







业务中为了避免重复数据的产生,除了在代码层级做处理之外,还会在数据库表中增加唯一索引来做最后的校验,项目中唯一索引在冲突的时候是以代码抛异常的形式来阻止脏数据的产生,而异常这个东西,说好也好,说不好也不好,因为在异常产生的时候,需要去还原错误场景并提供详细的错误信息,所以异常抛的太多了,性能肯定好不到哪里去,而且在有些特定的场景下甚至是不需要唯一索引的,当有重复的数据进来时,直接视作更新操作,查阅资料后发现,在MySQL中主键冲突一共有三种常用的解决方案。
首先,准备一张test表,插入几条测试数据:
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`code` varchar(20) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`desc` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_general_ci;
INSERT INTO `test` (`code`, `name`, `desc`) VALUES ('aaa', 'aaa', 'aaa');
INSERT INTO `test` (`code`, `name`, `desc`) VALUES ('bbb', 'bbb', 'bbb');
INSERT INTO `test` (`code`, `name`, `desc`) VALUES ('fff', 'fff', 'fff');
一、replace into
replace into table_name(col_name, ...) values(...)
与insert into一样,都是向表中插入数据,如果表中没有冲突的数据,直接执行insert操作;如果有唯一约束冲突时,会先删除老数据,然后再执行insert操作,而且列不全的情况下,未指定value的列在插入时会设置为默认值。
如下sql,会将第三条数据更新掉
REPLACE INTO `test` (`id`, `code`, `name`, `desc`) VALUES ('3', 'ccc', 'ccc', 'ccc');
查看执行结果:
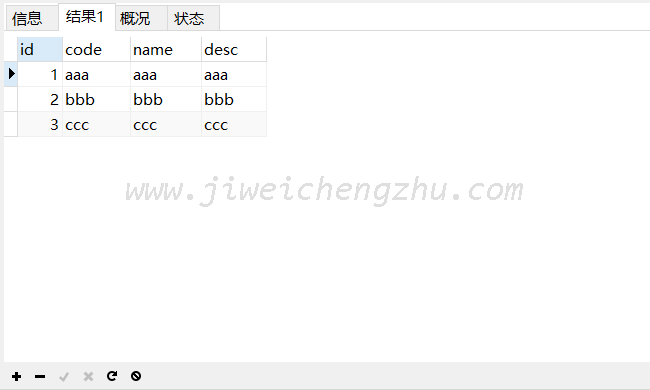
受影响的行: 2,验证了我们上面所说的:先删除 -> 再插入

如下sql,也会将第三条数据更新掉:
REPLACE INTO `test` (`id`, `code`) VALUES ('3', 'sss');
执行结果:
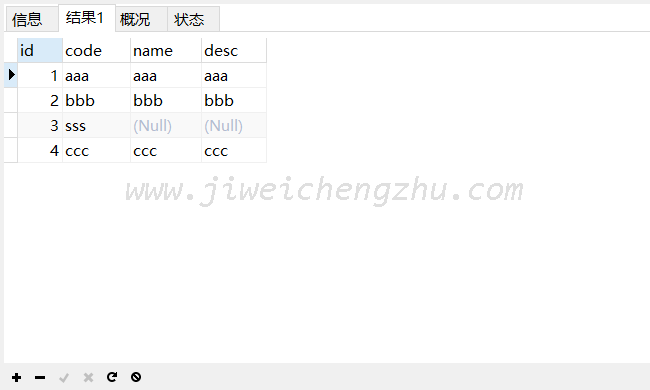
上图可以看出,如果列不全,replace的时候会填充默认值,其实跟insert一样的,也没什么好说的,在使用的时候注意别写漏了就行。
二、insert into on duplicate key update
insert into table_name(col_name, ...) values(...) on duplicate key update ...
与replace类似的功能,存在就更新,不存在则新增,具体执行逻辑如下所示:
IF (SELECT * FROM where 存在) {
UPDATE SET WHERE ;
} else {
INSERT INTO;
}
如下sql,会将第三条数据更新掉:
INSERT INTO `test` (`id`, `code`, `name`, `desc`) VALUES ('3', 'ooo', 'ooo', 'ooo')
ON DUPLICATE KEY
UPDATE `code` = 'www', `name` = 'www', `desc` = 'www';
这个写法相当的别扭,大家猜猜上面的写法,最后到底是什么值?
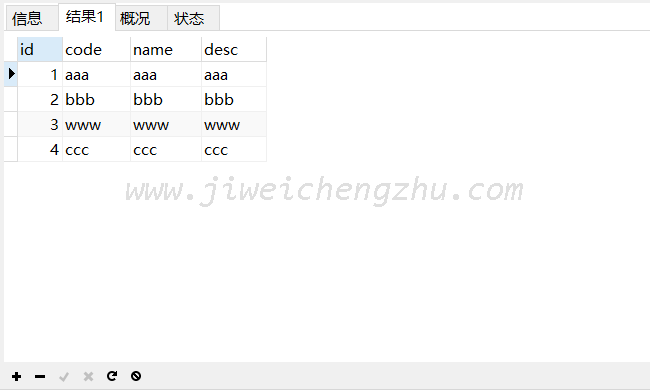
最终保存的值是update的数据,也就是说,唯一索引冲突之后,保存的数据只是update的部分,前面insert中的并不会保存,但insert中的值不可以省略,只可以简写,需要带有唯一的key
INSERT INTO `test` (`id`) VALUES ('3')
ON DUPLICATE KEY
UPDATE `code` = 'www', `name` = 'www', `desc` = 'www';
简写的sql中,id是我的key,主键唯一索引,所以后面的code、name、desc可以不用写了,直接将值放到update中,等同于update语句:
UPDATE `test` SET `code` = 'www', `name` = 'www', `desc` = 'www' WHERE id = 3;
三、ignore
insert ignore into table_name(col_name, ...) values(...)
忽略冲突,不报错,也不插入,相当于啥也不干,反正不管你怎么折腾,我就是不报错、不崩溃,一只可用。
如下sql:
INSERT IGNORE INTO `test` (`id`, `code`, `name`, `desc`) VALUES ('3', 'ooo', 'ooo', 'ooo');
在insert和into之间增加了一个ignore字符,效果如何呢?

受影响的行: 0,没有做任何的改动
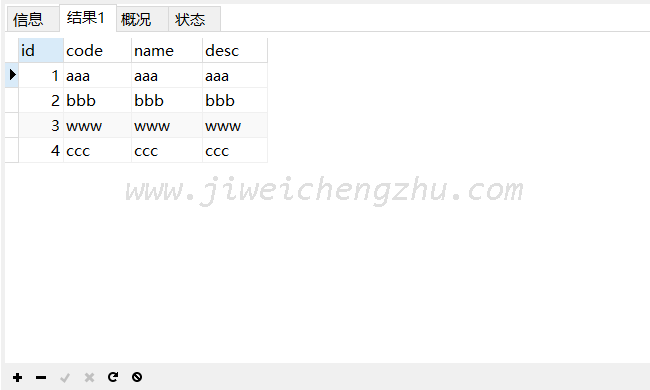
第三条数据依旧还是www,没有变成ooo,sql执行也没有任何的报错!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









