





html设置模块偏移量
使用时间转换模块自动生成NBA精彩视频 (Automate NBA highlight video generation with Temporal Shift Module)

介绍 (Introduction)
Recently, the explosive growth of video streaming arises a challenge for a video content understanding technology with high accuracy and low computational cost. The existing methods, such as 2D CNNs and 3D CNN, have many weaknesses to deploy on low-cost engine. To be more specific, conventional 2D CNNs are computationally cheap but cannot capture temporal relationship between continuous frames. Meanwhile, 3D CNN based methods can achieve good performance but are computationally intensive. Proposed by a paper called “TSM: Temporal shift module for efficient video understanding”, We will introduce a solution with high efficiency and performance, and how to generate a highlight video from a given NBA match through this method.
近来,视频流的爆炸性增长对具有高精度和低计算成本的视频内容理解技术提出了挑战。 现有的方法(如2D CNN和3D CNN)在低成本引擎上部署存在许多缺陷。 更具体地说,常规的2D CNN在计算上便宜,但是不能捕获连续帧之间的时间关系。 同时,基于3D CNN的方法可以实现良好的性能,但计算量大。 由一篇名为“ TSM:用于有效理解视频的时间转换模块”的论文提出,我们将介绍一种高效,高性能的解决方案,以及如何通过这种方法从给定的NBA比赛中生成精彩视频。
目前的方法 (Current approach)
2D CNNsThe difference between video recognition and image recognition is the need for temporal modeling. Several 2D CNN based methods are used to solve this problem. The first is two-stream architecture [1] which incorporates spatial and temporal network where videos can naturally be decomposed into corresponding components. In spatial part, single frame will be extracted by manipulating — 2D convolutional layers and pooling layers, etc. — before applying softmax function to obtain class score. In temporal part, optical flow is demonstrated in the form of motion across the frames.
2D CNN视频识别和图像识别之间的区别是需要时间建模。 几种基于2D CNN的方法用于解决此问题。 第一个是两流体系结构 [1],它合并了时空网络,其中视频可以自然地分解为相应的组件。 在空间部分,在应用softmax函数获得类评分之前,将通过操纵2D卷积层和池化层等来提取单个帧。 在时间部分,以跨帧运动的形式展示了光流 。
Another one is Temporal Segment Network [2] which extracts averaged features from sequential sample frames. However, 2D CNNs on individual frames fail to model effectively the temporal information.
另一个是时间分段网络[2],它从顺序样本帧中提取平均特征。 但是,单个帧上的2D CNN无法有效地建模时间信息。

3D CNNsSuperior than previously mentioned method, 3D CNNs can jointly learn spatial and temporal features. For instance, method based on VGG models, named C3D [3] can learn spatial-temporal features from a frame sequence. However, the computational cost is still relatively large.
3D CNN比之前提到的方法优越,3D CNN可以共同学习空间和时间特征。 例如,基于VGG模型的名为C3D [3]的方法可以从帧序列中学习时空特征。 但是,计算成本仍然相对较大。
Both 2D CNNs and 3D CNNs approach make a highly efficient and low cost production difficult to deploy. Tackling on these limitations, this paper [4] proposes a new perspective for efficient temporal modeling in video content understanding by introducing a novel technology, Temporal Shift Module (TSM). TSM not only significantly improves the 2D baseline but also outperforms existing state-of-the-art methods on both Something-Something V1&V2 datasets in 2019.
2D CNN和3D CNN方法都难以部署高效且低成本的产品。 针对这些局限性,本文[4]通过介绍一种新技术,即时移模块(TSM),为视频内容理解中的有效时态建模提出了一个新的视角。 TSM不仅显着改善了2D基线,而且在2019年的Something-Something V1&V2数据集上也超过了现有的最新方法。

时移模块 (Temporal Shift Module)
Particularly, in video understanding analysis, features can be represented as shape A ∈ R: (N, T, C, H, W) where N is the batch size, T is the temporal dimensions, C is the number of channels, H and W are spatial resolutions. In contrast with 2D CNN based methods, TSM shifts the channels along temporal dimension including both forward and backward. After shifting, information from neighbor frame is mingled with current features, as shown in image above.
特别地,在视频理解分析中,特征可以表示为形状A∈R:(N,T,C,H,W),其中N是批处理大小,T是时间维,C是通道数,H和W是空间分辨率。 与基于2D CNN的方法相反,TSM沿着时间维度(包括前进和后退)移动频道。 移位后,来自相邻帧的信息与当前特征混合在一起,如上图所示。
Actually, if the technique shifts all or most of the channels, it may lead to two disasters: worse efficiency due to large data movement and performance degradation due to poor spatial modeling ability. How to tackle these problems?. To reduce data movement, only a small proportion of the channels is shifted, e.g., 1/8 to limit the latency overhead and bring down the memory movement cost.
实际上,如果该技术转移了所有或大部分通道,则可能导致两次灾难:由于大量数据移动而导致效率降低,以及由于空间建模能力较差而导致的性能下降。 如何解决这些问题? 为了减少数据移动,仅移动一小部分通道,例如1/8,以限制等待时间开销并降低内存移动成本。
While feature extractor is modeled with ResNet-50 backbone, the straight-forward way is to apply TSM by inserting it before each convolutional layer or residual block. It is called in-place shift. Unfortunately, this way harms the spatial feature learning capacity of the backbone model. Specifically, the information stored in the shifted channels is lost for the current frame when shifting a large amount of channels. To keep spatial feature learning capacity,, TSM is put inside the residual branch in a residual block, it is denoted as residual shift.
虽然特征提取器使用ResNet-50主干进行建模,但直接的方法是通过在每个卷积层或残差块之前插入TSM来应用TSM。 这称为就地转换。 不幸的是,这种方式损害了骨干模型的空间特征学习能力。 具体地,当移动大量信道时,对于当前帧丢失存储在被移动的信道中的信息。 为了保持空间特征学习能力,将 TSM放在残差块的残差分支内,称为残差平移 。

Through experiments under different shift proportion settings, residual shift achieves better performance than in-place shift.
通过在不同移位比例设置下进行的实验, 残余移位比原位移位可获得更好的性能。
The inference graph of TSM video recognition is shown below. During inference phase, for each frame, the model saves the first 1/8 feature maps of each residual block and caches it in the memory. In the next frame, it then replaces the first 1/8 current feature maps by the cached feature maps.Indeed, TSM uses the combination of 7/8 current feature maps and 1/8 old feature maps to generate the next layer, and repeat. Using this technique for video content understanding offers two unique advantages: low latency inference and Multi-level fusion. First, the low latency inference, in which only 1/8 features need be cached, leads to low memory consumption. Second, Multi-level fusion helps improve temporal relationship.
TSM视频识别的推理图如下所示。 在推断阶段,对于每个帧,模型都会保存每个残差块的前1/8个特征图,并将其缓存在内存中。 在下一帧中,它将用缓存的要素图替换前1/8个当前要素图。实际上,TSM使用7/8当前要素图和1/8旧要素图的组合来生成下一层,并重复。 使用此技术进行视频内容理解具有两个独特的优势: 低延迟推理和多级融合。 首先,低延迟推断仅需要缓存1/8个功能,从而降低了内存消耗。 其次, 多级融合有助于改善时间关系。
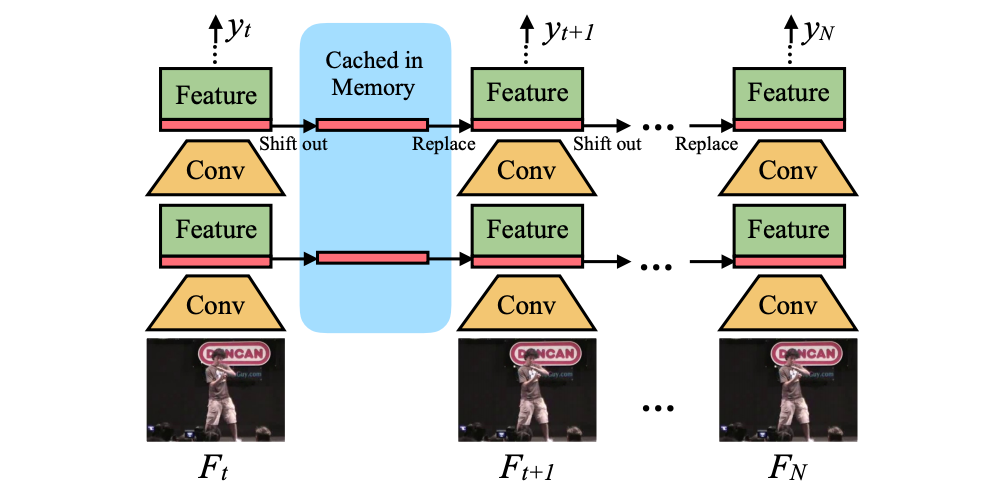
TSM for Basketball highlight extractionA full match video of Basketball normally contains around 180000 frames (90 minutes * 60 seconds * 30 fps). We split a video into equal segments and apply classification method for each to decide whether it is a highlight or not. Time duration of each segment is defined t second(t * 30 frames). We observe that although the frames are densely recorded in the segment, the content changes relatively slow. To reduce computational cost but still capture the long-range information over the short-partition video, classification operates on a sequence of n snippets uniformly sampled from the segment. Particularly, in our experiments, we choose t is 2 and n is 8 to perform the best result.
用于篮球精彩片段提取的TSM篮球的完整视频通常包含约180000帧(90分钟* 60秒* 30 fps)。 我们将视频分成相等的片段,然后对每个片段应用分类方法,以决定该片段是否为精彩片段。 每个段的持续时间定义为t秒(t * 30帧)。 我们观察到,尽管帧密集地记录在段中,但内容变化相对较慢。 为了降低计算成本,但仍能在短分区视频上捕获远程信息,分类对从片段中均匀采样的n个片段序列进行操作。 特别地,在我们的实验中,我们选择t为2且n为8来执行最佳结果。

Next, after sampling, a stacked frames is extracted by using ResNet50 combined with Temporal Shift Module. In this solution, we also utilize Non-local Neural Network [5], which computes the response, at each point, as weighted sum of the features at all positions in the input feature maps (equivalent to self-attention in image) to capture long-range dependencies. Interactions between any two positions are also computed. Next, the output of ResNet is flattened before the model is optimized by fully connected layers and Cross Entropy Loss.
接下来,在采样后,通过使用ResNet50和Temporal Shift Module组合来提取堆叠的帧。 在该解决方案中,我们还利用非局部神经网络[5]来计算每个点的响应,作为输入特征图中所有位置上的特征的加权总和(相当于图像中的自我注意)来捕获远程依赖关系。 还可以计算任意两个位置之间的相互作用。 接下来,在通过完全连接的层和交叉熵损失优化模型之前,对ResNet的输出进行展平。

In inference phase, after activation function, we obtain the temporal scoreline which is the probability of class highlight. Finally, highlight video is defined as a set of segments which score higher than defined threshold.
在推断阶段,在激活函数之后,我们获得了时间得分线 ,这是类突出显示的概率。 最后,精彩视频定义为得分高于定义阈值的一组片段。

Surprisingly, this proposed solution brings in a promising result in generation task. Given a full match video, this model is able to generate highlight video follows NBA standard (~9 minutes). In addition, we can control the length of output video by adjusting the decisive threshold. This technique may be used in the same problem for another sport such as football, cricket, …
令人惊讶地,该提出的解决方案在发电任务中带来了可喜的结果。 给定完全匹配的视频,此模型可以生成符合NBA标准的精彩视频(约9分钟)。 另外,我们可以通过调整决定性的阈值来控制输出视频的长度。 这项技术可用于足球,板球等其他运动的相同问题。
Github: https://github.com/BlueEye-AI/basketball-highlight-generator
GitHub: https : //github.com/BlueEye-AI/basketball-highlight-generator
References:[1]: https://papers.nips.cc/paper/5353-two-stream-convolutional-networks-for-action-recognition-in-videos.pdf[2]: https://arxiv.org/pdf/1705.02953.pdf[3]: https://arxiv.org/pdf/1412.0767.pdf[4]: https://arxiv.org/pdf/1811.08383.pdf[5]: https://arxiv.org/pdf/1711.07971.pdf
参考文献:[1]:https://papers.nips.cc/paper/5353-two-stream-convolutional-networks-for-action-recognition-in-videos.pdf [2]:https://arxiv.org /pdf/1705.02953.pdf[3]:https://arxiv.org/pdf/1412.0767.pdf[4]:https://arxiv.org/pdf/1811.08383.pdf[5]:https://arxiv。 org / pdf / 1711.07971.pdf
html设置模块偏移量















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









