







介绍
pyquery 可让你用 jQuery 的语法来对 xml 进行操作。这I和 jQuery 十分类似。如果利用 lxml,pyquery 对 xml 和 html 的处理将更快。
这个库不是(至少还不是)一个可以和 JavaScript交互的代码库,它只是非常像 jQuery API 而已。
安装
pip install pyquery
初始化
引入库:from pyquery import PyQuery as pq
1、直接字符串
doc = pq("") pq 参数可以直接传入 HTML 代码,doc 现在就相当于 jQuery 里面的 $ 符号了
2、lxml.etree
doc = pq(etree.fromstring(""))
可以首先用 lxml 的 etree 处理一下代码,这样如果你的 HTML 代码出现一些不完整或者疏漏,都会自动转化为完整清晰结构的 HTML代码。
3、直接传URL
doc = pq('http://www.baidu.com')
这里就像直接请求了一个网页一样,类似用 urllib2 来直接请求这个链接,得到 HTML 代码
4、传文件
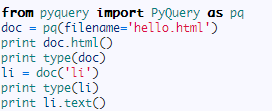
doc = pq(filename='hello.html')
可以直接传某个路径的文件名。
快速体验
现在我们以本地文件为例,传入一个名字为 hello.html 的文件,文件内容为:

运行结果:
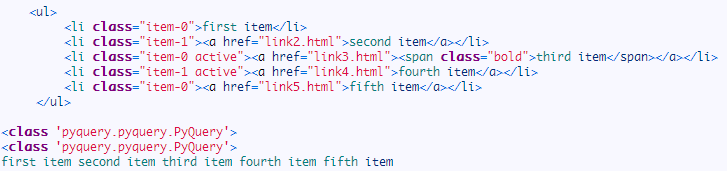
在这里我们注意到了一点,PyQuery 初始化之后,返回类型是 PyQuery,利用了选择器筛选一次之后,返回结果的类型依然还是 PyQuery,这简直和 jQuery 如出一辙,不能更赞!
然而想一下 BeautifulSoup 和 XPath 返回的是什么?列表!一种不能再进行二次筛选(在这里指依然利用 BeautifulSoup 或者 XPath 语法)的对象!
属性操作
你可以完全按照 jQuery 的语法来进行 PyQuery 的操作
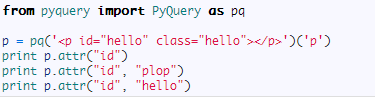
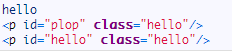
运行结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









