







本文主要介绍了流式数据处理的使用场景、相关技术(flink),并从服务管理的角度,基于锋刃介绍了针对流式计算服务的服务目录设计及关键指标。主要面向的读者为希望了解流式计算、服务管理的朋友。
1.流式计算的使用场景
首先,当前业界已经有非常多数据处理的方式了,为什么还需要流式数据处理?要回答这个问题,我们先回顾一下传统的的数据处理架构。
传统的数据处理架构是一种典型的以数据库为中心,适应存储事务性数据处理的场景。由于数据处理能力优先,在该架构下,往往数据都是以批量的方式进行处理,例如:批量写入数据库、批量读取数据库进行数据处理。这种架构在面对实时性较低的场景中较为有效,但是在对实时性较高的场景则不太有效,例如:自动驾驶场景、工业机器人场景、基于会话的用户统计等。
因此,流式计算或流式数据处理被提出。其实流处理它最接近数据产生的自然规律,只不过过去我们没有流处理能力,只能做一些特殊的处理才能真正地使用流数据,比如将流数据攒成批量数据再处理,不然无法进行大规模的计算。使用流数据并不新鲜,新鲜的是我们有了新技术,从而可以大规模、灵活、自然和低成本地使用它们。
流式处理的核心目标有以下三点:
- 低延迟:近实时的数据处理能力
- 高吞吐:能处理大批量的数据
- 可以容错:在数据计算有误的情况下,可容忍错误,且可更正错误
2.流处理框架
典型的流处理框架结合了消息传输层技术以及流处理层技术。具体如图所示:
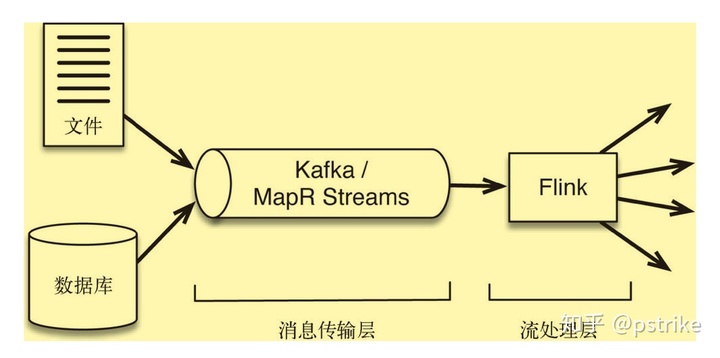
消息传输层的引入流处理层提供了以下支持:
- 消息传输层的一个作用是作为流处理层上游的安全队列,它相当于缓冲区,可以将事件数据作为短期数据保留起来,以防数据处理过程发生中断
- 具有持久性的好处之一是消息可以重播
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









