






Spark 并没有止步不前。
Spark 和 Flink 两个项目的核心 API 基本一致,Spark 在机器学习整合方面投入更多,Flink 在流处理方面更赞(这也是大家在 2016 年开始关注 Flink 的原因),当然二者最大的区别,也还在于对流式计算的支持。这句的潜在含义就是 Spark 存在的道理:尽管 Spark Steaming 现在和 Flink 相比优势不显,但它的生态更为丰富,除了 Streaming 还有 SQL、MLib、Graphx 等,同时目前 Spark 对 Kubernetes 云原生技术的原生支持更加到位。
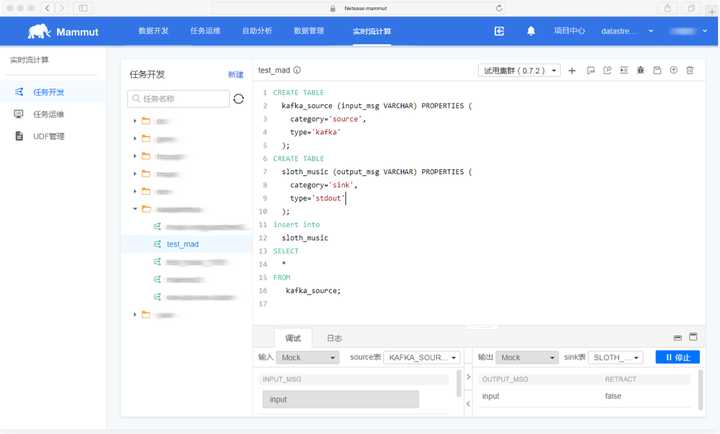
网易猛犸大数据平台,在流计算也采用基于 Flink 研发的 Sloth,支持使用 SQL 开发流式计算任务,兼容离线 SQL,可实时分析用户的访问数据,展示流量变化和用户分布情况。但是但是但是,我们在计算层并没有放弃支持 Spark ,就是因为上面的道理。
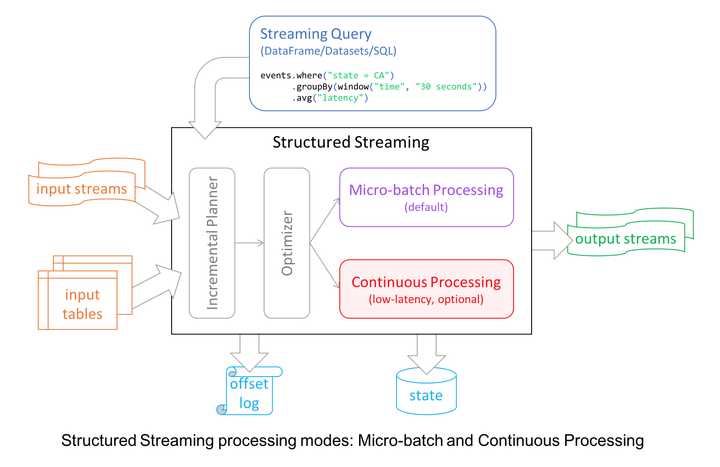
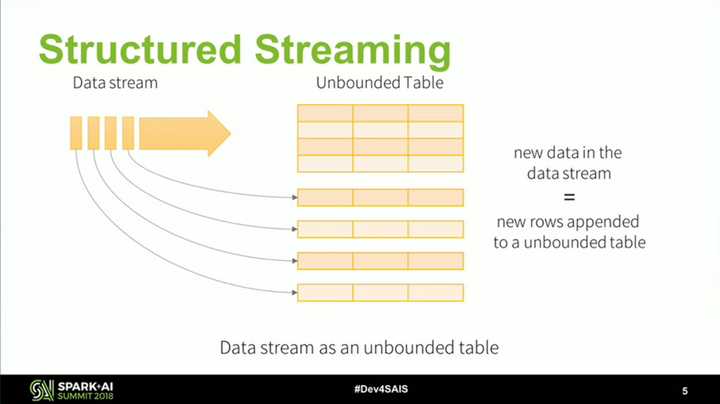
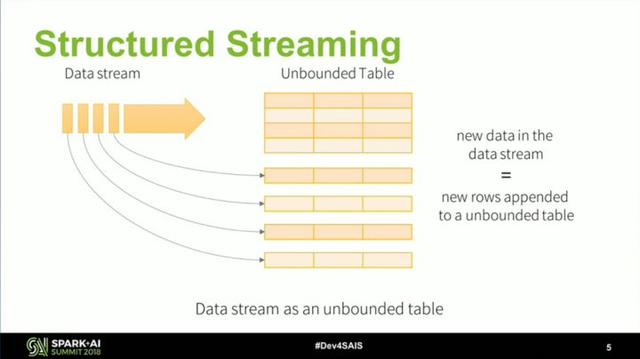
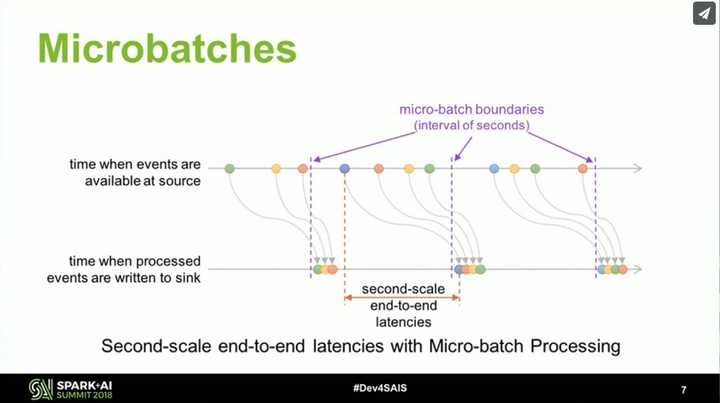
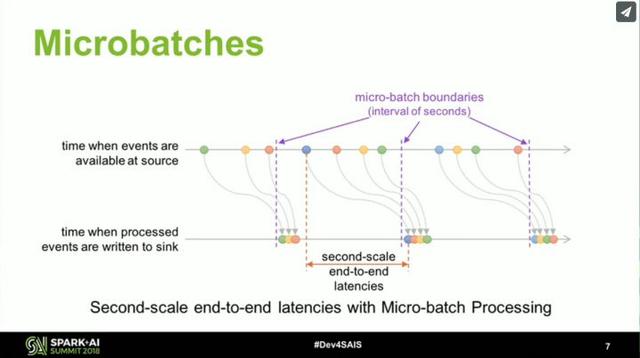
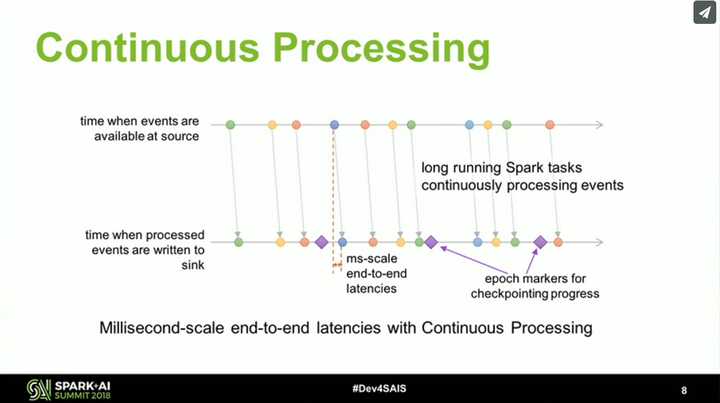
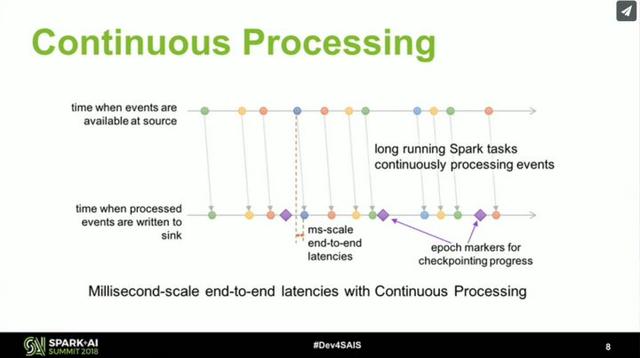
再看 Spark 在流计算方面的努力,它从 2.0 开始引入了 Structured Streaming,重新整理流计算的语义,使用微批(Micro-Batch)处理执行模型,支持按事件时间处理和端到端的一致性,并在 2.3 实现了 初始的持续处理(Continuous Processing)。根据官方介绍,Spark 执行引擎未来的发展会和 Flink 类似。这并不是最新的消息,很多功能还比较初级,但 Spark 早有规划,相信 Spark 凭借比 Flink 更为成熟的社区,会给出一个令人惊喜的答案。



更多详情请参考官方博客与视频:
Introducing Low-latency Continuous Processing Mode in Structured Streaming in Apache Spark 2.3
Continuous Processing in Structured Streaming
作者:网易云
链接:https://www.zhihu.com/question/306432813/answer/568585759
来源:知乎















 4886
4886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









