







简介:本项目通过C语言构建一个简单的学生信息管理系统,该系统实现存储、查询、修改和删除学生信息的功能。介绍了数据结构、文件操作、I/O处理、动态内存分配、结构体指针、循环与条件语句、函数使用、错误处理、排序算法以及用户界面的设计与实现。项目不仅巩固了C语言基础,也涉及了软件工程中的模块化和数据管理概念。 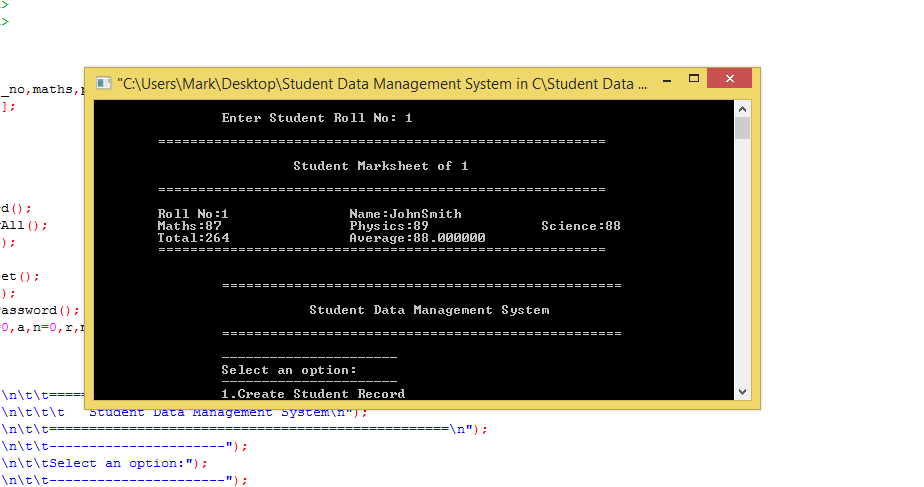
1. C语言项目介绍
1.1 项目背景与目的
在第一章中,我们将首先对整个C语言项目进行一个概览性的介绍。这里将详细解释项目的背景故事,以及设计与开发该C语言项目的目的。它可能是为了解决某个具体的业务问题,比如学生信息管理,或者作为一个教学示例,帮助初学者理解如何从零开始构建一个实用的软件。
1.2 项目范围与功能要求
紧接着,我们会对项目的范围进行划定,明确项目的边界和功能要求。比如,学生信息管理系统可能需要处理学生的增删改查操作、成绩管理、课程信息维护等基本功能。这一部分将确保读者对项目的功能有一个清晰的认识,并建立起后续章节中各功能实现的期望。
1.3 技术选型与开发环境
为了顺利地完成项目开发,技术选型至关重要。在本章节的最后,我们会详细介绍项目的技术选型,包括使用的编程语言版本、开发工具和第三方库等。同时,也会简述开发环境的搭建步骤,如配置编译器、运行必要的软件等,以确保所有读者都能快速开始项目的实践操作。
2. 数据结构设计与文件操作实现
在现代软件开发中,合理设计数据结构是保证软件质量与性能的关键。本章节深入探讨在C语言项目中数据结构的设计以及如何通过文件操作来实现数据的持久化存储。
2.1 数据结构设计(结构体)
2.1.1 结构体的基本概念和定义
在C语言中,结构体是一种复合数据类型,它允许将不同类型的数据项组合成一个单一类型。结构体在项目中用于模拟现实世界中的复杂对象,如学生信息管理系统中的学生信息。
typedef struct {
char name[50];
int age;
char gender;
float score;
} Student;
在这段代码中,定义了一个名为 Student 的结构体,其中包含四个字段: name 、 age 、 gender 和 score ,它们分别用于存储学生的名字、年龄、性别和分数。这样的结构体设计使得数据的组织和管理变得更为方便。
2.1.2 结构体在项目中的应用场景分析
结构体是组织复杂数据的有效方式。在学生信息管理系统中,每个学生的信息都需要被组织成结构体的形式,以便于程序对这些数据进行操作。例如,程序可以创建一个 Student 类型的数组,来存储多个学生的信息。
#define MAX_STUDENTS 100
Student students[MAX_STUDENTS];
在上述代码中,定义了一个大小为100的 Student 数组 students ,用于存储最多100名学生的信息。这不仅提高了数据处理的效率,而且由于结构体具有良好的封装性,使得代码的可读性和可维护性大大增强。
2.2 文件操作实现
2.2.1 C语言中的文件操作基础
C语言提供了一套标准的文件操作库 <stdio.h> ,支持文件的创建、打开、读写和关闭操作。在学生信息管理系统中,文件操作用于实现数据的持久化存储,以便于系统重启后依然能够访问之前存储的数据。
FILE *filePtr;
filePtr = fopen("students.txt", "a+");
if (filePtr == NULL) {
perror("Failed to open file");
exit(1);
}
在上述代码段中,尝试以追加加读模式( a+ )打开一个名为 students.txt 的文件。如果文件打开失败,则会打印错误信息并退出程序。
2.2.2 如何在学生信息管理系统中实现数据的持久化
在学生信息管理系统中,通过将学生信息存储到文件中来实现数据的持久化。当用户添加新的学生信息时,程序将这条信息追加到文件的末尾。下面是一个示例代码片段:
void writeStudentToFile(Student student) {
FILE *filePtr = fopen("students.txt", "a+");
if (filePtr != NULL) {
fprintf(filePtr, "%s %d %c %.2f\n", student.name, student.age, student.gender, student.score);
fclose(filePtr);
} else {
perror("Failed to open file");
}
}
上述代码定义了一个函数 writeStudentToFile ,它接受一个 Student 类型的参数,并将该学生的信息追加到 students.txt 文件中。首先尝试以追加模式打开文件,如果成功则使用 fprintf 将学生信息写入文件,然后关闭文件。如果文件无法打开,则会打印出错误信息。
通过文件操作,我们可以确保即便在程序关闭后,学生信息也不会丢失,下次程序运行时可以读取这些信息并继续使用。这样既保证了数据的安全性,也提高了系统的可用性和可靠性。
3. 输入/输出(I/O)处理与动态内存管理
3.1 输入/输出(I/O)处理
3.1.1 标准输入输出的使用方法
在C语言中,标准输入输出函数是 stdio.h 库中定义的一组函数,用于在程序和外部环境之间进行数据的输入和输出。最常用的函数包括 printf() 、 scanf() 和 gets() 。
-
printf()函数用于向标准输出(通常是屏幕)打印格式化的数据。 -
scanf()函数用于从标准输入(通常是键盘)读取格式化的输入。 -
gets()函数用于读取一行字符串直到遇到换行符。
下面是一个简单的代码示例,展示了如何使用这些函数:
#include <stdio.h>
int main() {
int age;
char name[100];
printf("请输入您的姓名和年龄:");
scanf("%s %d", name, &age); // 读取字符串和整数
printf("您输入的名字是:%s\n", name);
printf("您输入的年龄是:%d\n", age);
char line[256];
printf("请输入一行文本:");
gets(line); // 读取一行文本
printf("您输入的文本是:%s\n", line);
return 0;
}
在使用这些函数时,需要注意正确地格式化字符串。例如, %s 用于读取字符串, %d 用于读取整数。同时, scanf() 和 gets() 在读取字符串时需要确保目标数组有足够的空间来存储输入的数据,以避免缓冲区溢出。
3.1.2 文件I/O操作的进阶技巧
文件I/O是将数据存储在外部文件中的操作,涉及的函数有 fopen() 、 fclose() 、 fread() 、 fwrite() 、 fprintf() 、 fscanf() 等。
-
fopen()用于打开文件,fclose()用于关闭文件。 -
fread()和fwrite()用于读写二进制数据。 -
fprintf()和fscanf()用于格式化的文件读写。
例如,创建一个文件并写入一些数据:
#include <stdio.h>
int main() {
FILE *file;
char data[] = "Hello, World!\n";
file = fopen("example.txt", "w"); // 打开文件用于写入
if (file == NULL) {
perror("Error opening file");
return -1;
}
fprintf(file, "%s", data); // 写入字符串到文件
fclose(file); // 关闭文件
return 0;
}
在进行文件操作时,确保在操作完成后关闭文件,以释放系统资源。使用 fopen() 时,指定正确的模式(如"r"读取,"w"写入,"a"追加等)也是非常关键的。
3.2 动态内存管理
3.2.1 动态内存分配与释放的基本原理
C语言提供了一组动态内存分配函数,如 malloc() , calloc() , realloc() 和 free() ,这些函数在 stdlib.h 中定义。动态内存分配允许程序在运行时分配内存,根据需要动态地创建和销毁数据结构。
-
malloc()用于分配指定字节大小的内存。 -
calloc()类似于malloc(),但会将内存初始化为零。 -
realloc()用于改变之前分配的内存块的大小。 -
free()用于释放动态分配的内存。
下面是一个使用 malloc() 分配内存的例子:
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr = (int*)malloc(10 * sizeof(int)); // 分配一个包含10个整数的数组
if (arr == NULL) {
printf("Memory allocation failed!\n");
return -1;
}
// 使用arr数组...
free(arr); // 释放分配的内存
return 0;
}
正确地使用动态内存,需要确保为每个分配的内存块调用 free() 来释放内存。忘记释放内存会导致内存泄漏,这是C语言程序中最常见的错误之一。
3.2.2 如何在学生信息管理系统中合理使用动态内存
在学生信息管理系统中,动态内存管理可以用来处理数量不确定的学生记录。系统可以使用动态内存来存储学生信息数组,并根据需要调整其大小。
例如,下面的代码演示了如何使用 malloc() 和 realloc() 来管理学生信息的动态数组:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int id;
char name[50];
} Student;
int main() {
int numStudents = 10;
Student *students = (Student*)malloc(numStudents * sizeof(Student));
// 添加学生信息...
numStudents = 20; // 需要更多空间
students = (Student*)realloc(students, numStudents * sizeof(Student));
if (students == NULL) {
perror("Failed to reallocate memory");
free(students); // 即使失败,也应该释放原始内存
return -1;
}
// 继续使用students数组...
free(students); // 使用完毕后释放内存
return 0;
}
在实际应用中,动态内存管理需要注意内存泄漏、指针悬挂等问题。例如,在动态数组使用完毕后,必须调用 free() 释放内存。在管理复杂的数据结构如链表或树时,也需要仔细地管理每个节点的内存分配和释放。
4. 结构体指针与循环/条件语句
4.1 结构体指针应用
4.1.1 结构体指针的定义和使用
在C语言中,结构体指针是一种特殊的数据类型,它能够存储结构体变量的地址。通过结构体指针,我们能够更加灵活地处理复杂的结构体数据,并有效地访问结构体的各个成员。定义一个结构体指针的基本语法如下:
struct 结构体类型名 *结构体指针变量名;
一旦定义了结构体指针,就可以通过“->”操作符来访问指向的结构体变量的成员。例如:
struct Student {
char name[50];
int age;
float score;
};
int main() {
struct Student *ptr;
struct Student student = {"John Doe", 20, 92.5};
ptr = &student; // 将结构体变量的地址赋值给结构体指针
printf("Student Name: %s\n", ptr->name); // 使用结构体指针访问成员
printf("Student Age: %d\n", ptr->age);
printf("Student Score: %.2f\n", ptr->score);
return 0;
}
在上面的代码中, ptr 是一个指向 Student 结构体的指针,我们通过 ptr->name 、 ptr->age 和 ptr->score 来访问结构体中定义的成员变量。
结构体指针在项目中的应用非常广泛,特别是在需要操作大量结构体数据的情况下。例如,在一个学生信息管理系统中,使用结构体指针可以高效地遍历学生数组,或者在函数中直接操作结构体成员,而无需复制整个结构体变量。
4.1.2 指针在学生信息管理系统中的高级应用
在学生信息管理系统中,我们可以通过结构体指针实现很多高级功能。例如,通过指针传递结构体变量的地址到函数中,可以实现对学生信息的修改,同时这种传递方式也更加高效,因为它仅传递地址而不是整个结构体的复制。
void updateStudent(struct Student *ptr, char *newName, int newAge, float newScore) {
strcpy(ptr->name, newName);
ptr->age = newAge;
ptr->score = newScore;
}
int main() {
struct Student student = {"Alice Smith", 19, 89.5};
updateStudent(&student, "Alice Brown", 20, 95.0);
printf("Updated Student Name: %s\n", student.name);
printf("Updated Student Age: %d\n", student.age);
printf("Updated Student Score: %.2f\n", student.score);
return 0;
}
在上述例子中, updateStudent 函数通过一个结构体指针来更新学生信息。这种方式使得函数调用更加灵活,并能够直接操作调用者提供的数据。
结构体指针另一个高级应用是在链表数据结构中的使用。链表是一种动态数据结构,通过使用结构体指针,我们可以创建包含多个节点的链表,每个节点存储一个数据项,并通过指针连接下一个节点。这种数据结构特别适合于学生信息管理系统,因为它可以根据需要动态地增加或删除学生信息节点。
4.2 循环与条件语句运用
4.2.1 循环语句的多种用法及其在项目中的实践
循环语句在C语言程序设计中扮演着重要角色。它们允许我们重复执行代码块直到满足特定条件。最常用的循环结构包括 for 循环、 while 循环和 do-while 循环。每种循环都有其特定的使用场景和优势。
for 循环通常用于已知循环次数的情况,其语法如下:
for (初始化表达式; 循环条件表达式; 迭代表达式) {
// 循环体
}
while 循环适用于不确定循环次数,只要条件为真就继续循环的情况:
while (条件表达式) {
// 循环体
}
do-while 循环则至少执行一次循环体,之后再判断条件表达式:
do {
// 循环体
} while (条件表达式);
在学生信息管理系统中,循环语句的运用非常广泛。例如,我们可能需要遍历一个学生数组,打印每个学生的信息。这可以通过 for 循环来完成:
struct Student students[5] = {
{"John Doe", 20, 90.5},
{"Jane Smith", 19, 92.5},
// ... 其他学生信息
};
for (int i = 0; i < 5; ++i) {
printf("Student %d Name: %s\n", i + 1, students[i].name);
printf("Student %d Age: %d\n", i + 1, students[i].age);
printf("Student %d Score: %.2f\n\n", i + 1, students[i].score);
}
对于动态数据结构,如链表, while 或 do-while 循环可能更适合于遍历节点:
struct Node {
struct Student data;
struct Node *next;
};
void printStudents(struct Node *head) {
while (head != NULL) {
printf("%s %d %.2f\n", head->data.name, head->data.age, head->data.score);
head = head->next;
}
}
4.2.2 条件语句的深入分析和在信息管理中的应用
条件语句允许我们根据条件执行不同的代码分支。C语言中最常用的条件语句是 if 、 else if 、 else 和 switch 语句。它们使得程序能够根据不同的条件执行不同的操作。
if 语句的基本语法如下:
if (条件表达式) {
// 条件为真时执行的代码
}
else if 和 else 用于在多个条件下进行选择:
if (条件表达式1) {
// 条件1为真时执行的代码
} else if (条件表达式2) {
// 条件2为真时执行的代码
} else {
// 所有条件都不为真时执行的代码
}
switch 语句通常用于处理多个固定选项的情况:
switch (表达式) {
case 常量表达式1:
// 当表达式的值与常量表达式1相等时执行的代码
break;
case 常量表达式2:
// 当表达式的值与常量表达式2相等时执行的代码
break;
// ... 其他case
default:
// 默认情况下执行的代码
}
在学生信息管理系统中,条件语句可用于实现诸如搜索、排序或修改学生信息等功能。例如,我们可以编写一个函数来查找具有特定姓名的学生信息:
struct Student* findStudentByName(struct Student students[], int size, char *name) {
for (int i = 0; i < size; ++i) {
if (strcmp(students[i].name, name) == 0) {
return &students[i];
}
}
return NULL; // 如果没有找到,返回NULL
}
在上面的代码中,通过 if 条件语句来判断遍历到的学生信息是否与我们要搜索的学生姓名相符。如果找到,返回对应的结构体指针;如果没有找到,返回 NULL 。
条件语句还可以与循环结构结合使用,例如,实现一个对学生信息按照成绩排序的功能:
void sortStudents(struct Student students[], int size) {
for (int i = 0; i < size - 1; ++i) {
for (int j = 0; j < size - i - 1; ++j) {
if (students[j].score < students[j + 1].score) {
struct Student temp = students[j];
students[j] = students[j + 1];
students[j + 1] = temp;
}
}
}
}
在这个排序函数中,我们使用了两个嵌套的 for 循环,并在循环体内使用 if 语句来判断两个相邻学生的信息,并根据成绩进行排序。
条件语句在学生信息管理系统中的应用非常重要,它们使得程序能够根据不同的数据情况执行不同的逻辑流程,从而实现更加丰富和动态的功能。
5. 函数模块化设计与错误处理机制
5.1 函数的模块化设计
5.1.1 函数模块化设计的原则和好处
模块化设计是指将一个复杂系统分解为若干个模块,每个模块实现一组相对独立的功能,并且模块之间的耦合度尽可能低。在C语言项目中,函数是实现模块化的最基本单位。函数模块化设计应遵循以下原则:
- 单一职责 :每个函数只做一件事情,这样做的好处是易于理解和测试,当出现错误时也更容易定位问题。
- 接口清晰 :函数的输入输出应该明确,减少全局变量的使用,以便于维护和复用。
- 解耦合 :函数间不应有太多直接依赖,应通过参数和返回值进行交互,以降低模块间的耦合度。
函数模块化设计的好处包括:
- 提高代码的可读性 :清晰的模块划分使得其他开发者更容易理解代码的逻辑。
- 便于维护和修改 :单个模块的修改不会影响到其他模块,便于后续的维护和升级。
- 便于测试 :模块化使得每个函数可以单独测试,提高代码的可测试性。
5.1.2 如何设计学生信息管理系统的功能模块
在设计学生信息管理系统的功能模块时,我们需要根据系统的需求分析,拆分成多个模块,并定义每个模块的职责。以下是一些主要模块的示例:
- 数据输入模块 :负责录入学生信息,包括姓名、年龄、性别、学号等。
- 数据存储模块 :将录入的学生信息存储到文件或数据库中。
- 数据检索模块 :根据不同的条件(如学号、姓名)检索学生信息。
- 数据更新模块 :允许对已存储的学生信息进行更新。
- 数据删除模块 :提供删除学生信息的功能。
- 用户界面模块 :提供一个简单的文本用户界面,供用户与系统交互。
对于每个模块,我们定义一个或多个函数来实现其功能。例如,在数据输入模块中,我们可以设计以下函数:
void EnterStudentInfo();
void SaveStudentInfoToFile();
其中 EnterStudentInfo 函数用于获取用户输入的学生信息,并通过调用 SaveStudentInfoToFile 函数将数据持久化。
5.2 错误处理机制
5.2.1 错误处理的重要性及实现方法
在C语言开发中,错误处理是保证程序健壮性的关键步骤。良好的错误处理机制能够帮助开发者快速定位问题,同时为用户提供更友好的交互体验。错误处理应该遵循以下原则:
- 提前检测 :在函数入口处检查输入参数是否合法。
- 及时反馈 :对于无法处理的错误,应该立即返回错误码或错误信息。
- 容错处理 :对于非致命错误,应该提供备选方案,保证程序能够继续运行。
错误处理的实现方法主要包括:
- 返回错误码 :函数返回一个整数表示执行结果,0表示成功,非0值表示错误。
- 设置全局错误变量 :定义一个全局变量来存储错误码或错误信息。
- 日志记录 :将错误信息记录到日志文件中,便于问题的追踪和分析。
5.2.2 错误处理在项目中的具体应用实例
在学生信息管理系统中,我们可以通过返回错误码的方式实现错误处理。例如:
int SaveStudentInfoToFile(StudentInfo *info) {
// 检查文件是否可以打开
FILE *file = fopen("students.dat", "a");
if (file == NULL) {
return -1; // 文件无法打开,返回错误码
}
// 将学生信息写入文件
if (fwrite(info, sizeof(StudentInfo), 1, file) != 1) {
fclose(file);
return -2; // 写入文件失败,返回错误码
}
fclose(file);
return 0; // 成功,返回0
}
在这个例子中, SaveStudentInfoToFile 函数尝试将学生信息写入到文件中,如果文件无法打开或写入失败,函数将返回相应的错误码。在调用此函数的地方,我们需要检查返回值并据此处理错误:
StudentInfo newStudent;
// 填充newStudent的信息
if (SaveStudentInfoToFile(&newStudent) != 0) {
// 处理错误,例如记录日志或提示用户错误信息
}
通过这种方式,我们可以确保程序在遇到错误时能够及时响应,并提供足够的信息帮助开发者或用户理解问题所在。
6. 排序算法应用与命令行用户界面设计
在前几章中,我们详细探讨了数据结构的设计、文件操作、I/O处理、动态内存管理、结构体指针以及函数模块化等关键知识点。本章我们将聚焦于排序算法的应用,并深入探讨如何设计命令行用户界面,以提供更友好、高效的操作体验。
6.1 排序算法应用
排序算法是数据管理中不可或缺的一部分,它能够帮助我们高效地组织数据,以便于检索和管理。在这一节中,我们将从排序算法的选择和优化开始,讨论它们在信息管理系统中的实际应用。
6.1.1 常见排序算法的选择与优化
选择合适的排序算法对于提高信息系统的性能至关重要。在学生信息管理系统中,根据数据的特点和处理需求,我们可以选择以下几种常见排序算法:
- 冒泡排序:适用于小规模数据集,简单易懂,但效率较低。
- 快速排序:适用于大规模数据集,平均情况下效率较高。
- 归并排序:稳定排序,适用于对稳定性有要求的情况。
- 堆排序:适用于优先队列等特定应用场景,时间复杂度为O(nlogn)。
- 插入排序:适合已基本有序的数据集,效率较高。
在实现排序时,为了优化性能,我们通常会考虑如下策略:
- 选择合适的基准元素或初始状态。
- 针对不同数据量和数据特点选择不同的排序算法。
- 采用递归或迭代的方式实现排序算法。
- 使用尾递归优化递归算法,减少栈空间的消耗。
6.1.2 排序算法在信息管理系统的实际应用
在学生信息管理系统中,排序算法可以应用于多种场景,例如:
- 按学号或姓名对学生的记录进行排序。
- 根据成绩对学生记录进行排序,以便于快速找出成绩优异或需要关注的学生。
- 在导出数据前,对记录进行排序以保证数据的有序性。
为实现上述功能,我们可以在系统中定义如下的排序函数:
void sortStudents(Student *students, int count) {
// 选择合适的排序算法
quickSort(students, 0, count - 1);
}
// 快速排序函数实现
void quickSort(Student *students, int left, int right) {
if (left >= right) return;
int pivot = partition(students, left, right);
quickSort(students, left, pivot - 1);
quickSort(students, pivot + 1, right);
}
// 快速排序中的划分函数
int partition(Student *students, int left, int right) {
// 省略具体实现
}
在上面的代码块中,我们展示了快速排序算法的核心部分。通过递归调用 quickSort 函数,我们可以高效地对学生数组进行排序。对于 partition 函数的具体实现细节,请参考本章末尾的参考资料,这里仅展示了函数的原型和调用关系。
6.2 命令行用户界面设计
命令行用户界面(CLI)是用户与信息管理系统交互的重要方式。良好的CLI设计能够极大提升用户体验,使得操作更加直观、简便。本节将讨论如何设计清晰易用的CLI以及如何提升其交互性。
6.2.1 设计清晰易用的命令行界面
在设计CLI时,我们需要考虑以下要点:
- 明确的指令结构 :每个指令应当有清晰的语法和格式说明,易于用户理解和记忆。
- 合理的提示信息 :在用户操作过程中,应提供适时的提示信息,帮助用户完成操作。
- 错误处理 :对于用户的错误输入或操作,应当有友好的错误提示和帮助信息。
- 快速响应 :系统应当能够快速响应用户输入,避免用户长时间等待。
为了实现上述要求,我们可以在学生信息管理系统中定义一个简单的CLI框架:
void displayMenu() {
printf("1. 添加学生信息\n");
printf("2. 删除学生信息\n");
printf("3. 修改学生信息\n");
printf("4. 查询学生信息\n");
printf("5. 退出系统\n");
printf("请选择操作:");
}
int main() {
int choice;
do {
displayMenu();
scanf("%d", &choice);
switch (choice) {
case 1: addStudent(); break;
case 2: deleteStudent(); break;
case 3: updateStudent(); break;
case 4: queryStudent(); break;
case 5: printf("退出系统\n"); break;
default: printf("无效的选择,请重新输入。\n");
}
} while (choice != 5);
return 0;
}
在上面的代码块中,我们通过 displayMenu 函数显示一个简单的菜单,并通过 switch 语句处理用户的输入。这种方式虽然简单,但已经满足了清晰易用的基本要求。
6.2.2 如何提升用户界面的交互体验
为了提升CLI的交互体验,我们可以采取如下策略:
- 动态菜单提示 :根据用户的操作历史动态调整菜单选项,使其更加贴合用户的需求。
- 输入验证 :对用户的输入进行校验,确保数据的有效性和正确性。
- 快捷键 :为常见的操作提供快捷键,加快用户的操作速度。
- 用户配置文件 :允许用户自定义界面布局和行为,提供个性化的使用体验。
实现这些策略可能会涉及到更复杂的编程技术,如命令解析器的构建、输入验证的实现等。在实际的项目开发中,我们可以根据系统的规模和需求,逐步完善这些功能。
总结
通过本章节的介绍,我们深入了解了排序算法的应用场景及优化方法,并探索了设计高效、友好的命令行用户界面的策略。这些技能和知识对于开发一个实用、易用的学生信息管理系统至关重要。在下一章中,我们将通过综合实践,将本章以及前几章的知识点整合起来,完成一个完整的学生信息管理系统项目的开发。
7. 综合实践与项目总结
7.1 综合实践
7.1.1 将理论知识转化为实践能力
在将理论知识转化为实践能力的过程中,首先要确保对基本概念有深刻的理解。例如,在学生信息管理系统开发中,结构体和文件操作是关键,需要灵活掌握如何定义和操作结构体以及进行文件的读写操作。
接下来是分步骤实现复杂系统的能力。以学生信息管理系统为例,可以从实现基本的学生信息录入、查询、更新和删除功能开始,然后逐步添加排序、搜索等高级功能。
在实践过程中,代码的编写要遵循良好的编程规范,如使用有意义的变量名、保持代码格式整洁和注释清晰。例如,定义结构体时:
typedef struct {
char name[50];
int age;
char gender;
float gpa;
} Student;
在实现文件持久化时,要确保文件操作错误得到妥善处理:
FILE *file = fopen("students.dat", "rb");
if (file == NULL) {
perror("Error opening file");
exit(1);
}
7.1.2 创建和完善学生信息管理系统的实践过程
创建和完善学生信息管理系统的过程包括:
- 需求分析:确定系统需要实现哪些功能。
- 设计阶段:绘制流程图,设计数据库(如果需要)和数据结构。
- 编码实现:编写模块化的代码,实现每个功能点。
- 测试验证:对每个功能进行单元测试,并进行整体的系统测试。
- 用户反馈:让用户试用系统,根据反馈进行优化。
- 系统维护:对系统进行定期的更新和维护。
在此过程中,代码的优化和重构是提高代码质量和性能的关键步骤。例如,可以使用函数指针来动态选择不同的排序算法,提高程序的灵活性。
7.2 项目总结
7.2.1 回顾项目开发过程中的关键点
在项目开发的过程中,需要特别注意以下几点:
- 需求分析的准确性 :确保理解并实现了用户所需的所有功能。
- 系统设计的合理性 :合理的数据结构设计和文件布局是系统高效运行的基础。
- 代码质量的控制 :良好编码习惯和持续的代码审查可以保障代码质量。
- 测试的全面性 :系统的测试应尽可能全面,以确保发现并修复所有潜在问题。
7.2.2 对学生信息管理系统项目的整体评价与展望
学生信息管理系统作为一个教育行业的重要工具,其项目评价可以从以下几个维度进行:
- 功能性 :系统是否满足了教育管理者对学生信息管理的基本需求。
- 用户体验 :界面是否友好,操作是否简单直观。
- 系统性能 :系统是否能快速响应用户的操作请求,数据处理是否高效。
- 可维护性和扩展性 :系统是否易于维护,是否能根据未来需求进行扩展。
展望未来,学生信息管理系统可以集成更多现代化的技术,如云计算、大数据分析,为教育管理提供更多的决策支持。同时,可以考虑开发一个Web版或移动应用版本,以满足更多样化的使用场景。
简介:本项目通过C语言构建一个简单的学生信息管理系统,该系统实现存储、查询、修改和删除学生信息的功能。介绍了数据结构、文件操作、I/O处理、动态内存分配、结构体指针、循环与条件语句、函数使用、错误处理、排序算法以及用户界面的设计与实现。项目不仅巩固了C语言基础,也涉及了软件工程中的模块化和数据管理概念。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









