







| pandas数据清洗-删除没有序号的所有行的数据 |
问题:我的数据如下, 要求:我想要的是:有序号的行留下,没有序号的行都不要
|
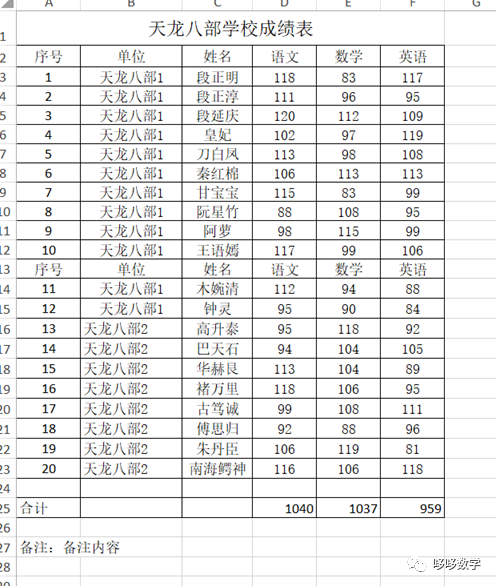
【代码及解析】
import pandas as pd filepath="E:/yhd_python/pandas.read_excel/student.xlsx" df=pd.read_excel(filepath,sheet_name='Sheet1',skiprows=1) df.tail() 先导入pands包,用read_excel读取文件,工作表为“Sheet1”,标题在第二行,所以跳过一行skiprows=1方法:read_excel pd.read_excel(io,sheetname=0, header=0, skiprows=None, index_col=None,names=None,arse_cols=None,date_parser=None,na_values=None,thousands=None,convert_float=True,has_index_names=None,converters=None,dtype=None, true_values=None,false_values=None,engine=None,squeeze=False,**kwds) sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 header :指定作为列名的行,默认0,即取第一行 skiprows:省略指定行数的数据 skip_footer:省略从尾部数的行数据**继续** lst=[] for index,row in df.iterrows(): if type(row[0])!=int: lst.append(index) lst 定义一个空列表,用于存储第一列中数据类型不是int的的行号方法:iterrows() 是在数据框中的行进行迭代的一个生成器,它返回每行的索引及一个包含行本身的对象。 所以,当我们在需要遍历行数据的时候,就可以使用 iterrows()方法实现了。 df1=df.drop(labels=lst) 删除l列表lst存储的所有行号 |
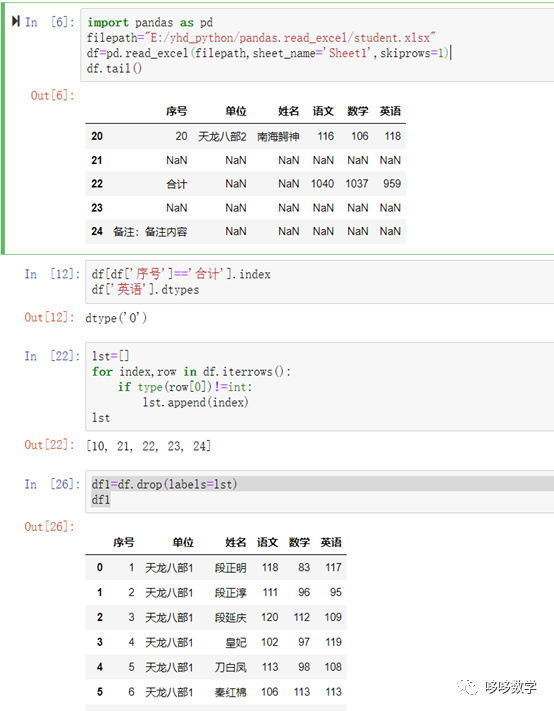
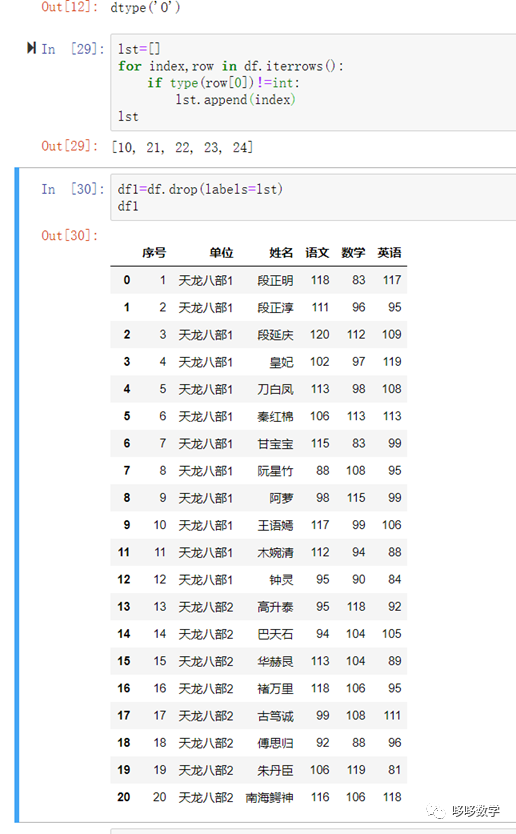
完成
===今天学习到此===

 转载是一种动力 分享是一种美德
转载是一种动力 分享是一种美德














 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









