






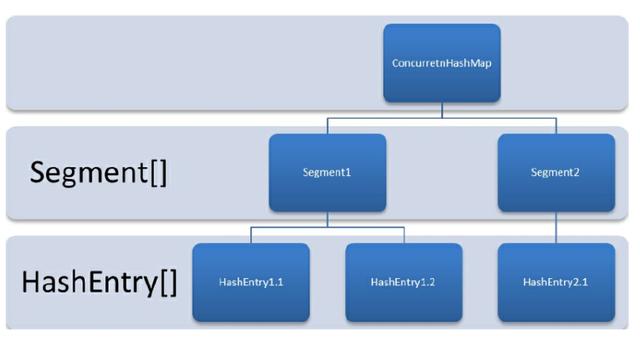
CocurrentHashMap 作用
HashTable通过对整张表加锁的方式实现并发hash查找与储存,CocurrentHashMapt通过Segment的方式可以实现相同的功能,不过效率更加高,在jdk1.6的时候,CocuentHashMap有弱一致性的问题,不过在jdk1.7的时候,这个问题已经修复了。所以是并发安全性还是性能都是非常高的。接下来我尝试基于jdk1.7的源码去分析CocurrentHashMap。
cocurrentHashMap 初始化预处理
// Unsafe mechanics private static final sun.misc.Unsafe UNSAFE; private static final long SBASE; private static final int SSHIFT; private static final long TBASE; private static final int TSHIFT; static { int ss, ts; try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class> tc = HashEntry[].class; Class> sc = Segment[].class; TBASE = UNSAFE.arrayBaseOffset(tc); SBASE = UNSAFE.arrayBaseOffset(sc); ts = UNSAFE.arrayIndexScale(tc); ss = UNSAFE.arrayIndexScale(sc); } catch (Exception e) { throw new Error(e); } if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0) throw new Error("data type scale not a power of two"); SSHIFT = 31 - Integer.numberOfLeadingZeros(ss); TSHIFT = 31 - Integer.numberOfLeadingZeros(ts); }
代码解析:首先获取Unsafe提供cas操作,java底层多线程并发都是通过cas完成的,不过cas操作对于高精度的并发还是存在一定问题。【至于这个问题,以后再分析】。UNSAFE.arrayBaseOffset(tc)和UNSAFE.arrayBaseOffset(sc)这两个都是用于计算HashEntry和Segment实体对象相对于数组对象的内存偏移值。这是cas操作必须要获取的值。
注释:
//获取数组中第一个元素的偏移量(get offset of a first element in the array) public native int arrayBaseOffset(java.lang.Class aClass); //获取数组中一个元素的大小(get size of an element in the array) public native int arrayIndexScale(java.lang.Class aClass); cocurrentHashMap 初始化
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] Segment s0 = new Segment(loadFactor, (int)(cap * loadFactor), (HashEntry[])new HashEntry,?>[cap]); Segment[] ss = (Segment[])new Segment,?>[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; }代码解析:以上代码主要的作用是初始化Segment[]数组对象以及Segment对象。解析来分析最重要的put和get方法。
put方法
public V put(K key, V value) { Segment s; if (value == null) throw new NullPointerException(); int hash = hash(key.hashCode()); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }代码解析:大体的意思是先计算出key的hash值,然后利用这个hash值得到Segment对象。然后Segment对象执行put方法。这样就完成了put操作。由于这个过程非常重要,我们肯定想要知道它是如何处理并发以及 内部实现。
ensureSegment
private Segment ensureSegment(int k) { final Segment[] ss = this.segments; long u = (k << SSHIFT) + SBASE; // raw offset Segment seg; if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) { Segment proto = ss[0]; // use segment 0 as prototype int cap = proto.table.length; float lf = proto.loadFactor; int threshold = (int)(cap * lf); HashEntry[] tab = (HashEntry[])new HashEntry,?>[cap]; if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck Segment s = new Segment(lf, threshold, tab); while ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) { if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; }首先计算出偏移量,然后利用UnSafe去获取对象。在这里有可能大家对这个偏移值的获取有点疑惑,在这里我也分析一下这个偏移量获取既long u=(k<
segment->put
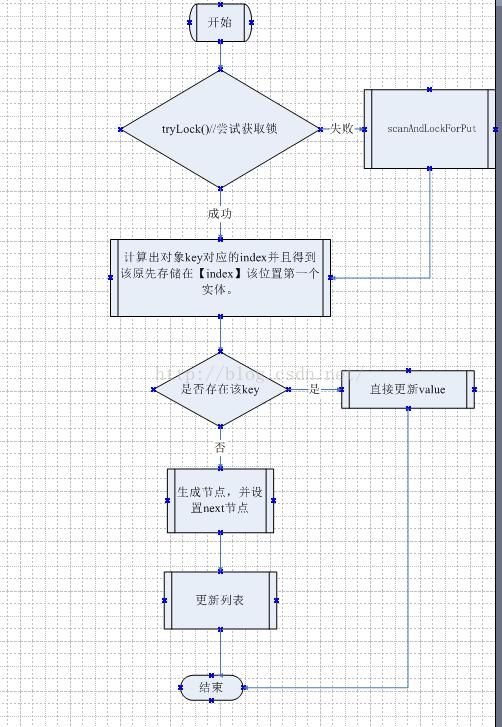
final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry[] tab = table; int index = (tab.length - 1) & hash; HashEntry first = entryAt(tab, index); for (HashEntry e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }以下画一个流程图:
get()
public V get(Object key) { Segment s; // manually integrate access methods to reduce overhead HashEntry[] tab; int h = hash(key.hashCode()); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }原理很简单先定位到segment,然后定位到实体。并且通过getObjectVolatie保证能够读到最新的数据。
总结:concurrentHashMap实现涉及到很多多线程的知识和java内存模型这方面的知识,如果没有足够的能力,介意不要模仿,但是我们可以学习它的思想以及是如何实现的。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









