







推荐基础算法之矩阵分解WMF
在推荐的领域中,大量的文献都聚焦于处理显示反馈(explicit feedback)。这可能归功于这种显示信息的使用方便。然而,在很多实际情况下,推荐系统还要处理另外一种数据,即隐式反馈数据(implicit feedback),如购买记录 (purchase history), 浏览记录(browsing history)、搜索模式(search patterns)、鼠标移动(mouse movements)、点击历史(clickthrough history) 或签到记录(check-in records)等。显示反馈数据与隐式反馈最大的区别在于显示反馈数据可以明确的表示出用户的偏好,如Netflix的电影评分(评级为1-5分)-高分表示用户喜欢这部电影,低分表示用户不喜欢这部电影,而隐式反馈数据并没有这样直接的反馈,它只有单类反馈,相反它需要我们从隐式反馈数据中推断出用户的偏好。
下面我们将列出4点隐式反馈数据的独有特性:
- 没有负反馈(No negative feedback): 隐式反馈数据中只收集了正反馈(positive feedback),而没有负反馈,且没有观察的反馈为缺失值和负反馈的混合。通过观察用户行为数据,我们可以推断出用户可能喜欢哪个物品,但很难去轻易的推断出用户不喜欢哪一个物品。例如,一个用户没有去看某个节目的原因可能是她不喜欢这个节目或因为她还不知道有这个节目存在。这种不对称的信息在显示反馈中并不存在,因为其清晰地告诉我们用户喜欢什么和不喜欢什么。
- 固有噪声(Implicit feedback is inherently noisy):尽管我们可以追溯用户的行为,但我们也仅仅猜测其偏好和真实意图。例如,我们可以观察到一个用户的购买记录,但这并不代表用户对这些产品有着积极的偏好,因为这些物品可能被购买作为礼物,或在特定时间观看特定节目的用户,有可能在睡觉。
- 数值表示置信度(confidence): 显示反馈的数值表示用户的偏好,而隐式反馈的数值表示的置信度。隐式反馈中的数值可以是描述某行为的频率或某行为的二值状态(如是否收藏某网页)。且隐式反馈中频率越大并不表示越高的偏好(如最爱的电影只看一遍,而相对喜爱的系列电影每周可能都看),而是它告诉我们某种行为的置信度。且需要注意到的是一次事件发生有可能是巧合的,与用户偏好无关。而,经常发生的事件更有可能反应用户的选择。
- 隐式反馈推荐需要合适的评估指标:很多隐式反馈数据都被用于top-N的推荐中,因此传统评分评估指标肯定不适用于top-N推荐中。
在进入正题之前,我们先对推荐系统中的单类协同过滤问题(One-Class Collaborative Filtering, OCCF)做出一个定义:把只存在正样本的协同过滤称为OCCF。
因此这篇文章主要对算法WMF(Weighted Matrix Factorization)进行理解和记录。(出自论文《One-Class Collaborative Filtering》和《Collaborative Filtering for Implicit Feedback Datasets》)。上面两篇文献都是发表在2008年ICDM上。思想也趋于相同,但OCCF中考虑了更详细的细节和方法。鉴于这两篇文章所依赖数据集形式的小差异,我们先将在两篇文章背景下进行算法阐述。最后在整理WMF。
1.One-Class Collaborative Filtering
对于单类协同过滤问题,有三种直观的解决方式。
第一种策略是通过标注负例来将数据转化成一个传统的协同过滤问题。但是这种策略成本太大了,因为需要人工实现,这会给用户带来不好的体验。
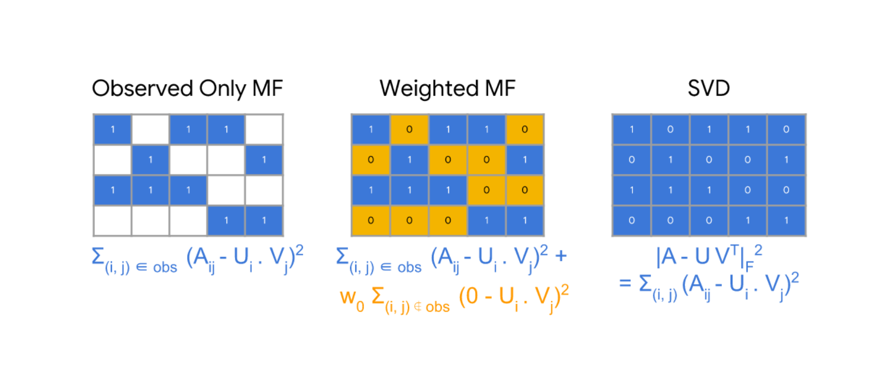
第二种策略是将所有缺失的值作为负例(All Missing Are Negative, AMAN)。对正例和负例进行赋值,转换成显示反馈数据。因此传统的协同过滤方法可以直接应用。如SVD,基于记忆的协同过滤等。然而这样处理数据会存在一个缺点,就是缺失值赋可能是正例,因此导致推荐结果有偏差。
第三种策略是将缺失值看成未知的(All missing as unknown, AMAU),忽视所有的缺失样本并且只利用正例来通过分类算法进行预测。这种方法也存在一个很明显的缺陷,就是会对丢失的数据的预测都是正例,没有区分性,因此会产生一些没有意义的结果。
《One-Class Collaborative Filtering》这篇文章的主要思想就是用来平衡缺失值作为负例情况。对应地,作者
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6804
6804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









