







描述统计主要讲述数据分布的集中趋势、离散程度和相关分析。下面主要讲一下集中趋势和离散程度的度量中最常用的部分,以及数据集字段的分析。
集中趋势
中位数
四分位数
- 下四分位数
- 上四分位数
平均数
简单平均数 根据未经分组数据计算的平均数称为简单平均数。
加权平均数 根据分组数据计算的平均数称为加权平均数。设原始数据分为k组,各组组中值分别用
组中值 分组数据中各组数据的上下限之间的中点数值=(上限+下限)
只有上限的开口组组中值=上限-
只有下限的开口组组中值=下限+
此外,还有众数
离散程度
异众比率
方差
标准差=
离散系数(变异系数)
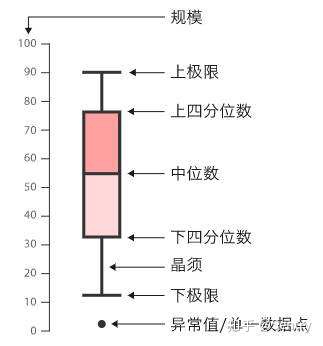
箱形图
描述统计中一种可以直观体现数据分散情况的统计图,可以显示出一种数据种的最大值、最小值、中位数、上四分位数、下四分位数和异常值。
数据集字段分析
以以下的婴儿用品数据为例Baby Goods Info Data
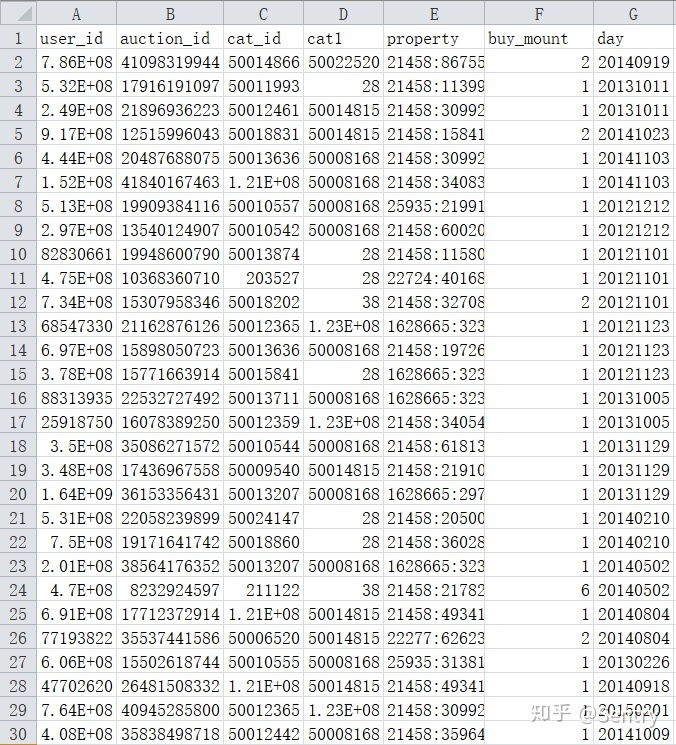
user_id:用户id 可以对具体某一个用户的购买信息进行追踪,用处不大。
auction_id:购买行为编号 用户购买行为的单独标识编号,用于细化处理数据,用处不大。
cat_id:商品种类ID,cat1:商品属于哪个类别 我们可以利用excel对cat_id和cat1进行计数,算出被购买商品的众数,分析出哪种商品最受欢迎,哪种商品最不受欢迎,然后作出增加或减少进货量的策略。
property:商品属性 反映商品的大小/尺码/品牌 算出property的众数,可以显示出这些商品的大小、尺码对消费者决策的影响。
buy_mount:购买数量 反映商品真实的销售情况,根据频数的大小可以判断商品的销量。
day:购买时间 根据购买时间和购买数量,可以分析商品是否有季节性的需求,是否有回头客,促销时间商品销量是否有显著增长,促销计划是否成功。
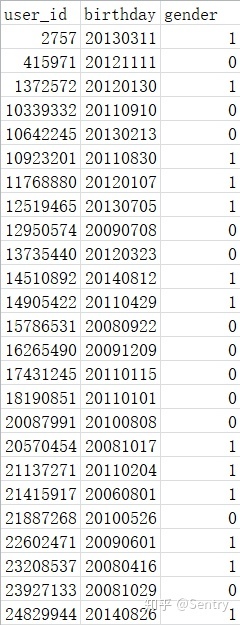
user_id:婴儿用户id 对应上一张购买用户(家长)的使用用户(婴儿)。
birthday:出生日期 可用于分析各年龄段婴儿对某种商品的需求。
gender:性别(0 男性;1 女性)可用于判断对某种商品的需求在性别上是否存在显著差异。
探讨具体问题
1.2014年双十一当天某品牌商品的促销活动是否成功?
用到的数据:(sample)sam_tianchi_mum_baby_trade_history.csv)中的cat_id、buy_mount、day。
使用数据day数据筛选出2014年11月11日当日的数据,使用数据cat_id根据目标商品的代码筛选出当天该商品的购买记录,再通过数据buy_mount进行计数,最后与该商品2014年11月的平均日销量进行比较。(同样用到上面三个数据)
2.比较男女婴儿对某商品的需求是否存在差异。
用到的数据:(sample)sam_tianchi_mum_baby_trade_history.csv)中的user_id、cat_id、buy_mount、(sample)sam_tianchi_mum_baby.csv中的user_id、gender。
根据user_id合并(sample)sam_tianchi_mum_baby_trade_history.csv和(sample)sam_tianchi_mum_baby.csv两张表。使用数据cat_id根据该商品的代码筛选出其购买记录,再通过数据buy_mount和gender算出男女婴儿的家长购买该商品的频数。
3.比较两个不同商品类别的月销量差异。
用到的数据:(sample)sam_tianchi_mum_baby_trade_history.csv)中的cat1、buy_mount、day。
使用数据cat1筛选出两个不同商品类别的数据,使用数据day和buy_mount计算出两个不同商品类别在各个月的销量,然后作比较。
统计学复习知识摘自《统计学》,作者贾俊平














 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









