





airflow使用
Ok, here’s a scenario: You’re the lone data scientist/ML Engineer in your consumer-focused unicorn startup, and you have to build a bunch of models for a variety of different business use cases. You don’t have time to sit around and sulk about the nitty-gritty details of any one model. So you’ve got choices to make. Decisions. Decisions that make you move fast, learn faster, and yet build for resilience all while gaining a unique appreciation for walking the talk. IF you do this right (even partly), you end up becoming walking gold for your company. A unicorn at a unicorn 😃. Why? Because, you put the customer feedback you observed through their data-trail back to work for your company, instead of letting it rot in the dark rooms of untapped logs and data dungeons (a.k.a. databases). These micro-decisions you enable matter. They eventually add up to push your company beyond the inflection point that is needed for exponential growth.
ØK,这里有一个场景 :你在你的消费者为中心的麒麟启动孤独的数据科学家/ ML工程师,你必须建立一堆模型,各种不同的业务用例。 您没有时间闲逛并为任何一个模型的实质细节details之以鼻。 这样您就可以做出选择了。 决定。 决策使您能够快速行动,更快地学习,并为恢复能力而努力,同时获得了对演讲的独特赞赏。 如果您正确(甚至部分地)做到这一点,您最终将成为贵公司的黄金。 独角兽中的独角兽😃。 为什么? 因为,您将通过数据线索观察到的客户反馈重新投入到为公司工作中,而不是让它在未使用的日志和数据副本(也称为数据库)的暗室中腐烂。 这些使您事半功倍的决定。 他们最终加起来,使您的公司超越了指数式增长所需的拐点。
So, that is where we start from. And build. We’ll assume we can choose tech that simplifies everything for us, yet letting us automate all we want. When in doubt, we’ll simplify — remove, until we can rationalize effort for the outcome to avoid over-engineering stuff. That is exactly what I’ve done for us here — so we don’t get stuck in an analysis/choice paralysis.
因此,这就是我们的出发点。 并建立。 我们假设我们可以选择可以简化我们所有工作的技术,但可以让我们自动化所有需要的技术。 如有疑问,我们将进行简化-删除,直到我们可以合理化结果的工作量,以避免过度设计。 这正是我在这里为我们所做的-因此我们不会陷入分析/选择麻痹的境地。
Note, everything we’ll use here will be assumed to be running on docker unless mentioned otherwise. So based on that we’ll use …
注意,除非另有说明,否则我们将在此处使用的所有内容都假定在docker上运行。 因此,基于此,我们将使用...
Apache Airflow for orchestrating our workflow: Airflow has quickly become the de-facto standard for authoring, scheduling, monitoring, and managing workflows — especially in data pipelines. We know that today, at least, 350 companies use Airflow in the broader tech industry along with a variety of executors and operators including kubernetes and docker.
Apache Airflow 用于协调我们的工作流程: Airflow已Swift成为用于创作,调度,监视和管理工作流程的事实标准,尤其是在数据管道中。 我们知道,今天,至少有350家公司以及更广泛的执行程序和操作员(包括kubernetes和docker)在更广泛的技术行业中使用Airflow 。
The usual suspects in the python ecosystem: for glue code, data engineering etc. The one notable addition would be vaex for processing large parquet files quickly and doing some data prep work.
python生态系统中 常见的嫌疑人 :用于粘合代码,数据工程等。其中一个值得注意的添加是vaex,用于快速处理大型木地板文件并进行一些数据准备工作。
Viya in a container & Viya as an Enterprise Analytics Platform(EAP): SAS Viya is an exciting technology platform that can be used to quickly build business focused capabilities on top of foundational analytical and AI models that SAS produces. We’ll use two flavors of SAS Viya — one as a container for building and running our models, and another one running on Virtual Machine(s) which acts as the enterprise analytics platform that the rest of our organization uses to perform analytics, consume reports, track and monitor models etc. For our specific use case, we’ll use the SAS platform’s autoML capabilities via the DataSciencePilot action set so that we can go full auto-mode on our problem.
容器中的Viya和作为企业分析平台(EAP)的 Viya:SAS Viya是一个令人兴奋的技术平台,可用于在SAS产生的基础分析和AI模型之上快速构建以业务为中心的功能。 我们将使用两种SAS Viya: 一种是用于构建和运行模型的容器 ,另一种是在虚拟机上运行,该虚拟机充当企业的分析平台 ,我们组织的其余部分用来执行分析,使用报告,跟踪和监视模型等。对于我们的特定用例,我们将通过DataSciencePilot操作集使用SAS平台的autoML功能,以便我们可以对问题进行全自动模式。
SAS Model Manager to inventory, track, & deploy models : This is the model management component on the Viya Enterprise Analytics Platform that we’ll use to eventually push the model out to the wild for scoring.
SAS模型管理器 以库存,跟踪和部署模型 :这是Viya Enterprise Analytics Platform上的模型管理组件,我们将使用该组件最终将模型推向野外进行评分。
Now that we’ve lined up all the basic building blocks, let’s address the business problem: We’re required to build a churn detection service so that our fictitious unicorn can detect potential churners and follow up with some remedial course of action to keep them engaged, instead of trying to reactivate them after the window of opportunity lapses. Because we plan to use Viya’s DataSciencePilot action set for training our model, we can simply prep the data and pass it off to dsautoml action which, as it turns out, is just a regular method call using the python-swat package. If you have access to Viya, you should try this out if you haven’t already.
现在,我们已经排列了所有基本的构建基块,让我们解决业务问题 :我们需要构建流失检测服务,以便我们虚构的独角兽可以检测到潜在的流失并采取一些补救措施来保持参与,而不是尝试在机会窗口消失后重新激活它们。 因为我们计划使用Viya的DataSciencePilot操作集来训练我们的模型,所以我们可以简单地准备数据并将其传递给dsautoml操作 ,事实证明,这只是使用python-swat包的常规方法调用。 如果您可以访问Viya,则应该尝试一下。
Also, if you didn’t pick up on it yet, we’re trying to automate everything including the model (re-)training process for models developed with autoML. We want to do this at a particular cadence as we fully expect to create fresh/new models whenever possible to keep up with the changing data. So automating autoML. Like Inception…😎
另外,如果您还没有掌握它,我们将尝试使包括使用autoML开发的模型的模型(重新)训练过程自动化。 我们希望以特定的节奏进行此操作,因为我们完全希望尽可能地创建新的/新的模型,以跟上不断变化的数据。 因此,自动化autoML。 像盗梦空间一样...😎
Anyway, remember: You’re the lone warrior in the effort to spawn artificial intelligence & release it into the back office services clan that attack emerging customer data and provide relevant micro-decisions. So there’s not much time to waste. So, let’s start.
无论如何,请记住:您是唯一的勇士,努力产生人工智能并将其发布到后台服务部门,以攻击新兴的客户数据并提供相关的微决策。 因此,没有太多时间可以浪费。 所以,让我们开始吧。
We’ll use a little Makefile to start our containers (see below) — it just runs a little script that starts up the containers by setting up the right params and triggering the right flags when ‘docker run’ is called. Nothing extraordinary, but gets the job done.
我们将使用一个小的Makefile来启动我们的容器(见下文)—它只是运行一个小的脚本,该脚本通过设置正确的参数并在调用“ docker run”时触发正确的标志来启动容器。 没什么特别的,但是可以完成工作。
Now, just like that, we’ve got our containers live and kicking. Once we have our notebook environment, we can call autoML via the dsautoml action after loading our data. The syntactic specifics of this action are available here. Very quickly, a sample method call looks like this :
现在,就像这样,我们使容器处于活动状态。 有了笔记本环境后,可以在加载数据后通过dsautoml操作调用autoML。 此操作的语法细节在此处提供 。 很快,示例方法调用如下所示:
# sess is the session context for the CAS session.sess.datasciencepilot.dsautoml(table = out, target = "CHURN",
inputs = effect_vars,
transformationPolicy={"missing":True,"cardinality":True,
"entropy":True, "iqv":True,
"skewness":True, "kurtosis":True,"outlier":True},
modelTypes = ["decisionTree", "GRADBOOST"],
objective = "AUC",
sampleSize = 20,
topKPipelines = 10,
kFolds = 2,
transformationout = dict(name="TRANSFORMATION_OUT", replace=True),
featureout = dict(name="FEATURE_OUT", replace=True),
pipelineout = dict(name="PIPELINE_OUT", replace=True),
savestate = dict(modelNamePrefix='churn_model', replace = True))I’ve placed the entire notebook in this repo for you to take a look, so worry not! This particular post isn’t about the specifics of dsautoml. If you are looking for a good intro to automl, you can head over here. You’ll be convinced.
我已将整个笔记本放入此存储库中供您查看,所以请不要担心! 这篇特别的文章与dsautoml的细节无关。 如果您正在寻找有关automl的良好介绍,则可以转到此处 。 您会被说服的。
As you will see, SAS DataSciencePilot (autoML) provides fully-automated capabilities that allow for multiple actions including automatic feature generation via the feature machine, which auto resolves the transformations needed and then using those features for constructing multiple pipelines in a full-on leaderboard challenge. Additionally, the dsautoml method call also produces two binary files. One for capturing the feature transformations that are performed and then another one for the top model. This means we get the score code for the champion and the feature transformations, so that we can deploy them easily into production. This is VERY important. In a commercial use case such as this one, model deployment is more important than development.
正如您将看到的,SAS DataSciencePilot(autoML)提供了全自动功能,该功能允许多种操作,包括通过功能机自动生成功能,该功能自动解析所需的转换,然后使用这些功能在一个完整的排行榜中构建多个管道挑战。 此外,dsautoml方法调用还会生成两个二进制文件。 一个用于捕获执行的特征转换,然后另一个用于捕获顶级模型。 这意味着我们可以获得冠军和功能转换的得分代码,以便我们可以轻松地将其部署到生产中。 这个非常重要。 在这样的商业用例中,模型部署比开发更重要。
If your models don’t get deployed, even the best of them perish doing nothing. And when that is the deal, even a 1-year old will pick something over nothing.
如果您的模型没有部署,那么即使是最好的模型也无济于事。 而当那笔交易达成时,即使是一岁的孩子,也总会收获一无所有。
This mandates us to always choose tools and techniques that meet the ask, and potentially increase the range of deployable options while avoiding re-work. In other words, your tool and model should be able to meet the acceptable scoring SLA of the workload for the business case. And you should know this before you start writing a single line of code. If this doesn’t happen, then any code we write is wasteful and meets no purpose other than satisfying personal fancies.
这要求我们始终选择能够满足要求的工具和技术,并有可能增加可部署选项的范围,同时避免返工 。 换句话说,您的工具和模型应该能够满足业务案例工作负载可接受的评分SLA。 在开始编写一行代码之前,您应该知道这一点。 如果这没有发生,那么我们编写的任何代码都是浪费,除了满足个人幻想之外,没有其他目的。
So, now that we have a way to automatically train these models on our data, let’s get this autoML process deployed for automatic retraining. This is where Airflow will help us immensely. Why? When we hand off “retraining” to production — there are bunch of new requirements that pop up such as:
因此,既然我们有了一种可以在我们的数据上自动训练这些模型的方法,那么让我们为自动重新训练部署此autoML流程。 这是Airflow将极大地帮助我们的地方。 为什么? 当我们将“再培训”交给生产时,会弹出很多新要求,例如:
- Error handling — How many times to retry? What happens if there is a failure? 错误处理-重试多少次? 如果发生故障怎么办?
- Quick and easy access to consolidated logs 快速轻松地访问合并日志
- Task Status Tracking 任务状态跟踪
- Ability to re-process historic data due to upstream changes 由于上游变化,能够重新处理历史数据
- Execution Dependencies on other processes: For example, process Y needs to run after process X, but what if X does not finish on-time? 对其他流程的执行依赖关系:例如,流程Y需要在流程X之后运行,但是如果X不能按时完成怎么办?
- Tracing Changes in the Automation Process Definition Files 跟踪自动化过程定义文件中的更改
Airflow handles all of the above elegantly. And not just that! We can quickly set up airflow on containers, and run it using docker-compose using this repo. Obviously you can edit the Dockerfile or the compose file as you see fit. Once again, I’ve edited these files to suit my needs and dropped it in this repo so you can follow along if you need to. At this point when you run docker-compose you should see postgres and airflow web server running
气流可以优雅地处理上述所有问题。 不仅如此! 我们可以快速在容器上设置气流,并使用docker-compose通过此repo运行它。 显然,您可以根据需要编辑Dockerfile或compose文件。 再次,我已经编辑了这些文件以满足我的需要,并将其放在此存储库中,以便您可以根据需要进行操作。 此时,当您运行docker-compose时,应该看到postgres和airflow Web服务器正在运行

Next, let’s look at the Directed Acyclic Graph (DAG) we’ll use to automatically rebuild this churn detection model weekly. Don’t worry, this DAG is also provided in the same repo.
接下来,让我们看一下有向无环图(DAG),我们将使用它每周自动重建这种流失检测模型。 不用担心,该DAG也在同一仓库中提供 。
Now, we’ll click into the graph view and understand what the DAG is trying to accomplish step by step.
现在,我们将单击进入图形视图并了解DAG试图逐步完成的任务。
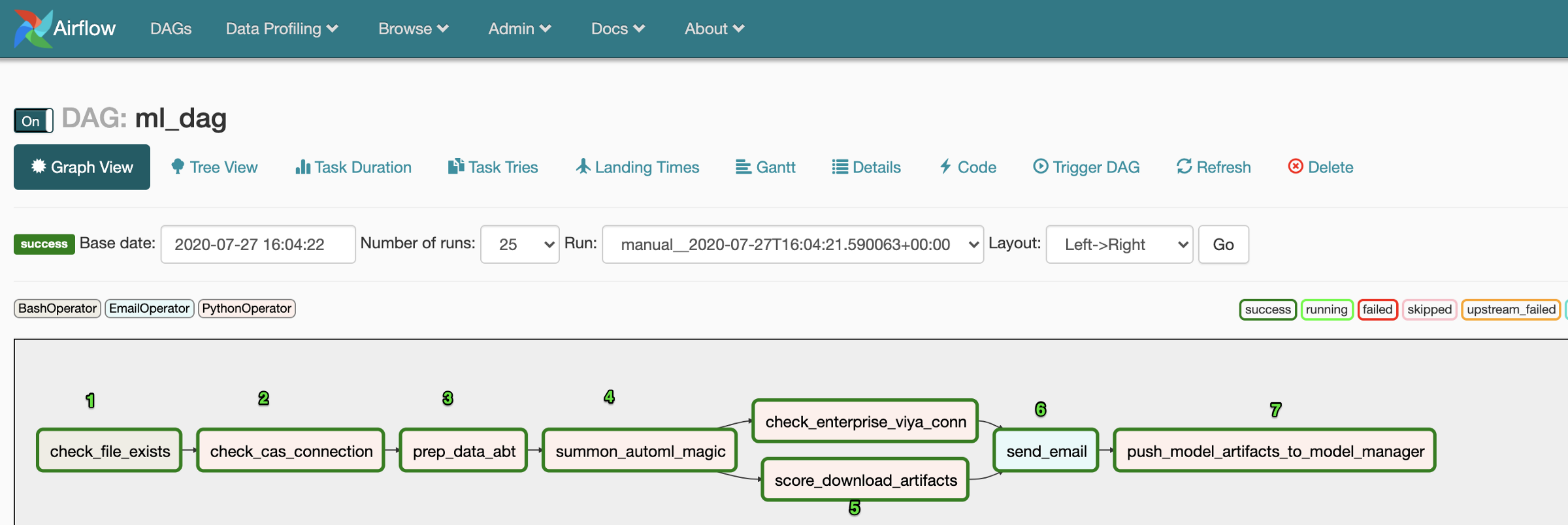
- We start by checking if a particular file exists. In our case, we start with a parquet file that we expect to see in a specific directory every week before we begin the process 我们首先检查是否存在特定文件。 在我们的案例中,我们从一个拼花文件开始,我们希望在开始该过程之前每周在一个特定目录中看到一个拼花文件
- Then we check for the readiness of the CAS container (viya container) 然后我们检查CAS容器(viya容器)是否准备就绪
- Following this, we prepare the analytics base table using vaex to quickly add couple of additional columns to our file 然后,我们使用vaex准备分析基础表,以将其他几列快速添加到文件中
- We then summon autoML and make DataSciencePilot figure out what the best model is for the data 然后,我们调用autoML并让DataSciencePilot找出最佳的数据模型
- Next we save all the relevant model artifacts, including a summary of all the top 10 pipelines generated so we get a view of the leaderboard. We also check the readiness of our Viya Enterprise Analytics Platform. 接下来,我们保存所有相关的模型工件,包括所有生成的前10条管道的摘要,以便我们查看排行榜。 我们还将检查Viya Enterprise Analytics Platform的准备情况。
- Now, we send an email out to our data science stakeholders with the leaderboard as an attachment to keep them informed about the automated run 现在,我们以排行榜的形式将电子邮件发送给我们的数据科学利益相关者,以使他们了解自动化运行情况
- Finally, we register these new champion model artifacts to SAS Model Manager, which is a part of our Viya Enterprise Analytics Platform. 最后,我们将这些新的冠军模型工件注册到SAS模型管理器中,该模型是我们Viya Enterprise Analytics Platform的一部分。
And that’s it! Our process is ready to be put to test!
就是这样! 我们的过程已准备就绪,可以进行测试!

When the process finishes successfully, all the tasks should report success and the gantt chart view in airflow should resolve to something that looks like the one above (execution times will obviously be different). And just like that, we’ve gotten incredibly close to the finish line.
当过程成功完成时,所有任务均应报告成功,并且气流中的甘特图视图应解析为类似于上图的视图(执行时间显然会有所不同)。 就像那样,我们已经非常接近终点线。
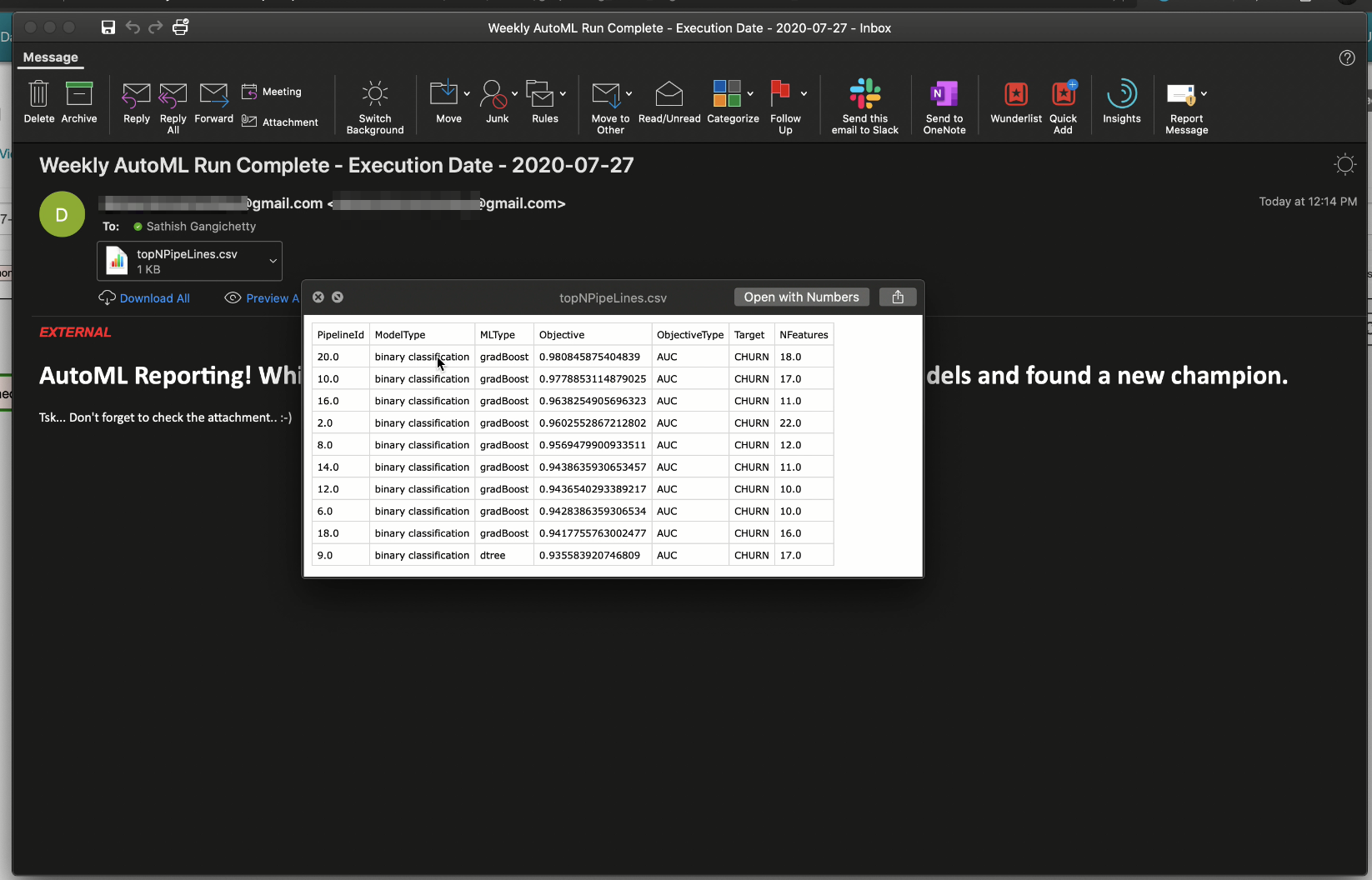
We’ve just automated our entire training process! Including saving our models for deployment and sending emails out whenever the DAG is run. If you look back, our original goal was to deploy these models as consumable services. We could’ve easily automated that part as well, but our choice of technology (SAS model manager in this case) allows us to add additional touch points, if you so desire. It normally makes sense to have a human-in-the-middle “push button” process before engaging in model publish activities, because it factors in buffers if upstream processes go wonky for reasons like crappy data, sudden changes in baseline distributions etc. More importantly, pushing models to production should actively bring in conscious human mindfulness to the activity. Surely, we wouldn’t want an out-of-sight process impacting the business wildly. Doing this ‘human-in-the-middle’ activity also significantly eliminates the unnecessary need to engage in post-hoc explanations as backtesting comes to the fore.
我们刚刚完成了整个培训过程! 包括保存我们的部署模型并在运行DAG时发送电子邮件。 如果回头看,我们的最初目标是将这些模型部署为消耗性服务。 我们也可以很容易地使那部分自动化,但是我们的技术选择(在这种情况下为SAS模型管理器)允许我们根据需要添加其他接触点。 通常,在进行模型发布活动之前先进行中间人“按钮”处理是有意义的,因为如果上游处理由于数据不足,基线分布突然变化等原因而变得不稳定,则会考虑到缓冲区。重要的是,将模型推向生产阶段应积极地将人类的正念带入活动中。 当然,我们不希望视线外的过程对业务产生巨大影响。 进行这种“中间人 ”活动还可以显着消除不必要的事后解释,因为回测即将到来。
Ok, lets see how all of this works real quick:
好的,让我们快速了解所有这些工作原理:
Notice that SAS Model Manager is able to take the model artifacts and publish them out as a module in a micro analytic service, where models can be consumed using scoring endpoints. And just like that, you are able to flip the switch on your models and make them respond to requests for inference.
注意, SAS Model Manager能够获取模型工件并将其作为模块发布到微分析服务中,在该服务中,可以使用计分端点来使用模型。 这样,您就可以翻转模型上的开关,并使它们响应推理请求。
There’s obviously no CI/CD component here just yet. That’s intentional. I didn’t want to overcomplicate this post since all we have is just a model here. I’ll come back and write a follow up on that topic on another day, at a later time, with another app. But for now, let’s rejoice in how much we’ve managed to get done automagically with Airflow & SAS Viya in containers.
显然,这里还没有CI / CD组件。 那是故意的。 我不想让这篇文章过于复杂,因为我们这里只是一个模型。 我将在第二天回来,稍后再通过另一个应用编写关于该主题的后续报告。 但是现在,让我们为使用Airflow和SAS Viya容器自动完成的工作量感到高兴。
Through thoughtful intelligent automation of mundane routines, using properly selected technology components, you can now make yourself available to focus on more exciting, cooler, higher order projects, while still making an ongoing impact in your unicorn organization through your models. Your best life is now. So why wait, when you can automate? 🤖
通过使用适当选择的技术组件,通过周到的例行程序智能自动化,您现在可以使自己专注于更令人兴奋,更酷,更高阶的项目,同时仍通过模型对独角兽组织产生持续影响。 你现在最好的生活。 那么,为什么要等到什么时候才能实现自动化呢? 🤖
airflow使用















 2485
2485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









