






mysql构架:
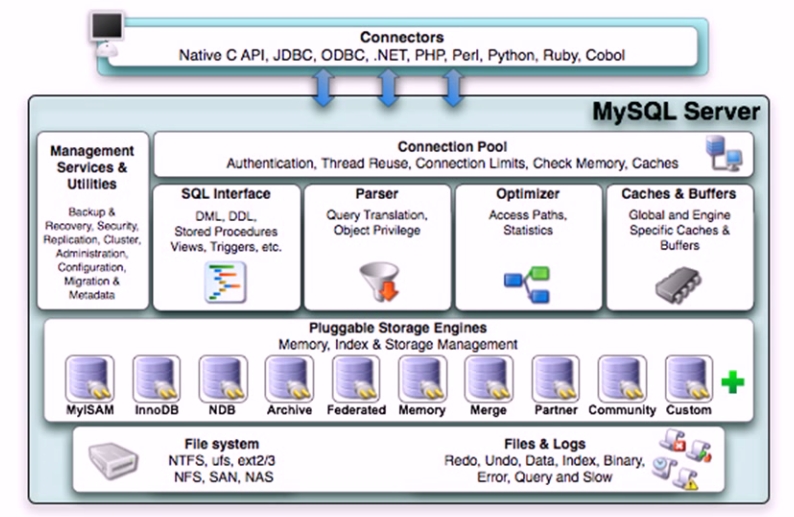
connection pool:因为单进程多线程,所以需要一个线程池接收请求提供并发,线程重用,还能完成认证
SQL interface:接收并分析SQL语句
Parser:分析器,翻译sql语句,验证用户权限,执行响应指令,生成执行树
Optimizer:优化器,通过分析索引结构,统计情况等衡量多个访问路径哪个开销最小,生成统计数据,查询语句改写
Cache & Buffer:热点数据装入内存,实现查询时加速,查询时不需要每次都调用存储引擎
存储引擎:与数据块上的数据交互,实现物理层(文件系统层面)和逻辑层(数据库层面)映射。mariadb支持自定义引擎,默认使用innodb
MySQL数据文件类型:
数据文件、索引文件
重做日志、撤消日志、二进制日志、错误日志、查询日志、慢查询日志、(中继日志)
请求处理实现流程:
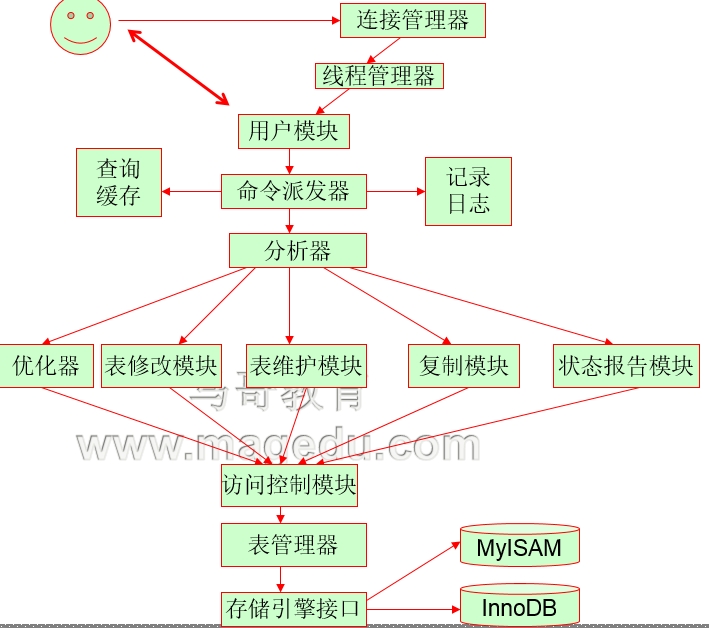
基本法则:索引应该构建在被用作查询条件的字段上;
索引类型:
B+ Tree索引:顺序存储,每一个叶子节点到根结点的距离是相同的;左前缀索引,适合查询范围类的数据;
可以使用B-Tree索引的查询类型:全键值、键值范围或键前缀查找;
全值匹配:精确某个值, "Jinjiao King";
匹配最左前缀:只精确匹配起头部分,"Jin%"
匹配范围值:
精确匹配某一列并范围匹配另一列:
只访问索引的查询
不适合使用B-Tree索引的场景:
如果不从最左列开始,索引无效; (Age,Name)
不能跳过索引中的列;(StuID,Name,Age)
如果查询中某个列是为范围查询,那么其右侧的列都无法再使用索引优化查询;(StuID,Name)
Hash索引:基于哈希表实现,特别适用于精确匹配索引中的所有列;
注意:只有Memory存储引擎支持显式hash索引;
适用场景:
只支持等值比较查询,包括=, IN(), <=>;
不适合使用hash索引的场景:
存储的非为值的顺序,因此,不适用于顺序查询;
不支持模糊匹配;
空间索引(R-Tree):
MyISAM支持空间索引;
全文索引(FULLTEXT):
在文本中查找关键词;
索引优点:
索引可以降低服务需要扫描的数据量,减少了IO次数;
索引可以帮助服务器避免排序和使用临时表;
索引可以帮助将随机I/O转为顺序I/O;
高性能索引策略:
独立使用列,尽量避免其参与运算;
左前缀索引:索引构建于字段的左侧的多少个字符,要通过索引选择性来评估
索引选择性:不重复的索引值和数据表的记录总数的比值;
多列索引:
AND操作时更适合使用多列索引;
选择合适的索引列次序:将选择性最高放左侧;
冗余和重复索引:
不好的索引使用策略索引管理:按特定数据结构存储的数据;
索引类型:
聚集索引、非聚集索引:数据是否与索引存储在一起;多级形式一般前几级非聚集,最后一级聚集,非聚集索引索引到数据块上,找到元数据进而找到数据
主键索引、辅助索引
稠密索引、稀疏索引:是否索引了每一个数据项;
B+ TREE、HASH、R TREE
简单索引、组合索引:在一个字段还是多个字段上创建索引
左前缀索引:只针对某个字段的最左边部分做索引
覆盖索引:无需查找源数据,直接通过查找索引即可得到结果
管理索引的途径:
创建索引:创建表时指定;CREATE INDEX
创建或删除索引:也可以使用修改表的命令实现创建和删除索引
删除索引:DROP INDEX
查看表上的索引:
SHOW {INDEX | INDEXES | KEYS}
{FROM | IN} tbl_name
[{FROM | IN} db_name]
[WHERE expr]
示例:
MariaDB [hellodb]> SHOW INDEXES FROM students;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| students | 0 | PRIMARY | 1 | StuID | A | 25 | NULL | NULL | | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
使用EXPLAIN分析出查询过程中是否用到索引,以及如何获取数据索引
id: 当前查询语句中,每个SELECT语句的编号;
复杂类型的查询有三种:
简单子查询;
用于FROM中的子查询;
联合查询:UNION;
注意:UNION查询的分析结果会出现一外额外匿名临时表;
select_type:
简单查询为SIMPLE
全表扫描ALL
范围查询RANGE
复杂查询:
SUBQUERY: 简单子查询;
DERIVED: 用于FROM中的子查询;
UNION:UNION语句的第一个之后的SELECT语句;
UNION RESULT: 匿名临时表;
table:SELECT语句关联到的表;
type:关联类型,或访问类型,即MySQL决定的如何去查询表中的行的方式;
ALL: 全表扫描;
index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描;
range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点;
ref: 根据索引返回表中匹配某单个值的所有行;
eq_ref:仅返回一个行,但与需要额外与某个参考值做比较;
const, system: 直接返回单个行;
possible_keys:查询可能会用到的索引;
key: 查询中使用了的索引;
key_len: 在索引使用的字节数;
ref: 在利用key字段所表示的索引完成查询时所有的列或某常量值;
rows:MySQL估计为找所有的目标行而需要读取的行数;
Extra:额外信息
Using index:MySQL将会使用覆盖索引,以避免访问表;
Using where:MySQL服务器将在存储引擎检索后,再进行一次过滤;
Using temporary:MySQL对结果排序时会使用临时表;
Using filesort:对结果使用一个外部索引排序;
MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE StuID=3;
如下:利用索引的主键实现了一对一查询
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | students | const | PRIMARY | PRIMARY | 4 | const | 1 | |
+------+-------------+----------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
如下:没使用索引,就是取得所有行,一行一行查询,效率较低
MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE AGE=53;
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | students | ALL | NULL | NULL | NULL | NULL | 25 | Using where |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
为AGE字段添加索引:
MariaDB [hellodb]> ALTER TABLE students ADD INDEX(Age);
Query OK, 25 rows affected (0.00 sec)
Records: 25 Duplicates: 0 Warnings: 0
Age字段也有了索引:
MariaDB [hellodb]> SHOW INDEXES FROM students;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| students | 0 | PRIMARY | 1 | StuID | A | 25 | NULL | NULL | | BTREE | | |
| students | 1 | Age | 1 | Age | A | NULL | NULL | NULL | | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
为Name字段创建一个索引:
MariaDB [hellodb]> CREATE INDEX name ON students (Name);
Query OK, 25 rows affected (0.01 sec)
Records: 25 Duplicates: 0 Warnings: 0
查看:
MariaDB [hellodb]> SELECT * FROM students WHERE Name LIKE 'X%';
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 7 | Xi Ren | 19 | F | 3 | NULL |
| 22 | Xiao Qiao | 20 | F | 1 | NULL |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 24 | Xu Xian | 27 | M | NULL | NULL |
| 16 | Xu Zhu | 21 | M | 1 | NULL |
| 19 | Xue Baochai | 18 | F | 6 | NULL |
+-------+-------------+-----+--------+---------+-----------+
查看语句执行分析:是一个基于范围的查询,查询了6个
MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE Name LIKE 'X%';
+------+-------------+----------+-------+---------------+------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+------+---------+------+------+-----------------------+
| 1 | SIMPLE | students | range | name | name | 152 | NULL | 6 | Using index condition |
+------+-------------+----------+-------+---------------+------+---------+------+------+-----------------------+
1 row in set (0.00 sec)
全表扫描式查询:查询了25个
MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE Name LIKE '%X%';
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | students | ALL | NULL | NULL | NULL | NULL | 25 | Using where |
+------+-------------+----------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)视图:view虚表,一个select语句得到的结果保存为虚表,可以对这个虚表继续执行查询作,修改
创建方法:
CREATE
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
创建一个视图:
MariaDB [hellodb]> CREATE VIEW test AS SELECT StuID,Name,Age FROM students;
Query OK, 0 rows affected (0.05 sec)
查看发现出现了视图表test:
MariaDB [hellodb]> SHOW TABLES;
+-------------------+
| Tables_in_hellodb |
+-------------------+
| classes |
| coc |
| courses |
| scores |
| students |
| teachers |
| test |
| toc |
+-------------------+
8 rows in set (0.00 sec)
查看虚表状态:
MariaDB [hellodb]> SHOW TABLE STATUS LIKE 'test'\G;
*************************** 1. row ***************************
Name: test
Engine: NULL
Version: NULL
Row_format: NULL
Rows: NULL
Avg_row_length: NULL
Data_length: NULL
Max_data_length: NULL
Index_length: NULL
Data_free: NULL
Auto_increment: NULL
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: NULL
Checksum: NULL
Create_options: NULL
Comment: VIEW
1 row in set (0.00 sec)
ERROR: No query specified
查询一下发现只有3个字段,因为我们创建时指定了这3个字段
MariaDB [hellodb]> SELECT * FROM test WHERE Age=22;
+-------+---------------+-----+
| StuID | Name | Age |
+-------+---------------+-----+
| 1 | Shi Zhongyu | 22 |
| 2 | Shi Potian | 22 |
| 21 | Huang Yueying | 22 |
+-------+---------------+-----+
3 rows in set (0.00 sec)
查看执行分析:
MariaDB [hellodb]> EXPLAIN SELECT * FROM test WHERE Age=22\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: students
type: ref
possible_keys: Age
key: Age
key_len: 1
ref: const
rows: 2
Extra:
1 row in set (0.00 sec)
ERROR: No query specified
#视图中的数据事实上存储于“基表”中,因此,其修改操作也会针对基表实现;其修改操作受基表限制;
删除视图:
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
mysql中SELECT专题:
查询执行路径中的组件:查询缓存、解析器、预处理器、优化器、查询执行引擎、存储引擎;
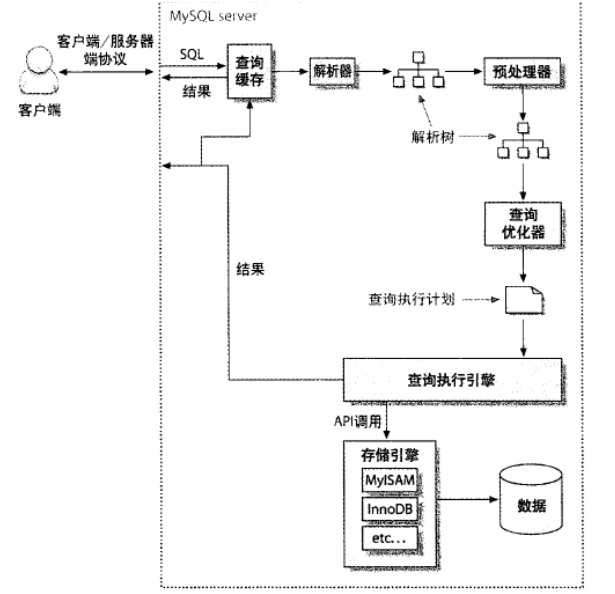
SELECT FROM ORDER BY 查询后做排序
SELECT FROM GROUP BY HAVING 查询后分组,分组后指明过滤条件做过滤
SELECT FROM WHERE
SELECT FROM WHERE GROUP BY LIMIT 查询后分组,然后仅显示一部分内容
SELECT FROM HAING
GROUP和HAVING,LIMIT是可选的
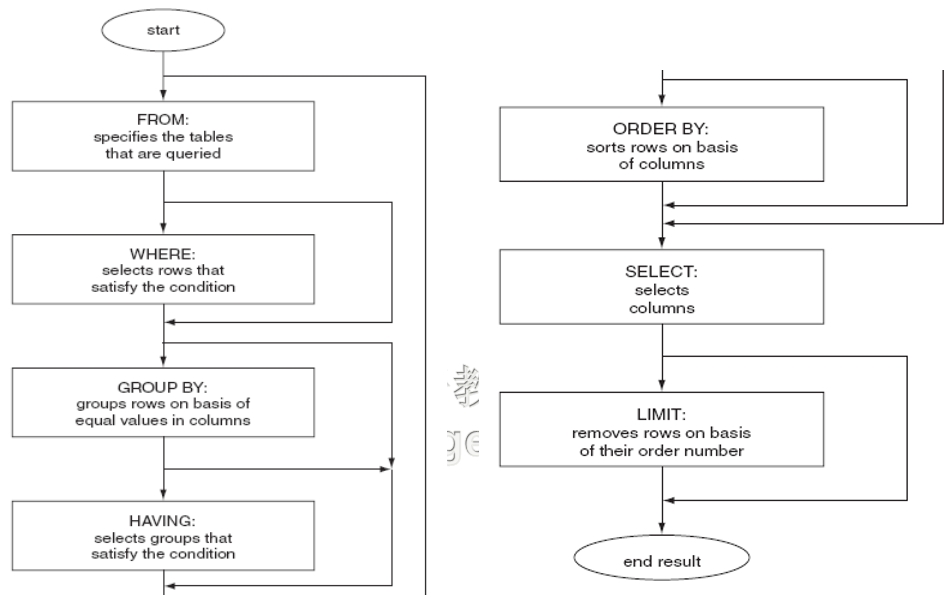
总结:FROM Clause --> WHERE Clause --> GROUP BY --> HAVING Clause --> ORDER BY --> SELECT --> LIMIT典型的不使用缓存查询:(因为时间一直在变)
MariaDB [(none)]> SELECT now();
+---------------------+
| now() |
+---------------------+
| 2015-11-03 09:37:24 |
+---------------------+
1 row in set (0.00 sec)
1.单表查询:去重使用DESTINCT:
MariaDB [hellodb]> SELECT GENDER FROM students;
+--------+
| GENDER |
+--------+
| M |
| M |
| M |
| M |
| M |
| M |
| F |
| F |
| F |
| F |
| M |
| F |
| M |
| F |
| M |
| M |
| M |
| M |
| F |
| F |
| F |
| F |
| M |
| M |
| M |
| M |
+--------+
发现变化了么吗:DISTINCT查询后数据去重
MariaDB [hellodb]> SELECT DISTINCT GENDER FROM students;
+--------+
| GENDER |
+--------+
| M |
| F |
+--------+
2 rows in set (0.00 sec)
SQL_CACHE: 显式指定存储查询结果于缓存之中;
SQL_NO_CACHE: 显式查询结果不予缓存;
MariaDB [hellodb]> SELECT SQL_CACHE DISTINCT Gender FROM students;
+--------+
| Gender |
+--------+
| M |
| F |
+--------+
2 rows in set (0.00 sec)
query_cache_type的值为'ON'时,查询缓存功能打开;SELECT的结果符合缓存条件即会缓存,否则,不予缓存;如果显示指定SQL_NO_CACHE: 显式查询结果不予缓存;
query_cache_size值为0也不会缓存,想缓存就需要调整大于0
query_cache_type的值为'DEMAND'时,查询缓存功能按需进行;显式指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存
MariaDB [hellodb]> SHOW GLOBAL VARIABLES LIKE 'query%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| query_alloc_block_size | 8192 |
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 0 |
| query_cache_strip_comments | OFF |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
| query_prealloc_size | 8192 |
+------------------------------+---------+
8 rows in set (0.00 sec)
查看缓存状态属性:
MariaDB [hellodb]> SHOW GLOBAL STATUS LIKE 'Qcache%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Qcache_free_blocks | 0 |
| Qcache_free_memory | 0 |
| Qcache_hits | 0 | #命中次数
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 0 |
+-------------------------+-------+
8 rows in set (0.01 sec)
MariaDB [hellodb]> SHOW GLOBAL STATUS LIKE 'Com_select';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_select | 8 | #查询总次数
+---------------+-------+
1 row in set (0.00 sec)
缓存命中率的评估:Qcache_hits命中次数/(Qcache_hits+Com_select)总次数
字段显示可以使用别名:
col1 AS alias1, col2 AS alias2, ...
MariaDB [hellodb]> SELECT Name AS StuName FROM students;
+---------------+
| StuName |
+---------------+
| Diao Chan |
| Ding Dian |
WHERE子句:
指明过滤条件以实现“选择”的功能:
过滤条件:布尔型表达式;
算术操作符:+, -, *, /, %
比较操作符:=, !=, <>, <=>, >, >=,
!=和<>都表示不等于
<==>:在做比较时如果对方方出现空值没法比较,这个表示跟空值比较时也可安全执行
BETWEEN min_num AND max_num
IN (element1, element2, ...)等值或条件表达式
IS NULL
IS NOT NULL
示例:
MariaDB [hellodb]> SELECT Name,Age FROM students WHERE Age IN (18,100);
+-------------+-----+
| Name | Age |
+-------------+-----+
| Xue Baochai | 18 |
| Sun Dasheng | 100 |
+-------------+-----+
2 rows in set (0.03 sec)
MariaDB [hellodb]> SELECT Name,ClassID FROM students WHERE ClassID IS NULL;
+--------------+---------+
| Name | ClassID |
+--------------+---------+
| Xu Xian | NULL |
| Sun Dasheng | NULL |
| Yinjiao King | NULL |
+--------------+---------+
3 rows in set (0.00 sec)
LIKE:
%: 任意长度的任意字符;
_:任意单个字符;
RLIKE:基于正则表达式匹配
REGEXP:匹配字符串可用正则表达式书写模式;
逻辑操作符:组合多个条件进行查询NOT,AND,OR,XOR
GROUP字句:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算:
avg(), max(), min(), count(), sum()
统计男女同志的平均年龄:
MariaDB [hellodb]> SELECT avg(Age),Gender FROM students GROUP BY Gender;
+----------+--------+
| avg(Age) | Gender |
+----------+--------+
| 19.0000 | F |
| 37.0625 | M |
+----------+--------+
2 rows in set (0.00 sec)
HAVINGD对group后的结果作过滤:
MariaDB [hellodb]> SELECT avg(Age)as AAge,Gender FROM students GROUP BY Gender HAVING AAge>20;
+---------+--------+
| AAge | Gender |
+---------+--------+
| 37.0625 | M |
+---------+--------+
1 row in set (0.00 sec)
count()函数可以计算总数
MariaDB [hellodb]> SELECT count(StuID) AS NOS,ClassID FROM students GROUP BY ClassID HAVING NOS >2;
+-----+---------+
| NOS | ClassID |
+-----+---------+
| 3 | NULL |
| 4 | 1 |
| 3 | 2 |
| 4 | 3 |
| 4 | 4 |
| 4 | 6 |
| 3 | 7 |
+-----+---------+
7 rows in set (0.00 sec)
3.ORDER BY: 根据指定的字段对查询结果进行排序;
升序:ASC
降序:DESC
MariaDB [hellodb]> SELECT count(StuID) AS NOS,ClassID FROM students GROUP BY ClassID HAVING NOS >2 ORDER BY NOS DESC;
+-----+---------+
| NOS | ClassID |
+-----+---------+
| 4 | 6 |
| 4 | 1 |
| 4 | 4 |
| 4 | 3 |
| 3 | NULL |
| 3 | 2 |
| 3 | 7 |
+-----+---------+
7 rows in set (0.00 sec)
4.LIMIT [[offset,]row_count]:对查询的结果进行输出行数数量限制;
显示第11到20个,第一个10表示偏移量,第二个做计数
MariaDB [hellodb]> SELECT Name,Age FROM students ORDER BY Age DESC LIMIT 10,10;
+---------------+-----+
| Name | Age |
+---------------+-----+
| Hua Rong | 23 |
| Yuan Chengzhi | 23 |
| Huang Yueying | 22 |
| Shi Zhongyu | 22 |
| Shi Potian | 22 |
| Xu Zhu | 21 |
| Ren Yingying | 20 |
| Xiao Qiao | 20 |
| Xi Ren | 19 |
| Duan Yu | 19 |
+---------------+-----+
10 rows in set (0.00 sec)
对查询结果中的数据请求施加“锁”:
FOR UPDATE: 写锁,排他锁;
LOCK IN SHARE MODE: 读锁,共享锁
2.多表查询:
交叉连接:笛卡尔乘积;
内连接:
等值连接:让表之间的字段以“等值”建立连接关系;让两张表中表示同一意义的字段建立等值连接关系
不等值连接
自然连接
自连接
外连接:
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外连接
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col笛卡尔乘积:不建议已使用,效率很差
SELECT * FROM students;
26 rows in set (0.00 sec)
MariaDB [hellodb]> SELECT * FROM teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
4 rows in set (0.00 sec)
SELECT * FROM students,teachers;
104 rows in set (0.00 sec) #是前面两个表行数之积
等值连接:让表之间的字段以“等值”建立连接关系
MariaDB [hellodb]> SELECT * FROM students,teachers WHERE students.TeacherID=teachers.TID;
+-------+-------------+-----+--------+---------+-----------+-----+---------------+-----+--------+
| StuID | Name | Age | Gender | ClassID | TeacherID | TID | Name | Age | Gender |
+-------+-------------+-----+--------+---------+-----------+-----+---------------+-----+--------+
| 5 | Yu Yutong | 26 | M | 3 | 1 | 1 | Song Jiang | 45 | M |
| 1 | Shi Zhongyu | 22 | M | 2 | 3 | 3 | Miejue Shitai | 77 | F |
| 4 | Ding Dian | 32 | M | 4 | 4 | 4 | Lin Chaoying | 93 | F |
+-------+-------------+-----+--------+---------+-----------+-----+---------------+-----+--------+
两张表中按照指定字段字段进行等值连接
MariaDB [hellodb]> SELECT s.Name AS StuName,t.Name AS TeaName FROM students AS s,teachers AS t WHERE s.TeacherID=t.T;
+-------------+---------------+
| StuName | TeaName |
+-------------+---------------+
| Yu Yutong | Song Jiang |
| Shi Zhongyu | Miejue Shitai |
| Ding Dian | Lin Chaoying |
+-------------+---------------+
3 rows in set (0.00 sec)
看下分析结果:
MariaDB [hellodb]> EXPLAIN SELECT s.Name AS StuName,t.Name AS TeaName FROM students AS s,teachers AS t WHERE s.TeacherID=t.TID\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 26
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using where; Using join buffer (flat, BNL join)
2 rows in set (0.00 sec)
左外连接:
MariaDB [hellodb]> SELECT s.Name,c.Class FROM students AS s LEFT JOIN classes AS c ON s.ClassID=c.ClassID;
+---------------+----------------+
| Name | Class |
+---------------+----------------+
| Shi Zhongyu | Emei Pai |
| Shi Potian | Shaolin Pai |
| Xie Yanke | Emei Pai |
| Ding Dian | Wudang Pai |
| Yu Yutong | QingCheng Pai |
| Shi Qing | Riyue Shenjiao |
| Xi Ren | QingCheng Pai |
| Lin Daiyu | Ming Jiao |
| Ren Yingying | Lianshan Pai |
| Yue Lingshan | QingCheng Pai |
| Yuan Chengzhi | Lianshan Pai |
| Wen Qingqing | Shaolin Pai |
| Tian Boguang | Emei Pai |
| Lu Wushuang | QingCheng Pai |
| Duan Yu | Wudang Pai |
| Xu Zhu | Shaolin Pai |
| Lin Chong | Wudang Pai |
| Hua Rong | Ming Jiao |
| Xue Baochai | Lianshan Pai |
| Diao Chan | Ming Jiao |
| Huang Yueying | Lianshan Pai |
| Xiao Qiao | Shaolin Pai |
| Ma Chao | Wudang Pai |
| Xu Xian | NULL |
| Sun Dasheng | NULL |
| Yinjiao King | NULL |
+---------------+----------------+
26 rows in set (0.03 sec)
自连接:
MariaDB [hellodb]> SELECT s.Name,t.Name FROM students AS s,students AS t WHERE s.TeacherID=t.StuID;
+-------------+-------------+
| Name | Name |
+-------------+-------------+
| Shi Zhongyu | Xie Yanke |
| Shi Potian | Xi Ren |
| Xie Yanke | Xu Zhu |
| Ding Dian | Ding Dian |
| Yu Yutong | Shi Zhongyu |
+-------------+-------------+
5 rows in set (0.00 sec)
子查询:在查询语句嵌套着查询语句,基于某语句的查询结果再次进行的查询用在WHERE子句中的子查询:
(1) 用于比较表达式中的子查询;子查询仅能返回单个值;
MariaDB [hellodb]> SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age) FROM students);
+--------------+-----+
| Name | Age |
+--------------+-----+
| Ding Dian | 32 |
| Tian Boguang | 33 |
| Shi Qing | 46 |
| Xie Yanke | 53 |
| Yinjiao King | 98 |
| Sun Dasheng | 100 |
+--------------+-----+
6 rows in set (0.00 sec)
MariaDB [hellodb]> EXPLAIN SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age) FROM students);
+------+-------------+----------+-------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+----------+-------+---------------+------+---------+------+------+-------------+
| 1 | PRIMARY | students | range | Age | Age | 1 | NULL | 7 | Using where |
| 2 | SUBQUERY | students | index | NULL | Age | 1 | NULL | 26 | Using index |
+------+-------------+----------+-------+---------------+------+---------+------+------+-------------+
2 rows in set (0.00 sec)
(2) 用于IN中的子查询:子查询应该单键查询并返回一个或多个值从构成列表;
SELECT Name,Age FROM students WHERE Age IN (SELECT Age FROM teachers);
(3) 用于EXISTS;
用于FROM子句中的子查询;
使用格式:SELECT tb_alias.col1,... FROM (SELECT clause) AS tb_alias WHERE Clause;
示例:
SELECT s.aage,s.ClassID FROM (SELECT avg(Age) AS aage,ClassID FROM students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS s WHERE s.aage>30;
+---------+---------+
| aage | ClassID |
+---------+---------+
| 36.0000 | 2 |
| 46.0000 | 5 |
+---------+---------+
2 rows in set (0.00 sec)
联合查询:UNION
SELECT Name,Age FROM students UNION SELECT Name,Age FROM teachers;
MariaDB [hellodb]> EXPLAIN SELECT Name,Age FROM students UNION SELECT Name,Age FROM teachers;
+------+--------------+------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+--------------+------------+------+---------------+------+---------+------+------+-------+
| 1 | PRIMARY | students | ALL | NULL | NULL | NULL | NULL | 26 | |
| 2 | UNION | teachers | ALL | NULL | NULL | NULL | NULL | 4 | |
| NULL | UNION RESULT | | ALL | NULL | NULL | NULL | NULL | NULL | |
+------+--------------+------------+------+---------------+------+---------+------+------+-------+
查询缓存:
如何判断是否命中:
通过查询语句的哈希值判断:哈希值考虑的因素包括
查询本身、要查询的数据库、客户端使用协议版本,...
查询语句任何字符上的不同,都会导致缓存不能命中;
哪此查询可能不会被缓存?
查询中包含UDF、存储函数、用户自定义变量、临时表、mysql库中系统表、或者包含列级权限的表、有着不确定值的函数(Now());
查询缓存相关的服务器变量:
query_cache_min_res_unit: 查询缓存中内存块的最小分配单位;
较小值会减少浪费,但会导致更频繁的内存分配操作;
较大值会带来浪费,会导致碎片过多;
query_cache_limit:能够缓存的最大查询结果;
对于有着较大结果的查询语句,建议在SELECT中使用SQL_NO_CACHE
query_cache_size:查询缓存总共可用的内存空间;单位是字节,必须是1024的整数倍;
query_cache_type: ON, OFF, DEMAND
query_cache_wlock_invalidate:如果某表被其它的连接锁定,是否仍然可以从查询缓存中返回结果;默认值为OFF,表示可以在表被其它连接锁定的场景中继续从缓存返回数据;ON则表示不允许;查询相关的状态变量
SHOW GLOBAL STATUS LIKE 'Qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 16759688 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+----------+















 3444
3444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









