





权力的游戏字幕哪家强
It’s been 1 year since the end of Game of Thrones and I’ve made it a point to mess around a little bit with the subtitles of the series throughout the 8 seasons it’s been on air.
自《权力的游戏》(Game of Thrones)结束以来已经有1年了,我已经指出在整个播出的8个季节中都对该系列的字幕有些混乱。
SubRip Subtitle files (SRT) are plain-text files that contain subtitle information. They include start and stop times next to the subtitle text, ensuring they’ll be displayed at exactly the right moment in your video. SRT files work on most social media sites that let you upload captions.
SubRip字幕文件(SRT)是包含字幕信息的纯文本文件。 它们在字幕文本旁边包含开始和停止时间,以确保它们在视频中的正确时间显示。 SRT文件在大多数允许您上传字幕的社交媒体网站上都可以使用。
In this article we are going to: * Use bash scripts * Load srt * Transform dataset * Make a WordCloud * Count most common word
在本文中,我们将:*使用bash脚本*加载srt *转换数据集*创建一个WordCloud *计算最常见的单词
从kaggle加载数据集 (Load dataset from kaggle)
语境 (Context)
This dataset contains every line from every season of the HBO TV show Game of Thrones.
该数据集包含HBO电视节目《权力的游戏》每个季节的每一行。
内容 (Content)
Each season has one JSON file. In eachJSON file there is a key for each episode and each episode is further mapped at a dialogue level.
每个季节都有一个JSON文件。 在每个JSON文件中,每个情节都有一个密钥,并且每个情节都进一步映射到对话级别。
灵感 (Inspiration)
The idea is to use this data set to see if one can create a summary of what transpired in each episode or season.
想法是使用此数据集来查看是否可以创建每个情节或每个季节发生的情况的摘要。
! find . -name "*.json" -type f -print0 | xargs -0 /bin/rm -f
! rm -f game-of-thrones-srt.zip
! kaggle datasets download -d gunnvant/game-of-thrones-srtWarning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /home/oscar/.kaggle/kaggle.json'
Downloading game-of-thrones-srt.zip to /home/oscar/Documentos/Medium/dialogos
0%| | 0.00/739k [00:00<?, ?B/s]
100%|████████████████████████████████████████| 739k/739k [00:00<00:00, 9.63MB/s]# Unzip
! unzip game-of-thrones-srt.zipArchive: game-of-thrones-srt.zip
inflating: season1.json
inflating: season2.json
inflating: season3.json
inflating: season4.json
inflating: season5.json
inflating: season6.json
inflating: season7.json! lsgame-of-thrones-srt.zip season4.json subtitle_Game_of_thrones.ipynb
season1.json season5.json words_friends.csv
season2.json season6.json your_file_name.png
season3.json season7.json导入库 (Import libraries)
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud加载json数据帧 (Load json dataframes)
file_name = 'season{}.json'
df_list = []
for i in range(1, 8):
df_list.append(pd.read_json(file_name.format(i)))df = pd.concat(df_list)
df
# Show header of each column
list(df)['Game Of Thrones S01E01 Winter Is Coming.srt',
'Game Of Thrones S01E02 The Kingsroad.srt',
'Game Of Thrones S01E03 Lord Snow.srt',
'Game Of Thrones S01E04 Cripples, Bastards, And Broken Things.srt',
'Game Of Thrones S01E05 The Wolf And The Lion.srt',
'Game Of Thrones S01E06 A Golden Crown.srt',
'Game Of Thrones S01E07 You Win Or You Die.srt',
'Game Of Thrones S01E08 The Pointy End.srt',
'Game Of Thrones S01E09 Baelor.srt',
'Game Of Thrones S01E10 Fire And Blood.srt',
'Game Of Thrones S02E01 The North Remembers.srt',
'Game Of Thrones S02E02 The Night Lands.srt',
'Game Of Thrones S02E03 What Is Dead May Never Die.srt',
'Game Of Thrones S02E04 Garden Of Bones.srt',
'Game Of Thrones S02E05 The Ghost Of Harrenhal.srt',
'Game Of Thrones S02E06 The Old Gods And The New.srt',
'Game Of Thrones S02E07 A Man Without Honor.srt',
'Game Of Thrones S02E08 The Prince Of Winterfell.srt',
'Game Of Thrones S02E09 Blackwater.srt',
'Game Of Thrones S02E10 Valar Morghulis.srt',
'Game Of Thrones S03E01 Valar Dohaeris.srt',
'Game Of Thrones S03E02 Dark Wings, Dark Words.srt',
'Game Of Thrones S03E03 Walk Of Punishment.srt',
'Game Of Thrones S03E04 And Now His Watch Is Ended.srt',
'Game Of Thrones S03E05 Kissed By Fire.srt',
'Game Of Thrones S03E06 The Climb.srt',
'Game Of Thrones S03E07 The Bear And The Maiden Fair.srt',
'Game Of Thrones S03E08 Second Sons.srt',
'Game Of Thrones S03E09 The Rains Of Castamere.srt',
'Game Of Thrones S03E10 Mhysa.srt',
'Game Of Thrones S04E01 Two Swords.srt',
'Game Of Thrones S04E02 The Lion And The Rose.srt',
'Game Of Thrones S04E03 Breaker Of Chains.srt',
'Game Of Thrones S04E04 Oathkeeper.srt',
'Game Of Thrones S04E05 First Of His Name.srt',
'Game Of Thrones S04E06 The Laws Of Gods And Men.srt',
'Game Of Thrones S04E07 Mockingbird.srt',
'Game Of Thrones S04E08 The Mountain And The Viper.srt',
'Game Of Thrones S04E09 The Watchers On The Wall.srt',
'Game Of Thrones S04E10 The Children.srt',
'season4.json',
'Game Of Thrones S05E01 The Wars To Come.srt',
'Game Of Thrones S05E02 The House Of Black And White.srt',
'Game Of Thrones S05E03 High Sparrow.srt',
'Game Of Thrones S05E04 Sons Of The Harpy.srt',
'Game Of Thrones S05E05 Kill The Boy.srt',
'Game Of Thrones S05E06 Unbowed, Unbent, Unbroken.srt',
'Game Of Thrones S05E07 The Gift.srt',
'Game Of Thrones S05E08 Hardhome.srt',
'Game Of Thrones S05E09 The Dance Of Dragons.srt',
"Game Of Thrones S05E10 Mother's Mercy.srt",
'Game Of Thrones S06E01 The Red Woman.srt',
'Game Of Thrones S06E02 Home.srt',
'Game Of Thrones S06E03 Oathbreaker.srt',
'Game Of Thrones S06E04 Book of the Stranger.srt',
'Game Of Thrones S06E05 The Door.srt',
'Game Of Thrones S06E06 Blood of My Blood.srt',
'Game Of Thrones S06E07 The Broken Man.srt',
'Game Of Thrones S06E08 No One.srt',
'Game Of Thrones S06E09 Battle of the Bastards.srt',
'Game Of Thrones S06E10 The Winds of Winter.srt',
'Game Of Thrones S07E01 Dragonstone.srt',
'Game Of Thrones S07E02 Stormborn.srt',
"Game Of Thrones S07E03 The Queen's Justice.srt",
'Game Of Thrones S07E04 The Spoils Of War.srt',
'Game Of Thrones S07E05 Eastwatch.srt',
'Game Of Thrones S07E06 Beyond The Wall.srt',
'Game Of Thrones S07E07 The Dragon And The Wolf.srt']# Join all columns value in one row removing NaN
dff= df.agg(lambda x: ', '.join(x.dropna())).to_frame().T
dff
# Transpose de dataframe
result = dff.transpose()
result
# Join all columns value in one row removing NaN
data= result.agg(lambda x: ', '.join(x.dropna())).to_frame().T# We can se all values of dataframe
# data.values# Convert a dataframe in list
text= data.iloc[:, 0].tolist()
len(text)
# convert all words in lowercase
text = [each_string.lower() for each_string in text]# Because we have a list of one item, with this script we split a list of sentences into separate words in a list
words = " ".join(text).split()
words[:10]['easy,',
'boy.,',
'our',
'orders',
'were',
'to',
'track',
'the',
'wildlings.,',
'-']len(words)289669# Show the number of words of the list
num_words = [len(sentence.split()) for sentence in text]
print(num_words)[289669]# Remove special character from list
import re
new_list=list(filter(lambda x:x, map(lambda x:re.sub(r'[^A-Za-z]', '', x), words)))new_list[:10]['easy',
'boy',
'our',
'orders',
'were',
'to',
'track',
'the',
'wildlings',
'right']## Word cloudWith this processing, I can already make a classification of the most used words in the “Game of Thrones” dialogues, but I prefer to make a better refinement of the data and eliminate the so-called “stop words”, which would be the articles, pronouns, among others, that are used in the conversations and in turn remove the names of the protagonists.
通过这种处理,我已经可以在“权力的游戏”对话框中对最常用的单词进行分类,但是我更喜欢对数据进行更好的细化并消除所谓的“停用词”。对话中使用的文章,代词等,并依次删除主角的名字。
import nltk
nltk.download('stopwords')[nltk_data] Downloading package stopwords to /home/oscar/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
TrueCreate a list of English pronoms
创建英语代词列表
pronoms = ('all','another','any','anybody','anyone','anything','as','aught','both','each','each other'
,'either','enough','everybody','everyone','everything','few','he','her','hers','herself','him','himself'
,'his','I','idem','it','its','itself','many','me','mine','most','my','myself','naught','neither','no one'
,'nobody','none','nothing','nought','one','one another','other','others','ought','our','ours','ourself','ourselves'
,'several','she','some','somebody','someone','something','somewhat','such','suchlike','that','thee','their','theirs'
,'theirself','theirselves','them','themself','themselves','there','these','they','thine','this','those'
,'thou','thy','thyself','us','we','what','whatever','whatnot','whatsoever'
,'whence','where','whereby','wherefrom','wherein','whereinto','whereof','whereon','wherever','wheresoever'
,'whereto','whereunto','wherewith','wherewithal','whether','which','whichever','whichsoever','who','whoever','whom','whomever'
,'whomso','whomsoever','whose','whosever','whosesoever','whoso','whosoever','ye','yon','yonder','you','your','yours','yourself','yourselves')from nltk.corpus import stopwords
stop_words = nltk.corpus.stopwords.words('english')
pronoms = ['all','another','any','anybody','anyone','anything','as','aught','both','each','each other'
,'either','enough','everybody','everyone','everything','few','he','her','hers','herself','him','himself'
,'his','I','idem','it','its','itself','many','me','mine','most','my','myself','naught','neither','no one'
,'nobody','none','nothing','nought','one','one another','other','others','ought','our','ours','ourself','ourselves'
,'several','she','some','somebody','someone','something','somewhat','such','suchlike','that','thee','their','theirs'
,'theirself','theirselves','them','themself','themselves','there','these','they','thine','this','those'
,'thou','thy','thyself','us','we','what','whatever','whatnot','whatsoever'
,'whence','where','whereby','wherefrom','wherein','whereinto','whereof','whereon','wherever','wheresoever'
,'whereto','whereunto','wherewith','wherewithal','whether','which','whichever','whichsoever','who','whoever','whom','whomever'
,'whomso','whomsoever','whose','whosever','whosesoever','whoso','whosoever','ye','yon','yonder','you','your','yours','yourself','yourselves']
stop_words.extend(pronoms)
all = []
for report in new_list:
if not report in stop_words:
all.append(report)all[:10]['easy',
'boy',
'orders',
'track',
'wildlings',
'right',
'give',
'put',
'away',
'blade']#You can use a set to remove duplicates, and then the len function to count the elements in the set:
len(set(all))10352生成词云 (Generating word cloud)
#convert list to string and generate
unique_string=(" ").join(all)
wordcloud = WordCloud(width = 1000, height = 500).generate(unique_string)
plt.figure(figsize=(15,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig("your_file_name"+".png", bbox_inches='tight')
plt.show()
plt.close()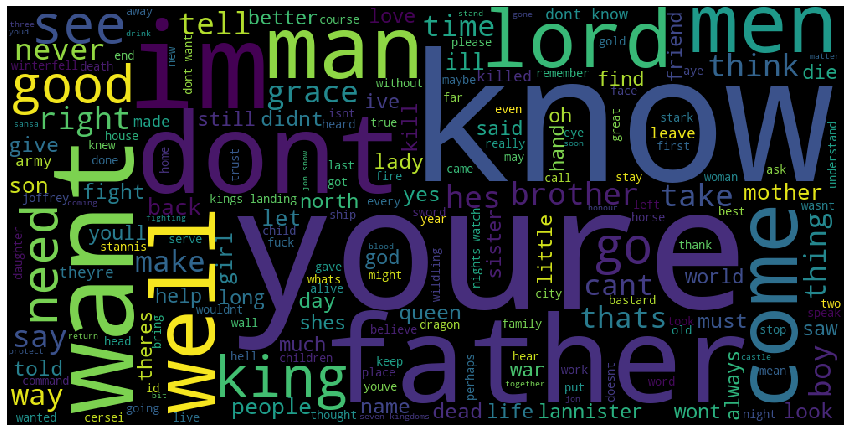
for i in range(1,30):
print(unique_string[:i])e
ea
eas
easy
easy
easy b
easy bo
easy boy
easy boy
easy boy o
easy boy or
easy boy ord
easy boy orde
easy boy order
easy boy orders
easy boy orders
easy boy orders t
easy boy orders tr
easy boy orders tra
easy boy orders trac
easy boy orders track
easy boy orders track
easy boy orders track w
easy boy orders track wi
easy boy orders track wil
easy boy orders track wild
easy boy orders track wildl
easy boy orders track wildli
easy boy orders track wildlinfrom collections import Counter
counts = Counter(all)
sorted(counts.items())[:10][('aah', 3),
('abandon', 22),
('abandoned', 13),
('abandoning', 9),
('abate', 1),
('abated', 1),
('abduct', 2),
('abducted', 1),
('abetting', 1),
('abiding', 1)]most_common=counts.most_common(10)
most_common[('dont', 1412),
('im', 1294),
('know', 1211),
('youre', 1119),
('lord', 1118),
('want', 865),
('like', 859),
('king', 814),
('would', 796),
('man', 778)]for ThisItem in most_common:
print("Item: ", ThisItem[0],
" Appears: ", ThisItem[1])Item: dont Appears: 1412
Item: im Appears: 1294
Item: know Appears: 1211
Item: youre Appears: 1119
Item: lord Appears: 1118
Item: want Appears: 865
Item: like Appears: 859
Item: king Appears: 814
Item: would Appears: 796
Item: man Appears: 778结论: (Conclusion:)
As you can see the “Game of Thrones” series gives us a lot of play to make articles like this. I hope you like it.
如您所见,“权力的游戏”系列为我们撰写此类文章提供了很多机会。 我希望你喜欢它。
I hope it will help you to develop your training.
我希望它能帮助您发展培训。
No matter what books or blogs or courses or videos one learns from, when it comes to implementation everything might look like “Out of Syllabus”
无论从中学到什么书,博客,课程或视频,到实施时,一切都可能看起来像“课程提纲”
Best way to learn is by doing!
Best way to learn is by teaching what you have learned!永不放弃! (Never give up!)
See you in Linkedin!
在Linkedin上见!
翻译自: https://medium.com/@zumaia/working-with-game-of-thrones-subtitles-7adc6efe026a
权力的游戏字幕哪家强


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









