







使用 Fiddler 抓包分析公众号
打开微信随便选择一个公众号,查看公众号的所有历史文章列表

在 Fiddler 上已经能看到有请求进来了,说明公众号的文章走的都是HTTPS协议,这些请求就是微信客户端向微信服务器发送的HTTP请求。
模拟微信请求
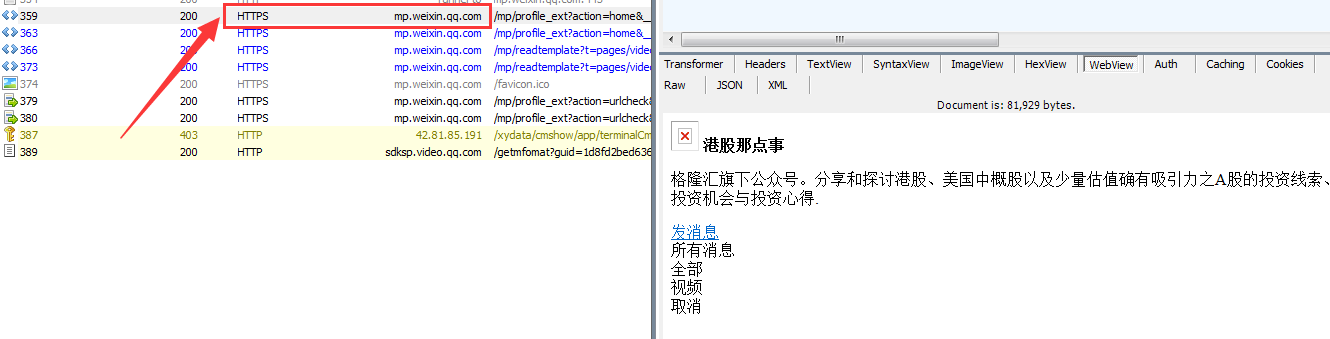
1、服务器的响应结果,200 表示服务器对该请求响应成功
2、请求协议,微信的请求协议都是基 于HTTPS 的,所以Fiddle一定要配置好,不然你看不到 HTTPS 的请求。
3、请求路径,包括了请求方法(GET),请求协议(HTTP/1.1),请求路径(/mp/profile_ext...后面还有很长一串参数)
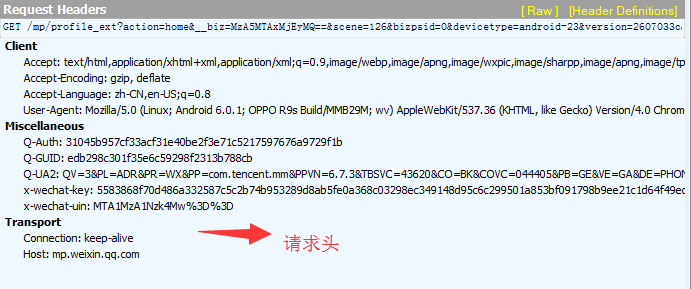
4、包括Cookie信息在内的请求头。
5、微信服务器返回的响应数据。
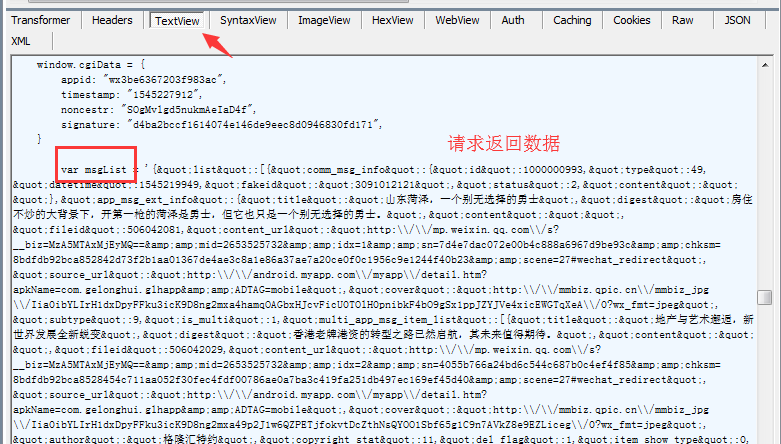
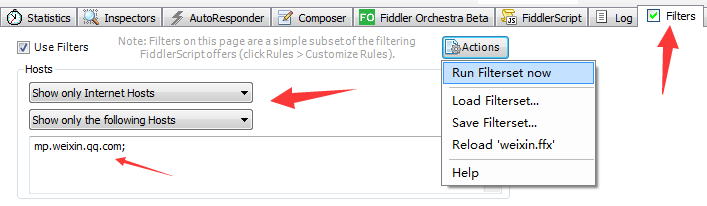
确定微信公众号的请求HOST是 mp.weixin.qq.com 之后,我们可以使用过滤器来过滤掉不相关的请求。
爬虫的基本原理就是模拟浏览器发送 HTTP 请求,然后从服务器得到响应结果,现在我们就用 Python 实现如何发送一个 HTTP 请求。这里我们使用 requests 库来发送请求。
拷贝URL和请求头
1:找到完整URL请求地址
2:找到完整的请求头(headers)信息,Headers里面包括了cookie、User-agent、Host 等信息。
我们直接从 Fiddler 请求中拷贝 URL 和 Headers, 右键 -> Copy -> Just Url/Headers Only
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









