





 本文介绍了如何使用语言工程的方法,从原始的BIP39英文单词列表出发,构建适用于瑞典的BIP39单词表。内容涉及翻译过程和技术细节。
本文介绍了如何使用语言工程的方法,从原始的BIP39英文单词列表出发,构建适用于瑞典的BIP39单词表。内容涉及翻译过程和技术细节。
bip39英文单词列表
I’ve been keen on developing a Swedish BIP-39 compliant wordlist for some time now — using my favourite programming language Swift of course! A BIP-39 wordlist is a list of 2048 words that are easy to remember. In the context of BIP-39, each word can be used to encode a random integer in the range 0–2047 (11 bits). Where say the integer 3 is mapped to the fourth word in the wordlist. This can be used as a human-friendly serialization of random bytes, e.g. 32 bytes (256 bits) randomly generated Bitcoin private key (simplification, since one would typically use HD keys).
我一直渴望开发符合瑞典BIP-39标准的单词表-使用我最喜欢的编程语言Swift! BIP-39单词列表是一个2048个单词的列表,这些单词很容易记住。 在BIP-39的上下文中,每个字可用于编码0-2047(11位)范围内的随机整数。 其中,整数3映射到单词表中的第四个单词。 这可以用作人类友好的随机字节序列化,例如32字节(256位)随机生成的比特币私钥(简化,因为通常会使用HD密钥 )。
At first glance I thought it would not be so much work — boy was I wrong! 2048 did not sound like so many words, and I thought I could do a lot of the work manually by considering words that are easy to remember, turns out 2048 is, in fact, quite a lot of words. It turns out that between 800–3000 lemmas (word family/root word) is large enough an English vocabulary for day-to-day use
乍一看,我认为这不是那么多工作-男孩,我错了! 2048听起来不那么多,我想我可以通过考虑容易记住的单词来手动完成很多工作,事实证明2048实际上是很多单词。 事实证明,在800–3000个引理(词族/词根)之间,足以满足日常使用的英语词汇量
If you learn only 800 of the most frequently-used lemmas in English, you’ll be able to understand 75% of the language as it is spoken in normal life.
如果您仅学习800种英语中最常用的引理,那么您将能够理解正常生活中所讲语言的75%。
…
…
Eight hundred lemmas will help you speak a language in a day-to-day setting, but to understand dialogue in film or TV you’ll need to know the 3,000 most common lemmas.
800个引理将帮助您在日常环境中说一种语言,但是要了解电影或电视中的对话,您需要了解3,000种最常见的引理。
Quite early on I had an idea that homonyms would play a large role in the final word list since thanks to having multiple meanings it's more likely you will get an association with the word. So my idea is that it would be interesting to identify homonyms and give them a higher rank/priority.
相当早我就知道同音异义词 会在最终单词列表中扮演重要角色,因为由于具有多种含义,您更有可能与该单词相关联。 因此,我的想法是,识别同音异义词并为其赋予更高的排名/优先级会很有趣。
I also figured part of speech (POS) would play a large role since nouns such as “elephant” are easier to get an association with and thus easier to remember than determiners such as “the” or coordinating conjunctions such as “whether”. So I decided to analyze the POS distribution of the English BIP-39 wordlist. This was done by using the awesome Python tool NLTK(Natural Language Toolkit) and this small Python script I wrote:
我也讲话(POS)的一部分想通将发挥,因为名词 ,如“ 大象”更容易了很大的作用得到与关联,从而更容易比记住限定词 ,如“ 的”或并列连词 例如“是否”。 因此,我决定分析英语BIP-39单词表的POS分布。 这是通过使用很棒的Python工具NLTK (自然语言工具包)和我编写的这个小Python脚本完成的:
This is the POS distribution of the English BIP39 wordlist:
这是英语BIP39单词表的POS分发:
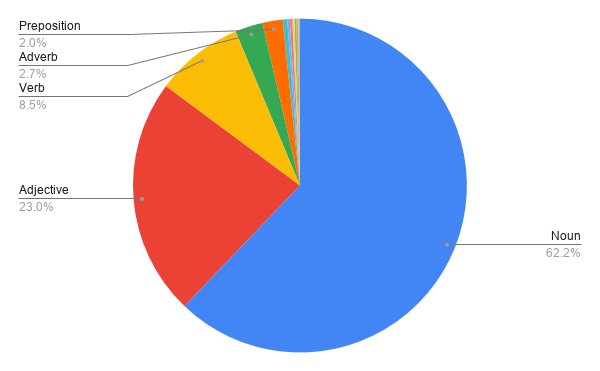
Not so surprisingly we see a clear noun dominance!
毫不奇怪,我们看到明显的名词优势!
语料库 (Corpus)
I have not used a “raw” Swedish corpus, but rather a parsed version which contains metadata regarding frequency, which saves a lot of time. So even though this is not a “raw” corpus, but rather a semi-processed one, I will refer to it as the “corpus”. I’ve used Språkbankens “Korpusstatistik”. Here we can find many documents, but I’ve used the aggregated file (“Samtliga i en fil” — “all in one file”), which is a 4.9 GB document you can download for yourself here. The file was last updated 2019–05–16. It contains 957,472,046 sentences and 13,310,488,661 tokens. Information about the format of the statistical document can be found here.
我没有使用“原始”瑞典语语料,而是使用了包含有关频率的元数据的已解析版本,从而节省了大量时间。 因此,即使这不是一个“原始”语料库,而是一个半处理的语料库,我还是将其称为“语料库”。 我用过Språkbankens “ Korpusstatistik” 。 在这里我们可以找到很多文档,但是我使用了聚合文件( “ Samtliga i en fil”-“全部在一个文件中” ),这是一个4.9 GB的文档,您可以在此处自己下载。 该文件的最新更新为2019-05-16。 它包含957,472,046个句子和13,310,488,661个令牌。 有关统计文件格式的信息可在此处找到。
语料库行格式 (Corpus Line Format)
Each line in the corpus contains six columns on a tab-separated format:
语料库中的每一行以制表符分隔的格式包含六列:
är VB.PRS.AKT |vara..vb.1| - 316581 13026.365036The columns contain this information:
这些列包含以下信息:
- Word 字
Part of speech, legend here
词性,传说在这里
Lemma(s) — here called “lemgram(s)” since it is the terminology used by Språkbanken in relation to the corpus.
引理—在这里称为“ 引理 ”,因为它是Språkbanken使用的与语料库有关的术语。
+or-which indicates whether a compound analysis was possible or not. E.g. (🇸🇪: "stämband", is a compound word consisting of "stäm" and "band")+或-表示是否可以进行化合物分析。 例如(🇸🇪: “stämband” ,是由“stäm”和“ band”组成的复合词)- Raw frequency (total number of occurrences) 原始频率(出现的总数)
- Relative frequency (number of occurrences per 1 million words) 相对频率(每百万字出现的次数)
解析语料库 (Parsing the corpus)
读行 (Read lines)
We begin with reading and then parsing L number of lines of the source corpus. The result of this program is a BIP39 compatible wordlist which contains 2048 (2¹¹) words.
我们首先阅读然后解析源语料库的L行。 该程序的结果是一个兼容BIP39的单词表,其中包含2048( 2¹¹ )个单词。
The goal of this step is to convert the source corpus into Swift ParsedLine models which we can write to a JSON file to allow faster execution of the program next time. For the next run of the program we can thus skip this step.
此步骤的目标是将源语料库转换为Swift ParsedLine模型,我们可以将其写入JSON文件,以便下次更快地执行程序。 因此,对于程序的下一次运行,我们可以跳过此步骤。
Apart from data parsed from corpus we add one additional property — indexOfWordInCorpus.
除了从语料库解析的数据之外,我们还添加了一个附加属性indexOfWordInCorpus 。
So far our algorithm looks something like this (Swifty-pseudocode):
到目前为止,我们的算法看起来像这样(Swifty-pseudocode):
let corpusFile = openFile("swedish_huge_corpus.txt")
let readLines = readLines(count: 100,000, from: corpusFile)
let parseLines = parseLines(readLines: readLines)拒绝不合适的线 (Reject unfit lines)
We are going to reject a lot of lines in the source corpus because it contains delimiters. It also contains words being too short (less than 3 characters, e.g. common Swedish words 🇸🇪: “en” (🇬🇧:”one”), and prepositions 🇸🇪: “i” (🇬🇧: “in”). So we can just read the first 2048 lines of the corpus, it is thus hard to know the value of L — the number of lines to read. And we cannot read all the lines because that would take way too much time given that the corpus is huge. So let’s just guess and set L = 100,000 for now.
我们将拒绝源语料库中的许多行,因为它包含定界符。 它还包含太短的单词(少于3个字符,例如瑞典常用单词🇸🇪: “ en” (🇬🇧: “ one” )和介词🇸🇪: “ i” (🇬🇧: “ in” )。我们只能读取语料库的前2048行,因此很难知道L的值(即要读取的行数),而且由于该语料库的数量过多,因此我们无法读取所有行。因此,让我们猜测一下,现在设置L = 100,000 。
We read the corpus until we have created a list of L lines. This step does not contain so much logic, but it is unnecessary to save lines which we know we will reject, e.g. because the word is too short, or because it is a delimiter.
我们阅读语料库,直到创建L行列表。 此步骤不包含太多逻辑,但是没有必要保存我们知道将拒绝的行,例如,因为单词太短或因为它是分隔符。
On line #252 in the corpus we find this line:
在语料库的第252行,我们找到以下行:
sa VB.PRT.AKT |säga..vb.1| - 4857774 364.958352
sa VB.PRT.AKT |säga..vb.1| - 4857774 364.958352
If we were to just look at the word (first component) — 🇸🇪: “sa” (🇬🇧: “said”), we would reject this line since it is less than threshold character count of 3, however, if we look at the base word (lemma), 🇸🇪: “säga” (🇬🇧: “to say”), it is four characters long. Thus including this line we might get interesting data for the decision in relation to the base word.
如果我们只看 字 (第一部分) - 🇸🇪:“SA”(🇬🇧:“说”),我们会拒绝这一行,因为它是小于3门槛字符数,但是,如果我们看看在基本单词(lemma)上,🇸🇪: “säga” (🇬🇧: “说” ),它是四个字符长。 因此,包括这一行,我们可能会获得有趣的数据以用于与基本单词有关的决策。
But word length is not the only criteria for rejection, we also might completely exclude some words having unwanted POS-tags. E.g. “foreign word” and we probably want to somehow enforce a POS distribution similar to that of the English BIP39 wordlist. So we update the pseudocode of our algorithm to reflect this logic
但是单词长度不是拒绝的唯一标准,我们也可能会完全排除某些带有多余POS标签的单词。 例如,“外来词”,我们可能希望以某种方式强制执行类似于英语BIP39单词表的POS分发。 因此,我们更新了算法的伪代码以反映此逻辑
let corpusFile = openFile("swedish_huge_corpus.txt")
let readLines = readLines(count: 100,000, from: corpusFile)
let parsedLines = parseLines(readLines)
let goodLengthLines = goodWordLengthLines(parsedLines)
let whitelistedPOSLines = whitelistedPOSLines(goodLengthLines)I don’t want to accidentally pass in parsedLines to function whitelistedPOSLines instead of goodLengthLines. Thus I create a separate type as output from each step. But that would easily lead to code duplication, as I wanted to include the original properties of the ParsedLine . I could have just let that be a single property in e.g. struct WordLengthLine like so:
我不想意外地将parsedLines传递给函数whitelistedPOSLines而不是goodLengthLines。 因此,我创建了一个单独的类型作为每个步骤的输出。 但这很容易导致代码重复,因为我想包括ParsedLine的原始属性。 我可以让它成为例如struct WordLengthLine的单个属性, struct WordLengthLine所示:
struct WordLengthLine {
let parsedLine: ParsedLine
}But then I would need to access the properties of ParsedLinevia theparsedLine property all the time, so I decided to create a set of protocols allowing me to write like this:
但是然后我需要ParsedLine通过parsedLine属性访问parsedLine属性,因此我决定创建一组协议,使我可以这样编写:
Where LineFromCorpusFromLine inherits to some other protocols below, allowing me to access all the properties of ParsedLine directly from an instance of WordLengthLine just like WordLengthLine was a ParsedLine. Now you might ask — “why not just use classes and inheritance” — to which I answer, when L=500,000 I really wanted to benefit from the memory and execution efficiency of structs rather than classes. I also love automagically synthesised initializers and conformance to Equatable, Hashable we get from structs.
LineFromCorpusFromLine继承了下面的其他协议,使我可以直接从WordLengthLine实例访问ParsedLine所有属性,就像WordLengthLine 是 ParsedLine. 现在您可能会问-“为什么不只使用类和继承”-我回答,当L=500,000我真的想从结构而不是类的内存和执行效率中受益。 我也很喜欢自动合成的初始值设定项以及对Equatable和Hashable一致性,我们从结构中获得了此Hashable 。
Our code still looks a bit boilerplate-y
我们的代码看起来还是有点样板
let corpusFile = openFile("swedish_huge_corpus.txt")
let readLines = readLines(count: 100_000, from: corpusFile)
let parsedLines = parseLines(readLines)
let goodLengthLines = goodWordLengthLines(parsedLines)
let whitelistedPOSLines = whitelistedPOSLines(goodLengthLines)Since we only use a variable declared on the line above ones and just pass it forward to a function call it would be nicer to be able to skip declaring the variable. What if we treat each function call here like a “step” or a “job” taking us one step closer to our result. We could create a small type for each job and then put them all in one “pipeline”, like so:
由于我们只使用在变量上面的行上声明的变量,然后将其传递给函数调用,因此跳过声明变量会更好。 如果我们将此处的每个函数调用都视为“步骤”或“工作”,那会使我们离结果更近一步该怎么办? 我们可以为每个作业创建一个小型类型,然后将它们全部放入一个“管道”中,如下所示:
let config = Config(
lineCount: 100_000,
fileName: "swedish_huge_corpus.txt"
)let pipeLine = Pipeline(config: config, jobs: [
OpenFileJob(),
ReadLinesJob(),
ParseLinesJob(),
...
])I call the entity above Pipeline because I want to “pipe” unix style | the output from job N-1 and let it be input for job N , and let the output of job N be input of job N+1 etc. So this requires generics, so our jobs need to declare type of input and output. Since we cannot put non-heterogenous elements in an array in Swift the pseudocode above will not work. We need some type-erasure here for sure combined with the possibility to “pipe” jobs together.
我将Pipeline称为“管道”上方的实体,因为我想“管道” Unix样式| 从作业的输出N-1让它成为作业输入N ,并让作业的输出N是工作的输入N+1等,所以这需要仿制药,所以我们的工作需要声明的输入和输出的类型 。 由于我们无法在Swift中将非异构元素放入数组中,因此上述伪代码将不起作用。 在这里,我们需要进行某种类型的擦除,以确保将各种作业“组合”在一起。
工作 (Job)
Let’s start by defining some protocol for ”jobs”/”steps”.
让我们首先为“工作” /“步骤”定义一些协议。
Now, let’s — for sake of convenience (will save lots of code) — declare an operator allowing us to pipe jobs together.
现在,为了方便起见(将节省大量代码),让我们声明一个操作符,允许我们将作业一起发送。
Great! But how can we use these? Let’s create a type called Pipeline which makes use of these.
大! 但是我们如何使用这些呢? 让我们创建一个使用这些类型的名为Pipeline的类型。
We can see that our Pipeline itself conforms to the protocol Job and thus have to declare types Input and Output respectively and also declaring the work:input method. So how can we initialize the Pipeline with several jobs and pipe them all together?
我们可以看到我们的Pipeline本身符合Job协议,因此必须分别声明Input和Output类型,并声明work:input方法。 那么,我们如何用几个作业初始化Pipeline并将它们全部管道化呢?
Turns out there’s language support — since Swift 5.1 — the Function Builder. Here is the original Swift Evolution proposal (dating back to 2019–06–03) — but just recently (2020–08–16) a much-updated version was suggested which:
事实证明,自Swift 5.1起,就提供了语言支持-函数生成器。 这是原始的Swift Evolution提案 (可追溯到2019-06-03),但是最近(2020-08-16)提出了一个更新很大的版本,其中:
“captures the actual state of the implementation on master (any trunk development snapshot 2 will do), most of which is also in Swift 5.3.”
“捕获主服务器上的实现的实际状态(任何主干开发快照2都可以),其中大多数也位于Swift 5.3中。”
By using Generics + Function Builders (@_functionBuilder) we can achieve great syntax call site, while also clear code and responsibility declaration site. But before I proceed with the implementation let’s talk a bit about variadic generics (Swift lang “Generics Manifesto”). We want to be able to pipe job A, B, C and D together, like so: A | B | C | D . Or to use the syntax according to the actual operator declared above: A |> B |> C |> D where each job, of course, conforms to the protocol Job , thus declaring an associatedtype Input and Output respectively. Thus we have lots of constraints: D.Input == C.Output and C.Input == B.Output on so on and so forth. Thus we need to be able to accept an array of jobs each where each type of job is declared as a generic type (with constraints) in the function signature. For a pipeline with 3 jobs, we require 3 generic types (with constraints…), for a pipeline with 4 jobs we require 4 generic types etc etc. This is called variadic generics — for which Swift currently (Swift 5.2 (Xcode 12 beta 4)) — does not have support. So have to manually declare an initializer/buildBlock function for each amount of jobs we want to support. Because lack of variadic generics support in Swift, Apple went with the solution of declaring a combo of 0…9 views types for the special purpose @_functionBuilder called @ViewBuilder — being the reason why you cannot declare more than 10 child views in any view in SwiftUI:
通过使用泛型+函数构建器( @_functionBuilder ),我们可以实现出色的语法调用站点,同时还可以清除代码和责任声明站点。 但是在继续执行之前,让我们先谈谈可变参数泛型 (Swift lang“泛型宣言”) 。 我们希望能够管工作A,B,C和d在一起,就像这样: A | B | C | D A | B | C | D A | B | C | D 或者根据上面声明的实际运算符使用语法: A |> B |> C |> D ,其中每个作业当然都符合协议Job ,因此分别声明了一个关联类型Input和Output 。 因此,我们有很多约束: D.Input == C.Output和C.Input == B.Output 等等,依此类推 。 因此,我们需要能够接受一个作业数组,其中每个作业类型在函数签名中都被声明为具有约束的泛型类型。 对于具有3个作业的管道,我们需要3个泛型类型(带有约束…),对于具有4个作业的管道,我们需要4个泛型类型, 以此类推 。这称为可变参数泛型-当前,这是Swift(Swift 5.2(Xcode 12 beta 4 ))- 没有支持 。 因此,必须为我们要支持的 每个 工作量手动声明一个initializer / buildBlock函数。 由于Swift中缺乏对可变参数的泛型支持,因此Apple采取了以下解决方案:针对特殊用途@_functionBuilder声明一个0…9 视图类型的组合,称为@ViewBuilder ,这就是为什么在任何视图中不能声明超过10个子视图的原因。 SwiftUI:

ViewBuilderViewBuilder declares 10 different declares 10 different buildBlockbuildBlock methods for a combo of 0...9 child views — due to lack of variadic generics support in Swift.methods for a combo of 0...9 child views — due to lack of variadic generics support in Swift.
Anyhow, my point is, I have to retort to the same solution as Apple did with SwiftUI’s ViewBuilder, namely declaring one many similar buildBlocks. This kind of boilerplate makes me crazy! So I will be incredibly happy the day we have variadic generics in Swift. A possible solution to alleviate the repetitive boilerplate situation is gyb — “generate your boilerplate” — an Apple developed Swift code generation tool written in Python, use by Apple in e.g. swift-crypto (I wrote that section by the way 😃) and thus probably also in closed source CryptoKit. I reckon gyb also is used in SwiftUI. Another amazing alternative is the metaprogramming tool Sourcery. But I think I will make the same design choice as Apple did with SwiftUI and only support up to a max of 10 jobs for now and that is just below the pain point threshold justifying complicating things with gyb or Sourcery.
无论如何,我的意思是,我必须反驳为Apple使用SwiftUI的ViewBuilder所做的相同解决方案,即声明一个类似的buildBlocks。 这种样板让我疯狂! 因此,在Swift中使用可变参数泛型的那一天,我将感到无比高兴。 减轻重复样板情况的一种可能的解决方案是gyb-“生成样板”-苹果公司开发的Python写的Swift代码生成工具,Apple在例如swift-crypto中使用 ( 我以😃的方式写了那部分 ),因此可能也在封闭源代码CryptoKit中 。 我认为gyb也用于SwiftUI。 另一个令人惊奇的替代方法是元编程工具Sourcery 。 但是我认为我将做出与Apple使用SwiftUI相同的设计选择,并且目前最多仅支持10个工作,这正好低于使gyb或Sourcery变得复杂的痛苦点阈值。
Without much further ado, here is the implementation:
事不宜迟,这里是实现:
Where descriptionOf used in each Pipeline init is just a small function concatenating the name of the job types together. In the trailing closure of each Pipeline init we make use of our custom operator |> making it pretty sweet and easy to read IMO.
每个Pipeline init中使用的descriptionOf只是一个将作业类型的名称连接在一起的小函数。 在每个Pipeline初始化的结尾关闭中,我们都使用我们的自定义运算符|>使其非常可爱并且易于阅读IMO。
等等,为什么呢? (Wait, but why?)
Hmm why did we trouble ourselves with all this again? Well, I wanted nice and sweet syntax when declaring our “algorithm” doing the work of parsing the corpus and outputting a list of Swedish words, being BIP39 compliant. I early identified it having a repetitive nature of small steps or “jobs” being chained together to achieve the goal. And I wanted it to be easy to remove a particular job or replace it with another or just easy to add another one. The result of the “manual variadic generic + functionBuilder”-dance above is this:
嗯,为什么我们又要为这一切烦恼呢? 好吧,在声明我们的“算法”来进行语料库解析并输出符合BIP39的瑞典语单词列表时,我希望使用一种优美而甜美的语法。 我很早就发现它具有重复性,即将小步骤或“工作”链接在一起以实现目标。 而且我希望能够轻松删除某个特定工作或将其替换为另一个工作,或者只是轻松添加另一个工作。 上面的“手动可变参数泛型+ functionBuilder”舞蹈的结果是:
We can create minimal, self-contained, easy to test “jobs” and pipe (chain) them together with this “composition syntax”. If we realize we want to add more logic we can easily add another job or change any of the tiny job structs.
我们可以创建最小的,自包含的,易于测试的“作业”,并将其与这种“组合语法”一起管道化(链接)。 如果意识到要添加更多的逻辑,则可以轻松地添加另一个作业或更改任何微小的作业结构。
进一步改进 (Further improvements)
Running the pipeline takes a bit of time depending on how many thousands lines from the corpus we wanna read. What if we are working on logic in the third of fourth job, then we will benefit greatly from being able to cache the results of the first couple of jobs. So I improved the pipeline by introducing a new protocol called CacheableJob .
运行管道需要一些时间,具体取决于我们想从语料库中读取几千行。 如果我们在第四项工作的第三项中研究逻辑该怎么办,那么我们将能够缓存前两项工作的结果而受益匪浅。 因此,我通过引入一种称为CacheableJob的新协议来改进了管道。
Where Cacher is just a simple utility I wrote using Swift’s Codable and writing the result to disc. We can then easily make all our *Line DTOs conform to Codable — which we get automatically since they are all structs.
Cacher只是一个简单的实用程序,我使用Swift的Codable编写并将结果写入光盘。 然后,我们可以轻松地使所有*Line DTO符合Codable ,因为它们都是结构,所以我们会自动获得它们。
I also do not output Array<ScannedLine> but rather a typealias ScannesLines = Lines<ScannedLine> as output, where Lines is my custom collection type for bundling together lines.
我也不输出Array<ScannedLine>而是输出一个类型typealias ScannesLines = Lines<ScannedLine>作为输出,其中Lines是我的自定义集合类型,用于将线捆绑在一起。
Now ScanJob is cachable and it can validate its cache by looking if we have load enough lines from the cache.
现在ScanJob是可缓存的,它可以通过查看是否从缓存加载了足够的行来验证其缓存。
那么,瑞典的BIP39单词表是什么? (So what is the Swedish BIP39 wordlist?)
Sorry! I don’t have one yet, since have not managed to get a good enough result yet. But I will update this blog post once I do.
抱歉! 我还没有,因为还没有获得足够好的结果。 但是,一旦完成,我将更新此博客文章。
Here’s the link to the GitHub repo with this project, it is called Behandla (🇬🇧 “Process”). I also decided to try to refactor out just the Pipeline part as a separate SPM package (it was over half a year since I worked on it though so I don’t really know its state, feel free to have a look anyway!).
这是该项目的GitHub存储库的链接,称为Behandla (🇬🇧“流程”)。 我还决定尝试将管道部分作为一个单独的SPM软件包进行重构(尽管我从事此工作已经半年了,所以我并不十分了解它的状态,请随时查看!)。
This is my submission for TopTal’s Swift page — https://www.toptal.com/swift
这是我对提交TopTal的斯威夫特页面- https://www.toptal.com/swift
bip39英文单词列表
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









