






如何排查java应用中CPU使用率高或内存占用高的问题?这类问题的排查步骤基本通用的。现在通过一个具体的例子来说明。
问题描述
最近有个线上项目每天0点过后CPU使用率会上升至200%到300%。
排查过程
本节内容是对排查过程的复盘,过程记录会比较详细。如果想知道具体的命令操作,可以直接看总结部分内容。
1)当CPU再次暴涨的时候,首先我们可以通过top -c查看CPU使用率高的进程的PID。

2)然后使用top -p PID -H查看CPU使用率高的线程信息。如果CPU使用率高的线程是比较固定的,那么我们记下对应线程的PID。 执行top -p 14639 -H得出下图结果:

记下4个线程的PID: 14643、14644、14641、14642
3)接下来通过jstack PID > xxx.log输出java应用当前堆栈信息到文件。
4)第2步中,我们记下了CPU使用率高的线程PID,现在将4个线程的PID转成16进制: 3933、3934、3931、3932。接着在jstack输出的堆栈文件里,搜索nid等于3933、3934、3931、3932的线程信息。如下图:

从图中可以看出,对应的是GC线程。GC消耗大,那就有可能是由于内存不足,频繁执行Full GC导致的。
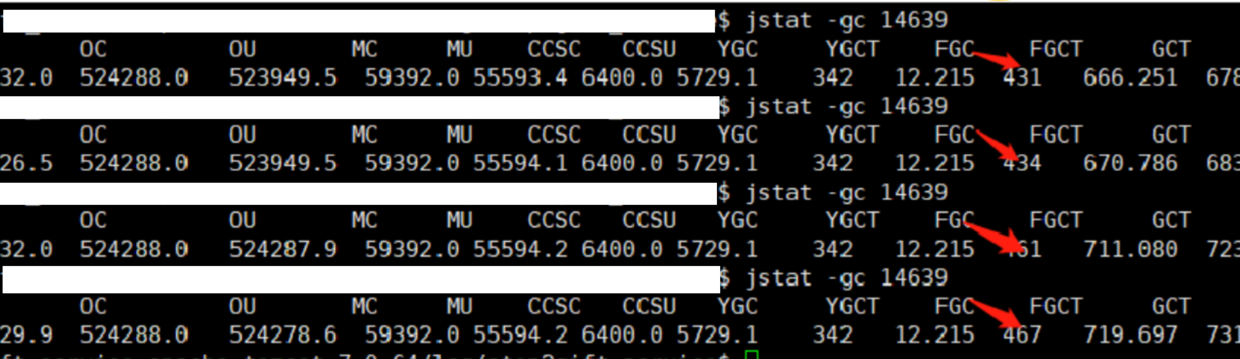
再使用jstat -gc PID查看jvm的GC情况,连续执行4次jstat -gc 14639命令,发现FGC的数值变化比较快。这就说明Full GC确实执行很频繁。如下图:
5)从第1步的截图中,可以看到CPU高的时候整个项目的内存占用1.3G左右。既然是内存问题,那么就需要使用jmap -histo:live PID > xxx.log分析下jvm内存存活对象的统计情况。如下图:
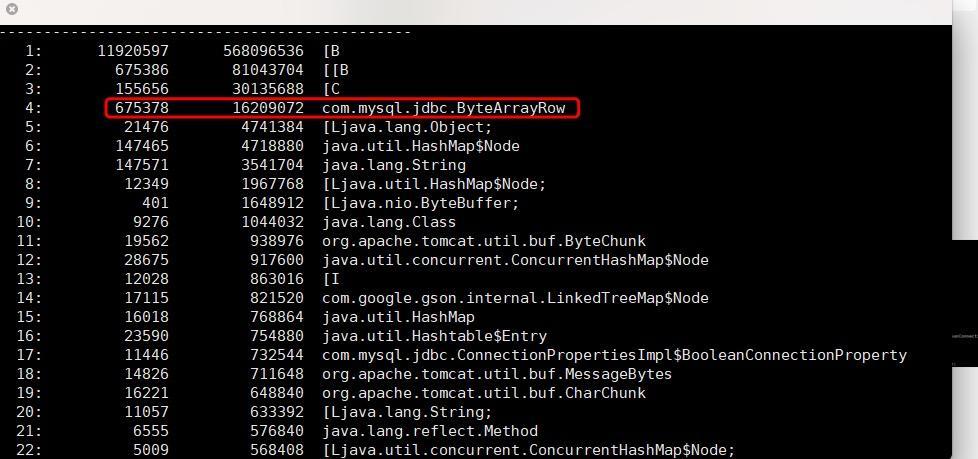
从图中可以看出,byte对象([B)内存占用特别高,而且出现了一个具体的类:ByteArrayRow。这是一个jdbc做查询时候封装数据用的一个类,这个类里包含有byte数组。通过这个统计结果初步怀疑是做数据库查询时候,查询了太多内容到了内存,导致了内存不足。由于统计中没有出现具体的业务类,所以就以为只是请求量比较大,导致的内存消耗过大。当时暂时将jvm的堆内存增大到2G。
6)应用jvm堆内存调大之后,到了0点还是出现了CPU高涨的问题。

内存占用了2G多,按照目前项目的请求量来说,2G内存不可能被占满了,所以说明并不是请求量大导致的结果,而是由于某块代码查询数据量过大导致的问题。
7)再次运行jmap -histo:live PID > xxx.log将内存对象统计情况输出到文件。结果如下图:
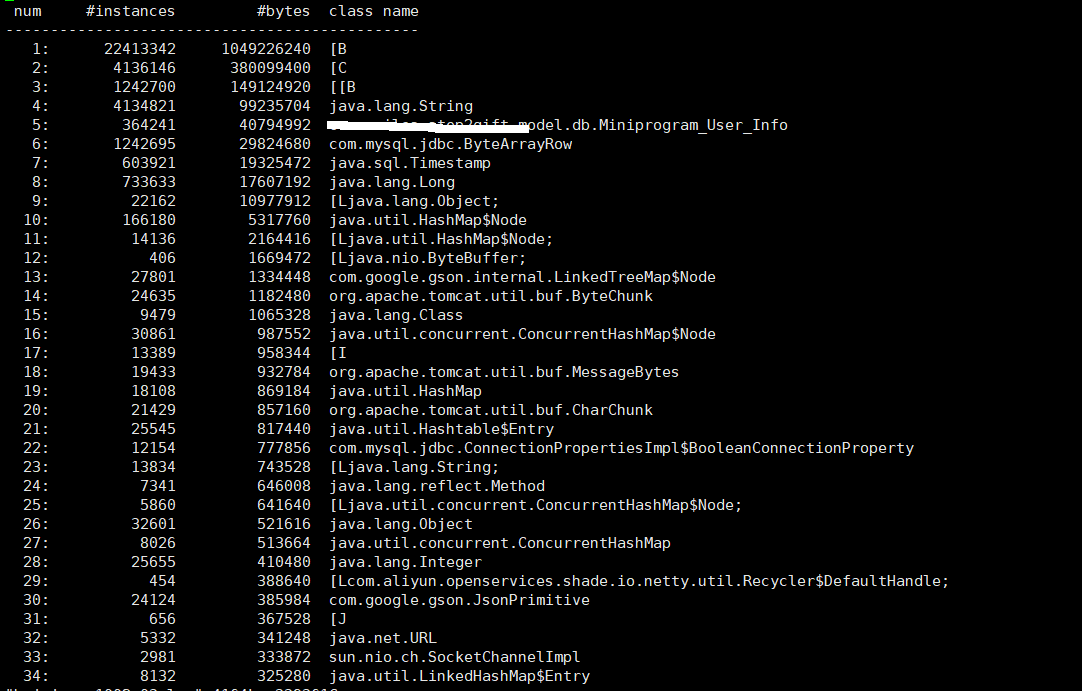
这次的输出结果出现了业务类MiniProgram_User_Info,那就可以针对这个业务类去排查异常代码的位置了。不过,除非比较清楚这个类具体使用的地方,否则即使出现了具体的类名还是比较难定位异常代码的位置。
这时候,我们可以使用jmap -dump:live,format=b,file=xxx.hprof PID命令来输出内存对象的明细,来定位具体方法位置。这个命令是将内存里的所有信息都输出出来,输出的文件大小和内存大小基本一致。而且这个命令会导致应用暂时挂起,所以谨慎使用。
8)这次将内存明细输出之后,dump文件大小为2G。用jdk自带的jhat命令可以分析。之前分析其他dump文件用jhat还是比较方便的。不过,分析这次的dump文件,给了10G运行内存给jhat命令才勉强打开了文件:jhat -J-mx10G -port 7170。而且内存对象比较多,查找问题不方便。最后找到了一款神器: jprofiler。用jprofier分析dump文件需要的运行内存比较少,而且问题定位很方便。很快就定位出了内存中的大对象,占用了1G多内存的对象:

大对象对应的线程堆栈:
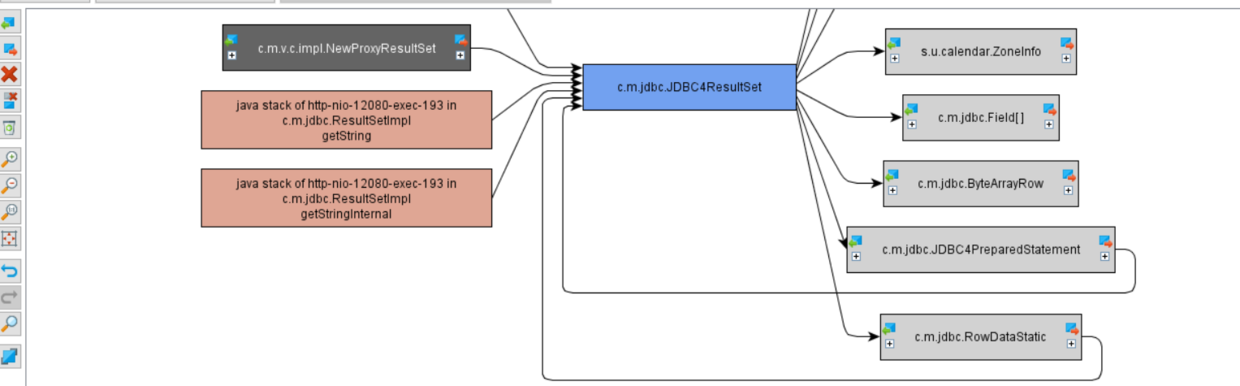
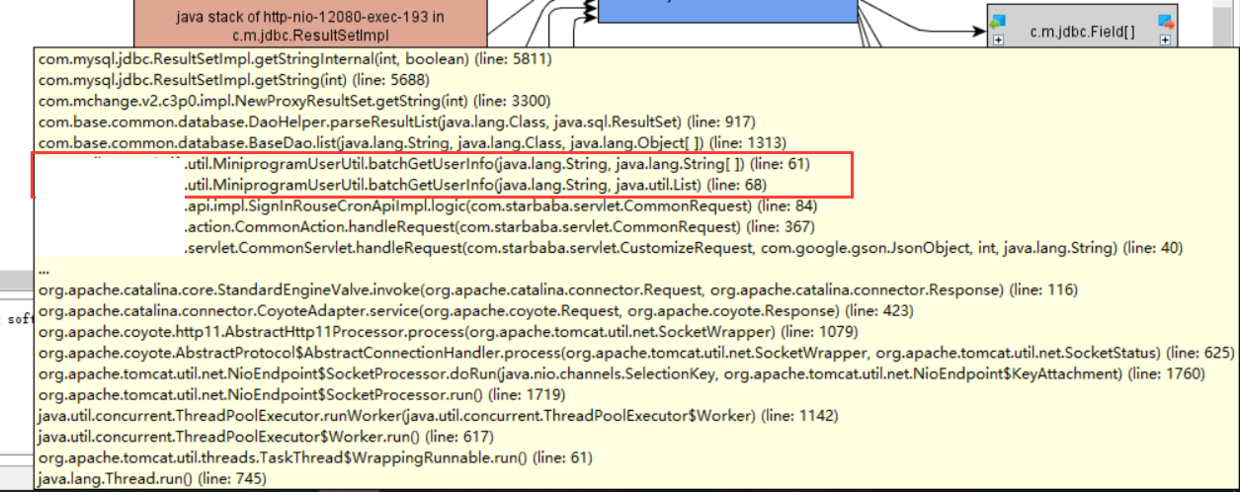
如上图,至此问题已经定位完成了。最后排查代码,最终发现凌晨时候,会将数据库里100多万条数据查询出来。内存不足导致频繁GC,结果就是CPU使用率暴涨。
总结
一、在排查问题的过程中针对CPU的问题,使用以下命令组合来排查问题
1、查看问题进程,得到进程PID:
top -c
2、查看进程里的线程明细,并手动记下CPU异常的线程PID:
top -p PID -H
3、使用jdk提供jstack命令打印出项目堆栈:
jstack pid > xxx.log
线程PID转成16进制,与堆栈中的nid对应,定位问题代码位置。
二、针对内存问题,使用以下命令组合来排查问题:
1、查看内存中的存活对象统计,找出业务相关的类名:
jmap -histo:live PID > xxx.log
2、通过简单的统计还是没法定位问题的话,就输出内存明细来分析。这个命令会将内存里的所有信息都输出,输出的文件大小和内存大小基本一致。而且会导致应用暂时挂起,所以谨慎使用。
jmap -dump:live,format=b,file=xxx.hprof PID
3、 最后对dump出来的文件进行分析。文件大小不是很大的话,使用jdk自带的jhat命令即可:
jhat -J-mx2G -port 7170
4、dump文件太大的话,可以使用jprofiler工具来分析。jprofiler工具的使用,这里不做详细介绍,有兴趣可以搜索一下。
三、需要分析GC情况,可以使用以下命令:
jstat -gc PID
这里简单介绍一下java8里面这个命令得出的列表各个列的含义:
S0C:第一个幸存区的大小
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
一般会比较关注YGC和FGC的次数。
内容补充
1、jstack输出的堆栈文件可以上传到下面这个网站,这个网站可以对堆栈内容进行统计汇总,方便我们做分析:http://fastthread.io/index.jsp
2、排查过程小节中的第5步,jmap命令执行完后没有输出业务类,而第7步在却有。这个是因为第5步操作的时候只有1G多的内存,代码还没执行到业务对象的封装,内存就不够了,后续的代码无法被执行到。第7步操作的时候内存调整到2G,所以有部分业务对象已经被创建了。














 5043
5043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









