






 本文介绍了数据库锁的粒度,包括行锁、页锁、表锁等,以及从数据库管理和程序员角度对锁的划分。讨论了共享锁、排他锁和意向锁的概念,并详细阐述了乐观锁的版本号机制和时间戳机制,以及悲观锁的工作原理。最后,分析了两种锁在不同操作场景下的适用性,提供了避免死锁的策略。
本文介绍了数据库锁的粒度,包括行锁、页锁、表锁等,以及从数据库管理和程序员角度对锁的划分。讨论了共享锁、排他锁和意向锁的概念,并详细阐述了乐观锁的版本号机制和时间戳机制,以及悲观锁的工作原理。最后,分析了两种锁在不同操作场景下的适用性,提供了避免死锁的策略。
原文 https:// developer.aliyun.com/ar ticle/778217?spm=a2c6h.21072623.J_4429179800.2.5b483e04Kb9ie2&utm_content=g_1000213343
索引和锁是数据库中的两个核心知识点,隔离级别的实现都是通过锁来完成的
按照锁颗粒对锁进行划分 ?
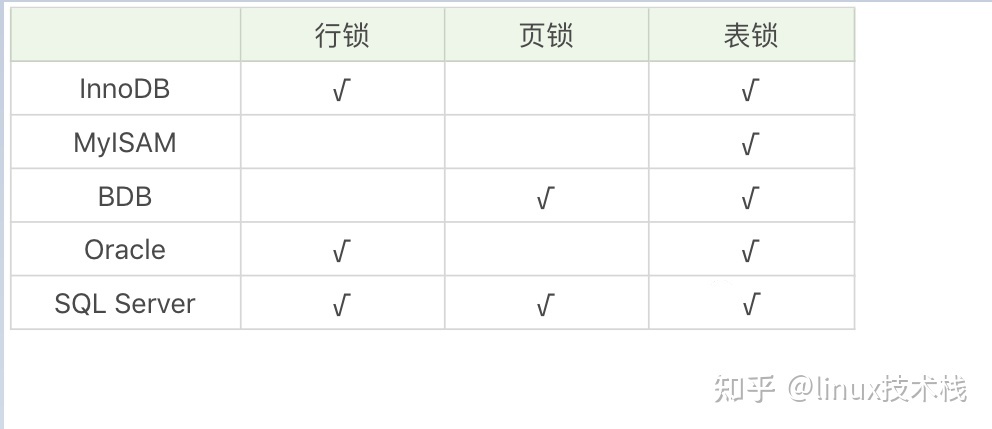
锁用来对数据进行锁定,我们可以从锁定对象的粒度大小来对锁进行划分,分别为行锁、页锁和表锁。
- 行锁就是按照行的粒度对数据进行锁定。锁定力度小,发生锁冲突概率低,可以实现的并发度高,但是对于锁的开销比较大,加锁会比较慢,容易出现死锁情况。
- 页锁就是在页的粒度上进行锁定,锁定的数据资源比行锁要多,因为一个页中可以有多个行记录。当我们使用页锁的时候,会出现数据浪费的现象,但这样的浪费最多也就是一个页上的数据行。页锁的开销介于表锁和行锁之间,会出现死锁。锁定粒度介于表锁和行锁之间,并发度一般。
- 表锁就是对数据表进行锁定,锁定粒度很大,同时发生锁冲突的概率也会较高,数据访问的并发度低。不过好处在于对锁的使用开销小,加锁会很快。
还有区锁和数据库锁.
每个层级的锁数量是有限制的,因为锁会占用内存空间,锁空间的大小是有限的。当某个层级的锁数量超过了这个层级的阈值时,就会进行锁升级。锁升级就是用更大粒度的锁替代多个更小粒度的锁,比如 InnoDB 中行锁升级为表锁,这样做的好处是占用的锁空间降低了,但同时数据的并发度也下降了。
从数据库管理的角度对锁进行划分
共享锁和排它锁
- 共享锁也叫读锁或 S 锁,共享锁锁定的资源可以被其他用户读取,但不能修改。在进行SELECT的时候,会将对象进行共享锁锁定,当数据读取完毕之后,就会释放共享锁,这样就可以保证数据在读取时不被修改。
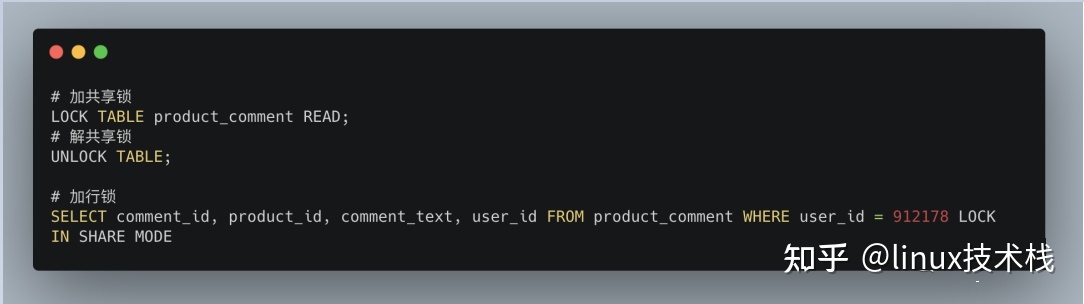
- 排它锁也叫独占锁、写锁或 X 锁。排它锁锁定的数据只允许进行锁定操作的事务使用,其他事务无法对已锁定的数据进行查询或修改。

- 当我们对数据进行更新的时候,也就是INSERT、DELETE或者UPDATE的时候,数据库也会自动使用排它锁,防止其他事务对该数据行进行操作。
意向锁(Intent Lock),简单来说就是给更大一级别的空间示意里面是否已经上过锁。
从程序员的角度对锁进行划分
乐观锁
乐观锁(Optimistic Locking)认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,也就是不采用数据库自身的锁机制,而是通过程序来实现。在程序上,我们可以采用版本号机制或者时间戳机制实现。
- 乐观锁的版本号机制
在表中设计一个版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行UPDATE ... SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。 - 乐观锁的时间戳机制
时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。
悲观锁
悲观锁(Pessimistic Locking)也是一种思想,对数据被其他事务的修改持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。
适用场景
- 乐观锁适合读操作多的场景,相对来说写的操作比较少。它的优点在于程序实现,不存在死锁问题,不过适用场景也会相对乐观,因为它阻止不了除了程序以外的数据库操作。
- 悲观锁适合写操作多的场景,因为写的操作具有排它性。采用悲观锁的方式,可以在数据库层面阻止其他事务对该数据的操作权限,防止读 - 写和写 - 写的冲突。
总结
乐观锁和悲观锁并不是锁,而是锁的设计思想。
避免死锁的发生:
- 如果事务涉及多个表,操作比较复杂,那么可以尽量一次锁定所有的资源,而不是逐步来获取,这样可以减少死锁发生的概率;
- 如果事务需要更新数据表中的大部分数据,数据表又比较大,这时可以采用锁升级的方式,比如将行级锁升级为表级锁,从而减少死锁产生的概率;
- 不同事务并发读写多张数据表,可以约定访问表的顺序,采用相同的顺序降低死锁发生的概率


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









