用很多表情符号,我可能只知道两个表情符号:em和🙈。
In fact, let as go ahead and analyze emoji usage.
实际上,让我们继续分析表情符号用法。
表情符号爱 (Emoji Love)
Emojis are mostly used to express emotions and just a way to spice up communication. Lets dive in into the analysis
表情符号主要用于表达情感,并且只是增加交流的一种方式。 让我们深入分析
Line 1–4: we are using
emojipackage to extract emojis from sentences with the aid of the functionextract_emojis, for example,第1至4行 :我们使用
emoji包,借助extract_emojis函数从句子中提取emoji,例如,
extract_emojis("K😂ip 😆rono🤣 El😂ij😁 😆ah")result: '😂😆🤣😂😁😆'Line 6–24: Loop through all the messages and extracting all the emojis into lists with respect to sender.
第6-24行 :遍历所有消息并将所有表情符号提取到与发件人相关的列表中。
Output:
输出:
Most Common emojis used (Me)
('😂', 1652)
('🙈', 270)
('😍', 85)
('😘', 52)
('😋', 45)
Most Common emojis used (Her)
('😂', 1577)
('♀', 132)
('🤦', 120)
('😘', 81)
('😔', 67)Plots:
情节:
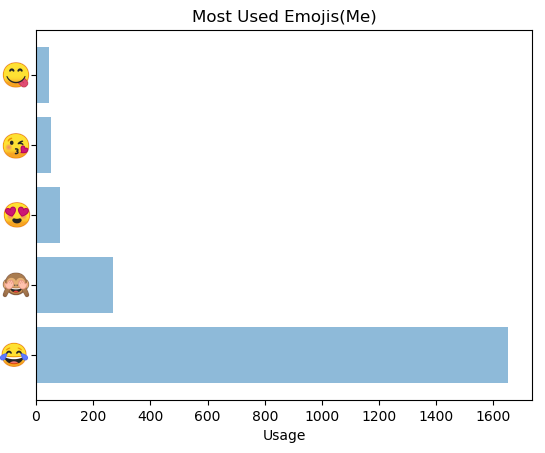
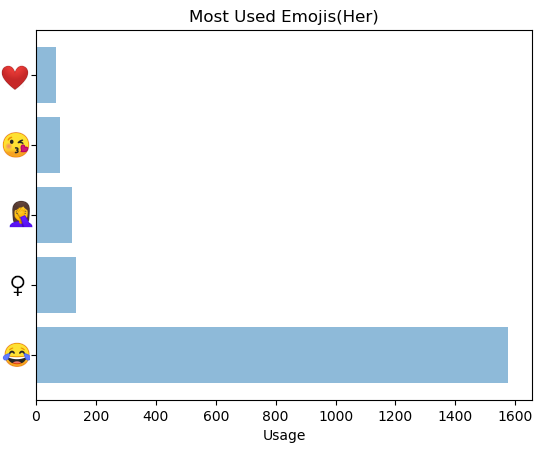
The most laughing family we are. Both of us use 😂 the most but of course I still use more than her.
我们是最笑的家庭。 我们俩都使用most最多,但是我仍然比她使用更多。
时间和活动分析 (Time and Activity Analysis)
It is also interesting to know distribution of chats over time.
了解聊天随时间的分布也很有趣。
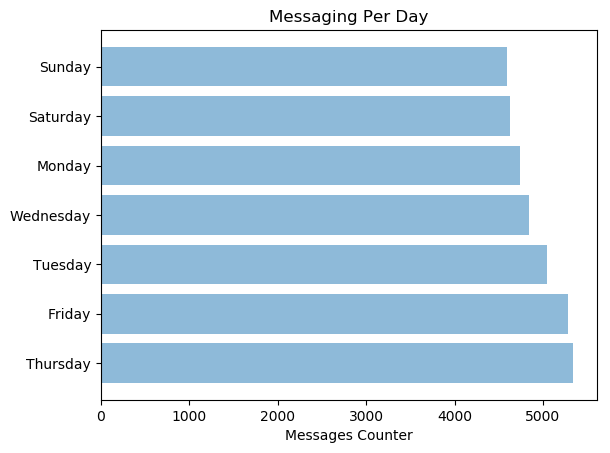
We do talk mostly on Thursdays and Fridays but there’s no much of a difference really.
我们主要在周四和周五讲话,但实际上并没有太大的区别。
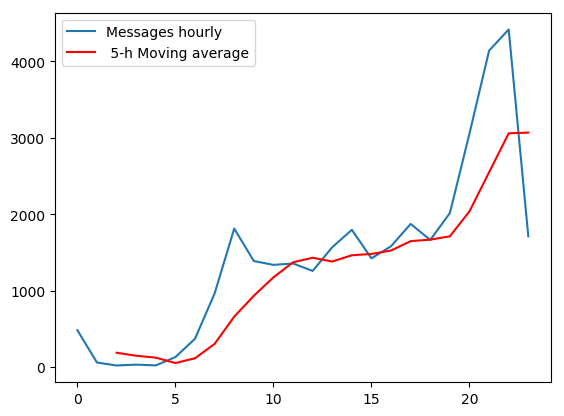
The Figure above shows the distribution of chat over a day on average. Most days between 0000H and 0500H both of us are asleep and therefore there is no much activity. Chatting gradually increases and reaches the pick between 2000H and 2100H before it also declines very fast as we go to back to sleep.
上图显示了平均一天中聊天的分布。 我们俩都在0000H到0500H之间的大多数日子都处于睡眠状态,因此没有太多活动。 聊天逐渐增加并达到2000H和2100H之间的水平,然后随着我们回到睡眠状态,聊天速度也很快下降。
The last analysis I did was to determine the longest messages we have ever written,
我做的最后一次分析是确定我们写过的最长的消息,
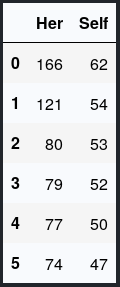
Again, she leads on this with her own longest message containing 166 words while I only have 62.
同样,她以自己的最长信息(包含166个单词)而领先于此,而我只有62个单词。
结论 (Conclusion)
In this article, I hope you had fun and also learned along the way. We cleaned, described and visualized data using pandas and by doing so you may make adjustments to make your relationship better or more generally understand string manipulation even better.
在本文中,希望您玩得开心,并从中学到东西。 我们使用熊猫来清理,描述和可视化数据,这样您就可以进行调整以使您的关系更好,或更全面地理解字符串操作。
You can replicate the same using your own WhatsApp data by following the same steps.
您可以按照相同的步骤使用自己的WhatsApp数据复制相同的内容。
As always, thanks for reading :-)
一如既往,感谢您的阅读:-)
翻译自: https://towardsdatascience.com/7-months-of-a-relationship-whatsapp-messages-analyzed-e5c34b8aaa63

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









