







简介:NOIP旨在培养青少年计算思维、逻辑和问题解决能力,涵盖了算法设计、编程实践、数据结构、编程语言、字符串处理、数学知识和逻辑思维。本题库包含复赛阶段的十套模拟题,供参赛者自测和提升。理解题目、分析数据规模和边界、选择合适算法和数据结构、编写代码、控制时间及空间复杂度,都是解题的关键。 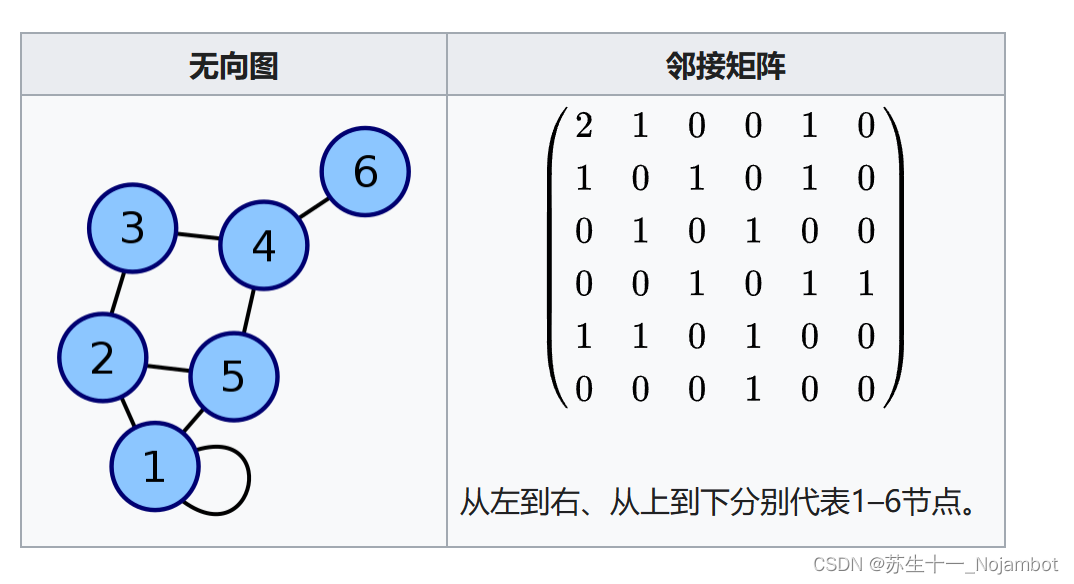
1. 信息学竞赛算法设计与编程实践
信息学竞赛是智力和技术的较量,它要求参赛者在有限的时间内,利用计算机编程解决给定的算法问题。在这一章节中,我们将探究算法设计的核心原则和编程实践的关键要素。
1.1 算法设计的理念与方法
算法是解决问题的明确指令集合,设计算法时要考虑到问题的规模、复杂度和执行效率。在信息学竞赛中,常见的算法设计方法包括分治法、动态规划、贪心算法等。每个方法都有其适用场景,理解这些算法的本质和适用性是解决问题的基础。
1.2 编程实践的要点
编码不仅仅是将算法转换成程序代码,还要注意代码的可读性、可维护性和效率。在竞赛中,快速实现一个高效且错误率低的程序是非常重要的。练习中,应不断优化代码,直到找到最优解。
#include <iostream>
#include <algorithm>
using namespace std;
// 示例:简单的排序算法实现
void selectionSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
int min_idx = i;
for (int j = i + 1; j < n; j++)
if (arr[j] < arr[min_idx])
min_idx = j;
swap(arr[min_idx], arr[i]);
}
}
int main() {
int arr[] = {64, 25, 12, 22, 11};
int n = sizeof(arr) / sizeof(arr[0]);
selectionSort(arr, n);
for (int i = 0; i < n; i++)
cout << arr[i] << " ";
cout << endl;
return 0;
}
通过实践,我们可以将理论与实际结合,提升解决实际问题的能力。在后续的章节中,我们将深入探讨数据结构、编程语言、数学知识以及高级编程技巧在信息学竞赛中的应用。
2. 数据结构应用精讲
2.1 常用数据结构概览
2.1.1 数组与链表的基本操作和应用场景
数组与链表是数据结构中最基础的两种线性结构,它们在程序设计中有着广泛的应用。
数组
数组是一种线性表结构,它将元素在内存中连续存储。数组的每个元素通过索引访问,其优点在于可以快速地通过下标访问任何位置的元素。然而,数组的大小在初始化时就固定,不支持动态扩展。
应用场景
- 当需要频繁通过下标访问元素时,数组是非常高效的选择。
- 数组可以很好地用于实现其他数据结构,如栈、队列。
链表
链表同样是一种线性结构,由一系列节点组成。每个节点包含数据和指向下一个节点的指针。链表可以动态地在运行时增加或删除节点,不受固定大小的限制。
应用场景
- 当不确定数据量大小时,链表提供了灵活的动态扩展能力。
- 链表在实现复杂数据结构如循环队列、双向链表等非常有用。
2.1.2 栈与队列的性质及其在问题中的运用
栈(Stack)
栈是一种后进先出(LIFO)的数据结构,允许在两端进行操作:一端添加元素(入栈),另一端移除元素(出栈)。
应用场景
- 栈适用于实现括号匹配、表达式求值、深度优先搜索(DFS)等。
- 在处理嵌套结构和回溯问题时,栈能够提供优雅的解决方案。
队列(Queue)
队列是一种先进先出(FIFO)的数据结构,支持在两端操作:一端添加元素(入队),另一端移除元素(出队)。
应用场景
- 队列用于实现广度优先搜索(BFS)、任务调度、缓冲管理等。
- 在需要排队或处理按顺序到达的数据时,队列是一种自然的选择。
接下来,我们将探讨高级数据结构哈希表、树形数据结构和图的遍历算法及其优化策略。
3. 编程语言基础与实战
3.1 C++编程语言深入解析
3.1.1 C++基础语法回顾与项目实战
C++作为编程语言中的翘楚,它集成了面向对象、泛型编程以及过程式编程的特性,为开发者提供了高效灵活的编程工具。在信息学竞赛中,C++的性能优势尤为明显,其执行速度以及资源控制能力使得它成为解决复杂问题的首选语言。
在基础语法回顾环节,我们有必要从变量声明、基本数据类型开始,然后深入到数组、指针、引用的使用,最后覆盖函数定义、类和对象的创建等关键概念。掌握这些基础知识是深入学习C++的前提。
在项目实战部分,我们将通过一个简单的例子,展示如何将C++的基本语法应用到实际问题解决中。例如,我们构建一个学生信息管理系统,其中包括学生信息的录入、查询、修改和删除功能。项目实战是检验学习成果的最好方式,通过实际的编码过程,可以加深对C++语法的理解和应用。
接下来是一个代码块示例,它展示了如何在C++中实现一个简单的学生类(Student)和相应的功能函数。
#include <iostream>
#include <vector>
#include <string>
class Student {
private:
std::string name;
int age;
std::string id;
public:
Student(std::string n, int a, std::string i) : name(n), age(a), id(i) {}
void display() {
std::cout << "Name: " << name << ", Age: " << age << ", ID: " << id << std::endl;
}
// 这里可以添加更多的成员函数,比如修改学生信息等。
};
int main() {
std::vector<Student> students;
// 创建学生对象并添加到学生列表
students.emplace_back("John Doe", 20, "S123");
students.emplace_back("Jane Doe", 19, "S456");
// 遍历并显示学生信息
for (auto& student : students) {
student.display();
}
return 0;
}
代码逻辑分析 :
- 第2行引入了
iostream、vector、string三个标准库,它们分别用于输入输出、动态数组和字符串操作。 - 第6-13行定义了一个
Student类,包含私有成员变量和一个构造函数以及一个公开的成员函数display()用于显示学生信息。 - 第22-29行
main函数中,我们创建了一个Student对象的vector动态数组,通过emplace_back方法添加了两个学生对象。 - 第31-37行使用范围for循环遍历学生列表,并调用每个学生的
display()函数显示信息。
参数说明 :
-
std::vector<Student>定义了一个Student类型的动态数组。 -
std::string n, int a, std::string i:构造函数接受三个参数,分别是学生的名字、年龄和学号。 -
display函数是一个简单的成员函数,它使用std::cout输出学生的信息。
项目实战部分是一个迭代的过程,编码过程中可能会遇到各种问题,如数据类型不匹配、内存管理错误等。而通过不断调试和优化代码,可以提高编程能力并加深对C++语言的理解。
3.1.2 C++标准模板库(STL)的高级使用技巧
C++标准模板库(STL)是一个强大的工具,它包含了一系列常用的容器、迭代器、算法和函数对象。STL的设计初衷是为了提供一个通用的、高效的、可重用的代码库,通过模板实现泛型编程。在信息学竞赛中,熟练使用STL可以大幅提高开发效率。
. . . 容器类的深入理解
STL提供了多种容器类,例如 vector 、 list 、 map 、 set 等,每种容器都有其特定的用途和性能特点。例如:
-
vector是一个动态数组,它在内存中连续存储数据,对于随机访问非常高效,但插入和删除操作较慢。 -
list是一个双向链表,它在任何位置插入和删除操作都很高效,但是随机访问较慢。 -
map是一个关联数组,允许我们存储键值对,可以根据键快速检索值。
. . . 迭代器的高级使用
迭代器是STL中用于访问容器元素的工具。正确使用迭代器不仅可以提高代码的灵活性,还可以避免许多常见的错误。迭代器有正向迭代器、反向迭代器、常量迭代器、双向迭代器和随机访问迭代器等类型,每种迭代器都有其特定的用途。
例如,使用反向迭代器遍历一个 vector 容器:
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
// 使用反向迭代器遍历
for (auto rit = vec.rbegin(); rit != vec.rend(); ++rit) {
std::cout << *rit << ' ';
}
std::cout << std::endl;
return 0;
}
代码逻辑分析 :
- 第5-6行创建了一个
vector<int>并初始化。 - 第9-12行使用
rbegin()和rend()方法获得反向迭代器,并进行遍历打印。rbegin()返回指向容器最后一个元素的反向迭代器,rend()返回指向容器第一个元素之前的反向迭代器。 - 在
for循环中,++rit表示反向迭代器向前移动。
参数说明 :
-
rbegin():返回指向容器最后一个元素的反向迭代器。 -
rend():返回指向容器第一个元素之前的反向迭代器。
. . . STL算法的实践与优化
STL提供了大量的预定义算法,这些算法可以完成各种常见的任务,如排序、搜索、修改等。掌握这些算法并学会其优化技巧对提高编程效率至关重要。
例如,使用 sort 算法对 vector 进行排序:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {5, 3, 8, 1, 2};
// 使用sort算法对vector进行排序
std::sort(vec.begin(), vec.end());
// 输出排序后的vector
for (auto elem : vec) {
std::cout << elem << ' ';
}
std::cout << std::endl;
return 0;
}
代码逻辑分析 :
- 第5-6行创建了一个
vector<int>并初始化。 - 第9-11行调用
std::sort函数对vec进行排序,其中vec.begin()和vec.end()分别表示vector的起始和结束迭代器。 - 第14-18行使用范围for循环输出排序后的
vector。
参数说明 :
-
std::sort:是一个排序函数,需要至少两个迭代器参数,表示要排序的范围。默认是升序排序,也可以指定比较函数来改变排序行为。
在实际应用中,还可以通过自定义比较函数或者指定比较策略来优化算法的性能。了解和熟练掌握STL的高级使用技巧,对于提升编程能力,尤其是在信息学竞赛中,是非常有价值的。
3.2 Python编程语言实战演练
3.2.1 Python语法特点与编程风格
Python是一种高级编程语言,以其简洁的语法和强大的功能库闻名。它广泛应用于网络应用、数据分析、人工智能以及科学计算等领域。Python的语法简洁明了,可读性强,特别适合初学者学习。在信息学竞赛中,Python经常被用于解决算法问题,尤其是当需要快速实现原型和算法验证时。
Python语法中,一些显著特点包括动态类型、缩进语法和丰富的内置函数。动态类型意味着在编写Python代码时,不需要声明变量的数据类型,解释器会在运行时自动推断。缩进语法让代码块的界限更加清晰,这同样有助于提高代码的可读性。
Python的编程风格鼓励使用简单直观的方法来解决问题,强调代码的简洁性。PEP 8是Python社区推荐的代码风格指南,它规定了变量命名、空格使用、注释和文档等编程习惯。
一个简单的Python程序示例如下:
def calculate_sum(numbers):
return sum(numbers)
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5]
result = calculate_sum(numbers)
print(f"The sum is {result}")
代码逻辑分析 :
- 第1行定义了一个名为
calculate_sum的函数,它接受一个参数numbers。 - 第2行使用内置函数
sum()计算numbers的和并返回结果。 - 第4-7行是程序的入口点。
__name__ == "__main__"确保以下代码块只在直接运行脚本时执行。 - 第5-6行定义了
numbers列表并调用calculate_sum函数计算其和,然后打印结果。
参数说明 :
-
def关键字用于定义函数。 -
return语句用于返回函数的结果。 -
sum()是Python的内置函数,用于计算序列的和。
编写Python代码时,应当遵循PEP 8代码风格指南,这不仅能够提升代码的质量,还有助于团队合作。比如,在命名变量时,推荐使用小写字母和下划线来增强变量的可读性,如 student_name 或 class_score 。
3.2.2 Python在信息学竞赛中的特殊应用
在信息学竞赛中,Python常被用于算法的快速实现和问题求解。Python的第三方库,如NumPy、SciPy用于科学计算,Matplotlib用于数据可视化,Pandas用于数据分析,这些工具在处理实际问题时提供了极大的便利。
. . . 使用NumPy进行高效计算
NumPy是一个强大的Python数值计算库,提供了多维数组对象以及一系列数学运算函数。其内部优化程度高,因此在处理大规模数据时,性能通常优于纯Python实现。
下面是一个使用NumPy数组来实现向量加法的例子:
import numpy as np
# 创建两个NumPy数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 使用NumPy进行向量加法
c = a + b
print("The result of vector addition is:", c)
代码逻辑分析 :
- 第3行导入NumPy库并赋予别名
np。 - 第5-6行创建两个三维数组
a和b。 - 第8行使用
+操作符对a和b进行元素级的加法运算,结果存储在数组c中。 - 第10行打印运算结果。
参数说明 :
-
np.array():创建一个NumPy数组。 -
+:在NumPy中,加号用于对两个数组进行元素级的加法。
. . . 利用Matplotlib进行数据可视化
Matplotlib是Python的一个绘图库,可以绘制各种静态、动态、交互式的图表。在信息学竞赛中,数据可视化可以直观地展示算法的性能,帮助我们更好地理解问题和验证解决方案。
一个简单的绘制散点图的例子如下:
import matplotlib.pyplot as plt
# 创建一些数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 使用Matplotlib绘制散点图
plt.scatter(x, y)
# 添加图表标题和坐标轴标签
plt.title("Scatter Plot Example")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
# 显示图表
plt.show()
代码逻辑分析 :
- 第3行导入Matplotlib库的pyplot模块,并赋予别名
plt。 - 第5-6行定义了x和y两个列表,用于绘图。
- 第8行使用
scatter()函数绘制散点图。 - 第10-13行设置图表的标题和坐标轴标签。
- 第15行调用
show()函数显示图表。
参数说明 :
-
plt.scatter():绘制散点图。 -
plt.title(),plt.xlabel(),plt.ylabel():设置图表的标题和坐标轴标签。
Python的动态特性和丰富的第三方库,使得它在竞赛编程中非常有用。掌握Python编程语言,特别是在数据处理和可视化方面的技巧,能够极大地提升解决复杂问题的能力。
4. 字符串处理与编程高级技巧
4.1 字符串处理技巧
4.1.1 字符串搜索算法与实现
字符串搜索是编程中常见的问题,经常出现在数据处理和文本分析的场景中。对于字符串搜索,基本的算法有朴素字符串匹配算法、KMP(Knuth-Morris-Pratt)算法、Boyer-Moore算法和Rabin-Karp算法等。每种算法有其特定的使用场景和优势。
朴素字符串匹配算法是最直观的字符串搜索方法,它对目标字符串进行逐个字符的比较,直到找到匹配或完全不匹配为止。尽管算法简单,但在最坏的情况下,其时间复杂度为O(n*m),其中n为目标字符串长度,m为模式字符串长度,效率较低。
KMP算法通过预处理模式字符串,构建一个部分匹配表(也称为失败函数),用于在不匹配时跳过尽可能多的字符,有效减少比较次数。KMP算法的时间复杂度为O(n+m)。
Boyer-Moore算法则反其道而行之,从目标字符串的末尾开始比较,并使用两个启发式规则——坏字符规则和好后缀规则,实现较大的位移。该算法在实际应用中效率较高,尤其是在模式较短时。
Rabin-Karp算法采用散列函数将模式字符串和目标字符串中的字符块映射到较小的数字,从而快速比较字符串。其在平均情况下效率较高,尤其适用于多模式匹配问题。
以下是KMP算法的实现代码,通过该代码,我们可以理解KMP算法的原理和步骤:
#include <iostream>
#include <vector>
#include <string>
void computeLPSArray(const std::string &pat, std::vector<int> &lps) {
int len = 0; // Length of the previous longest prefix suffix
lps[0] = 0; // lps[0] is always 0
int i = 1;
while (i < pat.length()) {
if (pat[i] == pat[len]) {
len++;
lps[i] = len;
i++;
} else {
if (len != 0) {
len = lps[len - 1];
// Note that we do not increment i here
} else {
lps[i] = 0;
i++;
}
}
}
}
void KMPSearch(const std::string &pat, const std::string &txt) {
int M = pat.length();
int N = txt.length();
std::vector<int> lps(M, 0);
computeLPSArray(pat, lps);
int i = 0; // index for txt[]
int j = 0; // index for pat[]
while (i < N) {
if (pat[j] == txt[i]) {
j++;
i++;
}
if (j == M) {
std::cout << "Found pattern at index " << i - j << std::endl;
j = lps[j - 1];
} else if (i < N && pat[j] != txt[i]) {
if (j != 0)
j = lps[j - 1];
else
i = i + 1;
}
}
}
int main() {
std::string txt = "ABABDABACDABABCABAB";
std::string pat = "ABABCABAB";
KMPSearch(pat, txt);
return 0;
}
在此代码中, computeLPSArray 函数用于计算给定模式字符串的部分匹配表,而 KMPSearch 函数实现了KMP算法的主要搜索逻辑。理解每一步的逻辑以及它们如何工作是掌握此算法的关键。
4.1.2 字符串操作的优化方法
字符串优化通常涉及到内存分配、数据结构选择和算法设计。在处理大量字符串时,使用高效的内存管理技术至关重要。例如,使用字符串池来减少字符串的内存占用,或者在支持的编程语言中利用不可变字符串特性来提高性能。
对于字符串连接操作,通常建议使用字符串构建器(如Java中的StringBuilder)或缓冲区(如C++中的ostringstream),这些工具能够有效减少在循环中进行字符串连接操作时产生的大量临时对象,从而优化性能。
同时,一些算法中的字符串操作可以利用特定语言的高级特性进行优化。例如,在Python中,可以使用正则表达式库来处理复杂的字符串匹配和提取问题,这通常比手动编写的代码更高效。
在C++中,可以利用标准模板库(STL)中的算法和数据结构,比如std::string_view来避免不必要的字符串拷贝,或者利用std::unordered_map来实现快速的字符串查找。
针对特定场景,还可以采取一些特别的优化措施。例如,当频繁地对字符串进行切片操作时,可以考虑使用std::rope,它是C++中为处理大型字符串而设计的一种数据结构。
下面是一个C++的例子,展示了如何使用 std::string_view 和 std::unordered_map 来进行高效的字符串操作:
#include <iostream>
#include <string>
#include <string_view>
#include <unordered_map>
int main() {
std::string largeText = "The quick brown fox jumps over the lazy dog.";
std::unordered_map<std::string_view, int> wordCount;
// Use std::string_view for avoiding copying strings
std::string_view text(largeText);
size_t pos = 0;
while (pos < text.size()) {
size_t next = text.find(' ', pos);
std::string_view word = text.substr(pos, next - pos);
++wordCount[word];
pos = (next == std::string::npos) ? next : next + 1;
}
// Output the word count
for (const auto &pair : wordCount) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
在上述代码中,我们使用了 std::string_view 来避免创建不必要的字符串拷贝,这对于处理大型文本尤其有用。同时,我们使用 std::unordered_map 来快速统计每个单词的出现次数。
4.2 编程高级技巧应用
4.2.1 递归与迭代的抉择与运用
在编程中,递归和迭代都是基本的编程技术。它们各有优劣,选择哪种方式通常取决于问题的性质和性能要求。递归方法简洁明了,容易理解,但可能会导致较大的内存消耗,特别是在深度很大的递归调用中。迭代方法通常消耗更少的内存,但可能会使代码的逻辑更加复杂。
递归的典型例子是树和图的遍历、分治算法等。递归的实现需要一个明确的递归终止条件和递归体。而迭代通常使用循环结构来实现,通过在循环中维护一个状态来控制执行流程。
在某些情况下,递归可以转换为迭代,反之亦然。在选择实现方式时,重要的是权衡两者在代码可读性和性能之间的利弊。
以下是使用递归和迭代实现的斐波那契数列的例子,可以帮助理解两者之间的差异:
# Recursive implementation of Fibonacci sequence
def fibonacci_recursive(n):
if n <= 1:
return n
else:
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
# Iterative implementation of Fibonacci sequence
def fibonacci_iterative(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
在Python中,递归的实现简单明了,但当n较大时,可能导致栈溢出。而迭代的实现避免了这一问题,并且更加高效。对于这个问题,还可以使用记忆化递归(也称为备忘录方法)来优化递归的性能。
4.2.2 动态规划在复杂问题中的实践
动态规划是解决优化问题的一种有效方法,特别适用于具有重叠子问题和最优子结构特性的问题。动态规划的目的是通过将问题分解为更小的子问题,记录子问题的解,并在此基础上构建最终问题的解。
动态规划的关键在于建立状态转移方程,它表达了问题的最优解与其子问题解之间的关系。然后使用数组或哈希表来存储子问题的解(称为备忘录),从而避免重复计算。
动态规划的经典问题包括背包问题、编辑距离、最长公共子序列(LCS)、最短路径问题等。理解和实现动态规划需要一定的技巧,但一旦掌握,它将能帮助解决许多复杂问题。
以下是一个动态规划解决最长公共子序列问题的Python示例:
def longest_common_subsequence(X, Y):
m = len(X)
n = len(Y)
L = [[0] * (n + 1) for i in range(m + 1)]
# Build L[m+1][n+1] in bottom-up fashion
for i in range(m + 1):
for j in range(n + 1):
if i == 0 or j == 0:
L[i][j] = 0
elif X[i - 1] == Y[j - 1]:
L[i][j] = L[i - 1][j - 1] + 1
else:
L[i][j] = max(L[i - 1][j], L[i][j - 1])
# Following code is used to print LCS
index = L[m][n]
lcs = [""] * (index + 1)
lcs[index] = ""
# Start from the right-most-bottom-most corner and
# one by one store characters in lcs[]
i = m
j = n
while i > 0 and j > 0:
# If current character in X[] and Y are same, then
# current character is part of LCS
if X[i-1] == Y[j-1]:
lcs[index-1] = X[i-1]
i -= 1
j -= 1
index -= 1
# If not same, then find the larger of two and
# go in the direction of larger value
elif L[i-1][j] > L[i][j-1]:
i -= 1
else:
j -= 1
return "".join(lcs[:-1]) # Remove the last empty space
# Example usage
X = "AGGTAB"
Y = "GXTXAYB"
print("LCS of " + X + " and " + Y + " is " + longest_common_subsequence(X, Y))
在这个例子中,我们使用动态规划算法来计算两个字符串的最长公共子序列。我们首先创建了一个二维数组 L 来存储最长子序列的长度。然后通过填充这个数组来构建解决方案。最终,我们利用这个数组来构建并返回最长公共子序列。
动态规划的实践需要对问题的结构有深刻的理解,找到合适的状态定义和状态转移方程是解决问题的关键。而理解和运用动态规划则需要大量的练习和对算法的深刻把握。
5. 数学知识在编程中的应用
数学是编程和算法设计中不可或缺的基础。在这一章中,我们将探讨数学知识在编程中的实际应用,特别是离散数学与组合数学、数论以及概率论的核心概念。
5.1 离散数学与组合数学基础
在信息学竞赛和实际编程工作中,离散数学和组合数学的概念经常被用到。它们不仅是很多算法的基石,而且在解决实际问题时提供了强有力的工具。
5.1.1 图论在算法设计中的应用
图论是离散数学中的一个重要分支,它研究的是图的性质和图之间的关系。在算法设计中,图论的概念和算法被广泛应用于网络、社交网络分析、操作系统任务调度、图形学等众多领域。
图的基本概念
图由顶点(或节点)和连接这些顶点的边组成。在编程实现中,可以用邻接矩阵或邻接表来表示图。
// 邻接矩阵表示图的简单实现
const int MAXN = 100; // 假设图中最多有100个节点
int graph[MAXN][MAXN] = {0}; // 初始化图的邻接矩阵
// 添加边
void addEdge(int u, int v) {
graph[u][v] = 1;
graph[v][u] = 1; // 如果是无向图,需要添加这行
}
在上述代码中,我们用二维数组 graph 来存储图的邻接矩阵,当 graph[u][v] 的值为1时,表示节点 u 和节点 v 之间存在边。
图的遍历算法
图的深度优先搜索(DFS)和广度优先搜索(BFS)是最基本的遍历图的算法,它们可以用于解决很多图相关的问题。
# 使用DFS遍历图
def dfs(graph, node, visited):
if visited[node]:
return
visited[node] = True
# 处理节点node
# ...
for neighbor in range(len(graph[node])):
if graph[node][neighbor] and not visited[neighbor]:
dfs(graph, neighbor, visited)
# 使用BFS遍历图
from collections import deque
def bfs(graph, start):
visited = [False] * len(graph)
queue = deque([start])
while queue:
node = queue.popleft()
if not visited[node]:
visited[node] = True
# 处理节点node
# ...
for neighbor in range(len(graph[node])):
if graph[node][neighbor]:
queue.append(neighbor)
图的遍历算法在实际编程中十分常见,特别是在处理图形化界面、网络爬虫路径探索等场景时。
5.1.2 组合数学原理与问题解法
组合数学涉及的是计数问题,它在算法设计和分析中有着广泛的应用。组合数学中的一个核心概念是排列组合,它为问题的建模提供了强有力的数学工具。
排列组合的应用
在编程比赛中,经常需要计算某种对象组合的方式数。比如,计算从10个不同的元素中取出3个元素的组合数,可以使用组合数学中的公式。
# 计算组合数C(n, k)
def combination(n, k):
# 使用二项式定理的公式计算组合数C(n, k)
return math.factorial(n) // (math.factorial(k) * math.factorial(n - k))
print(combination(10, 3)) # 输出结果为120
组合数在算法中用于计算路径选择、状态转换的可能性等,能够帮助我们优化搜索空间,提高算法效率。
5.2 数论与概率论核心概念
数论和概率论是数学的两个重要分支,它们在编程中的应用可以显著提高算法的效率和性能。
5.2.1 数论中的同余理论与快速幂运算
同余理论是数论中研究整数在除以某个正整数后余数的性质的一个理论。它在密码学、散列函数设计等领域有着广泛的应用。
快速幂运算
快速幂运算是同余理论中的一个重要应用,它可以在对数时间内完成幂运算,比普通的线性时间幂运算要高效得多。
# 快速幂算法
def fast_pow(base, exponent, modulus):
result = 1
while exponent > 0:
if exponent % 2 == 1:
result = (result * base) % modulus
exponent = exponent >> 1
base = (base * base) % modulus
return result
print(fast_pow(2, 1000, 1009)) # 计算2^1000 mod 1009的结果
快速幂算法在大数幂运算中极为有用,它不仅减少了计算量,还大大提升了计算速度。
5.2.2 概率论在算法中处理随机性的技巧
概率论在算法设计中占有重要地位,特别是在处理不确定性和随机性问题时。它能够帮助我们设计出更加稳健和高效的算法。
概率算法
概率算法是一种使用随机选择的算法,它们可以在多项式时间内解决某些确定性算法难以解决的问题,比如在大数据集中寻找中位数、哈希冲突处理等。
# 随机化选择算法示例:快速选择中位数
def quick_select(arr, low, high, k):
if low < high:
pivot_index = partition(arr, low, high)
if pivot_index == k:
return arr[pivot_index]
elif pivot_index < k:
return quick_select(arr, pivot_index + 1, high, k)
else:
return quick_select(arr, low, pivot_index - 1, k)
else:
return arr[low]
# 快速选择算法基于快速排序的选择过程
def partition(arr, low, high):
pivot = arr[high]
i = low
for j in range(low, high):
if arr[j] <= pivot:
arr[i], arr[j] = arr[j], arr[i]
i += 1
arr[i], arr[high] = arr[high], arr[i]
return i
在上述代码中, quick_select 函数使用快速排序中的分区过程来选取中位数,其时间复杂度期望为O(n)。在处理大数据集时,相比O(nlogn)的排序算法,概率算法可以显著提高效率。
在本章中,我们介绍了离散数学与组合数学、数论和概率论在编程中的核心应用。通过这些数学知识,我们不仅能够解决一些复杂的编程问题,还能优化算法设计,提高程序的效率和性能。下一章将继续探讨逻辑思维、问题解决与编码优化方面的内容。
6. 逻辑思维、问题解决与编码优化
6.1 逻辑思维与问题分析
6.1.1 逻辑推理在解题中的应用
逻辑推理是信息学竞赛中不可或缺的技能,它帮助我们从已知事实出发,按照逻辑规则推导出未知结论。在解题时,构建一个清晰的逻辑链是至关重要的。例如,在解决数学证明题时,我们通常会从已知条件出发,逐步推理出需要证明的结论。
案例分析:
假设有一个逻辑问题,我们需要确定三种陈述中哪一个是假的。
- 所有程序员都喜欢用C++编程。
- 没有程序员喜欢用C++编程。
- 有些程序员喜欢用Python编程。
通过逻辑分析,我们可以看出陈述2与陈述1相矛盾,因此至少有一个是错误的。结合陈述3,我们可以推断出陈述1是错误的,因为如果有程序员喜欢Python,那么他们不可能同时喜欢C++。
6.1.2 复杂问题的拆解与逐步求解
复杂问题往往由多个子问题组成,通过逐一解决这些子问题,最终解决整个问题。这个过程需要我们具备问题拆解的能力和逐步求解的策略。
拆解技巧:
- 明确主问题和子问题。
- 确定子问题之间的依赖关系。
- 优先解决简单或依赖较少的子问题。
- 逐步解决问题并进行整合。
例如,在解决图论问题时,我们可能会将问题分解为图的遍历、子图的构建、路径搜索等子问题,然后通过编程逐步实现这些子问题的解决方案。
6.2 编码技巧与程序效率提升
6.2.1 代码编写的基本原则和风格指南
编写高质量代码不仅关乎可读性,也关乎性能。良好的编码习惯能够使得代码更易于维护和扩展。
编码原则:
- 简洁性 :代码应尽可能简洁,避免不必要的复杂性。
- 可读性 :命名清晰,代码结构良好,易于理解。
- 一致性 :遵循一致的编码风格和格式。
- 模块化 :将程序分解为可重用的模块。
风格指南:
- 命名规范 :合理使用有意义的变量和函数名。
- 注释 :添加必要的注释以解释复杂的逻辑和算法。
- 代码布局 :合理使用空格、缩进和换行来提高代码的可读性。
6.2.2 代码优化的方法论与案例分析
优化代码意味着改进算法或数据结构以提高程序性能。以下是一些常见的代码优化策略:
- 算法优化 :选择效率更高的算法来减少时间复杂度。
- 空间优化 :使用更节省空间的数据结构。
- 循环优化 :减少循环次数,避免不必要的计算。
- 递归优化 :使用尾递归或迭代来避免栈溢出和重复计算。
案例分析:
考虑一个计算斐波那契数列的程序,原始的递归实现效率低下,因为重复计算了很多子问题。
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
通过使用动态规划,我们可以将中间结果存储起来,避免重复计算,显著提高效率。
def fibonacci(n):
memo = [0] * (n+1)
memo[1] = 1
for i in range(2, n+1):
memo[i] = memo[i-1] + memo[i-2]
return memo[n]
6.3 题目分析与实战调试
6.3.1 题目理解的技巧与要点
理解题目是解题的第一步。良好的题目分析应该包括以下几个方面:
- 理解题目的字面意思 :仔细阅读题目描述,确保不遗漏任何信息。
- 分析题目的要求 :明确输入和输出的要求。
- 识别关键信息 :注意题目中的限制条件和关键参数。
- 归纳问题类型 :确定问题属于哪一类算法或数据结构问题。
6.3.2 数据规模分析与算法选择
数据规模决定了算法的选择。例如:
- 小规模数据:可以使用暴力法或简单算法。
- 大规模数据:可能需要使用高级数据结构或优化过的算法。
算法选择的原则:
- 时间复杂度 :选择时间复杂度较低的算法。
- 空间复杂度 :考虑空间资源的限制。
- 稳定性和可靠性 :选择经过测试验证的算法。
6.3.3 调试过程中的常见问题与解决策略
调试是解决程序中的错误和问题的过程。常见的调试策略包括:
- 逐步执行 :使用调试工具逐步执行代码,观察变量的变化。
- 打印输出 :在关键位置打印变量值,以便于理解程序执行流程。
- 断点设置 :设置断点,在特定代码行暂停执行,检查程序状态。
- 测试用例 :编写多个测试用例来覆盖不同的执行路径。
解决策略:
- 定位问题 :通过错误信息或程序异常来确定问题所在。
- 分析原因 :分析为什么会出现这样的问题。
- 实施修复 :修改代码以解决问题。
- 回归测试 :确保修复没有引入新的问题。
以上内容涵盖了逻辑思维、编码技巧和问题解决的关键方面,并提供了一系列实用的方法和技巧。在实际编码和解决问题时,应用这些方法将会帮助你更加高效和准确地完成任务。
简介:NOIP旨在培养青少年计算思维、逻辑和问题解决能力,涵盖了算法设计、编程实践、数据结构、编程语言、字符串处理、数学知识和逻辑思维。本题库包含复赛阶段的十套模拟题,供参赛者自测和提升。理解题目、分析数据规模和边界、选择合适算法和数据结构、编写代码、控制时间及空间复杂度,都是解题的关键。

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









