






我爬取的是58同城北京租房的索引页。
url:https://bj.58.com/chuzu/?PGTID=0d100000-0000-1e00-4039-99b26a4fedeb&ClickID=2
审查元素可知网站进行了字体加密,直接复制网页中的数字得到的也是乱码,因此我们需要找到一个映射关系,加密字符映射到我们想要的数字。
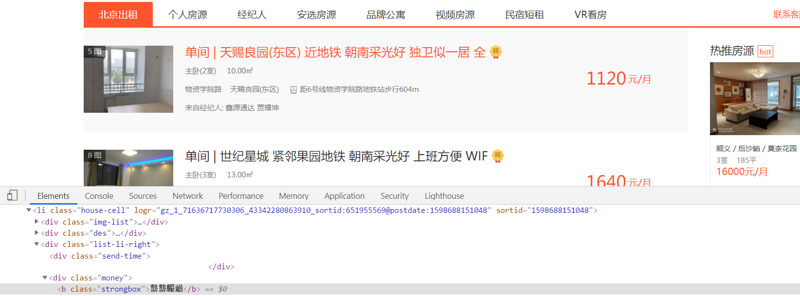
打开network中的doc,我们发现这里面的数字是这样一堆十六进制码,并且每次刷新网页这些十六进制码所对应的数字都是变化的,而且我们发现每个这种标签他的类标签都是strongbox。

然后我们在network中查看font下的数据包,把这个包下载下来,并用fontCreator打开,我们会发现这个就是我们所需要的字体文件
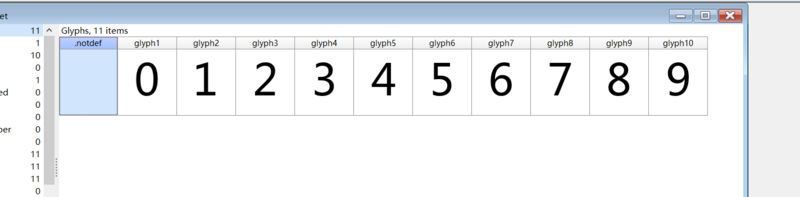
在python下用fonttools进行解析为xml文件,我们会发现两个映射关系
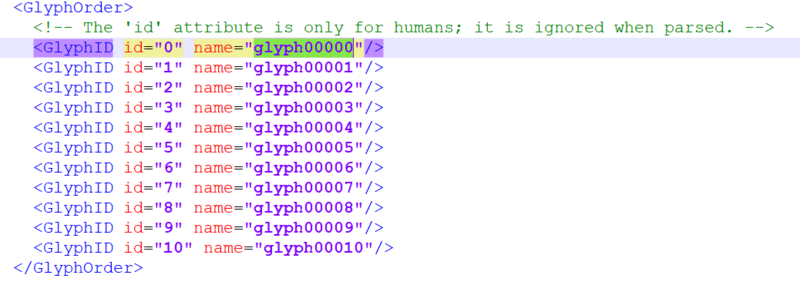
1.glyph00001->1 glyph00002->2以此类推
2.cmap中的map有code与glyph有映射。
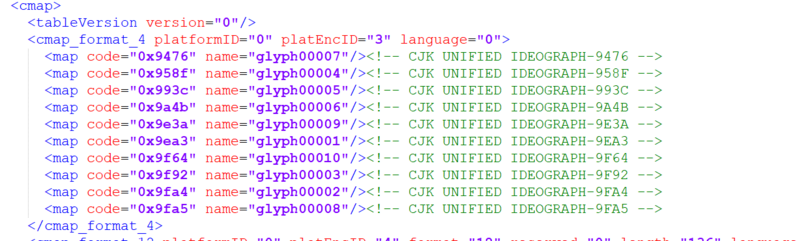
看到这里我们就有思路了,我们只需要通过name=glyph来建立一个code与数字的字典映射就好了。
一、获取字体文件。
因为每次请求网页,获取的字体文件是不一样的,所以我们需要把字体文件保存下来。而这个字体文件的url是经过加密的,直接请求不了。不过我们发现他是经过base64进行加密的,我们只需要从网页源代码中找到这一长串字符,进行base64解码就行、
 # 获取字体文件,保存到本地
# 获取字体文件,保存到本地
def get_font_data(html):
b64 = re.search('base64,(.*?)\'\)', html)
# print(b64.group(1))
b = base64.b64decode(b64.group(1))
with open('house.ttf', 'wb') as f:
f.write(b)
二、解析字体文件,建立映射关系、
使用fonttools把字体文件转成xml,然后建立映射关系,这里要注意getBestCmap()方法获取到的code与glyph的映射中,code是十进制,要把它转换成十六进制才可以。# 解析xml文件,建立映射关系
def parse_xml():
font = TTFont('house.ttf')
font.saveXML('house.xml')
f_dict = font.getBestCmap() # 获取到的code值为十进制,需要转到十六进制
new_map = dict()
for key in f_dict.keys():
value = int(re.findall('\d+', f_dict[key])[0]) - 1
key = hex(key).replace('0', '') # 十进制转十六进制,并转换成网页中显示的样式
new_map[key] = value
return new_map
三、替换网页中的字符。
直接用replace方法对源代码进行字符替换。# 把网页中的编码替换成数字
def get_new_html(new_map, html):
for key in new_map.keys():
# print(key)
html = html.replace(key + ';', str(new_map[key]))
return html
四、完整代码。from fontTools.ttLib import TTFont
import requests
import re
import base64
from lxml import etree
# 58 同城,租房,数字字体加密
# 先将字符映射到 字符编码 ,再通过字符编码映射到真实数字
# 获取字体文件,保存到本地
def get_font_data(html):
b64 = re.search('base64,(.*?)\'\)', html)
# print(b64.group(1))
b = base64.b64decode(b64.group(1))
with open('house.ttf', 'wb') as f:
f.write(b)
# 解析xml文件,建立映射关系
def parse_xml():
font = TTFont('house.ttf')
font.saveXML('house.xml')
f_dict = font.getBestCmap() # 获取到的code值为十进制,需要转到十六进制
new_map = dict()
for key in f_dict.keys():
value = int(re.findall('\d+', f_dict[key])[0]) - 1
key = hex(key).replace('0', '') # 十进制转十六进制,并转换成网页中显示的样式
new_map[key] = value
return new_map
# 把网页中的编码替换成数字
def get_new_html(new_map, html):
for key in new_map.keys():
# print(key)
html = html.replace(key + ';', str(new_map[key]))
return html
def parse_html(html):
content = etree.HTML(html)
title_li = content.xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a/text()')
price_li = content.xpath('/html/body/div[6]/div[2]/ul/li/div[3]/div[2]/b/text()')
for title, price in zip(title_li, price_li):
print(str(title).strip(), str(price).strip())
if __name__ == '__main__':
start_url = 'https://bj.58.com/chuzu/?PGTID=0d200001-0000-19e8-01d8-7a91306f22d9&ClickID=1'
response = requests.get(url=start_url)
html = response.text
get_font_data(html)
new_map = parse_xml()
new_html = get_new_html(new_map, html)
parse_html(new_html)














 5550
5550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









