






zipentry
解决方法(Code)在文章最后面,耐心看完
今天在项目中遇到一个问题,有一个需求是需要验证下载的ZIP文件,解压读取ZIP文件夹内部的文件,文件名称以及大小。
网上搜了下,发现,不用解压可以直接读取,代码如下:
package com.sd.test.readzip;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.fileinputstream;
import java.io.IOException;
import java.io.InputStream;
import java.io.inputstreamreader;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
import java.util.zip.ZipInputStream;
//注意要将文件保存为utf-8,txt文件的默认保存为ANSI.要改成urf-8不然会像file:ziptestfile/fileInZip.txt
public class ReadZip {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
ReadZip rz=new ReadZip();
rz.readZipcontext();
}
public void readZipContext() throws IOException{
String zipPath="zipFile/ziptestfile.zip";
ZipFile zf=new ZipFile(zipPath);
InputStream in=new BufferedInputStream(new FileInputStream(zipPath));
ZipInputStream zin=new ZipInputStream(in);
//ZipEntry 类用于表示 ZIP 文件条目。
ZipEntry ze;
while((ze=zin.getNextEntry())!=null){
if(ze.isDirectory()){
//为空的文件夹什么都不做
}else{
System.err.println("file:"+ze.getName()+"\nsize:"+ze.getSize()+"bytes");
if(ze.getSize()>0){
BufferedReader reader;
try {
reader = new BufferedReader(new InputStreamReader(zf.getInputStream(ze), "utf-8"));
String line=null;
while((line=reader.readLine())!=null){
System.out.println(line);
}
reader.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printstacktrace();
}
}
}
}
}
}
但是后面发现一个问题,读取的时候总是返回-1 ze.getSize()的值总是-1,可是名字都到了。
找不到法子,着实无奈,后面换了种方式,干脆将文件解压出来之后,在对文件里面的内容进行验证文件名和文件大小好了
public void BATchReportZIP(String filePath) throws Exception{
FileChannel fc= null;
String unzipPath = filePath.substring(0, filePath.indexof('.'));
File file = new File(filePath);
unZipFiles(file, unzipPath);//解压
File desc = new File(unzipPath);
String[] filelist = desc.list();
for (int i = 0; i < filelist.length; i++) {
File readfile = new File(unzipPath + "\\" + filelist[i]);
if (!readfile.isDirectory()) {
FileInputStream fis= new FileInputStream(readfile.getPath().toString());
fc= fis.getChannel();
System.out.println("文件大小是:"+getNetFileSizeDescription(fc.size()));
Assert.assertTrue(fc.size() >= 1, "文件名字:"+readfile.getName()+"断言描述文件大小是["+fc.size()+"] Please double Check!");
//这里可以加一些更多的断言验证,针对里面的文件
}else{
System.out.println(readfile+filelist[i]+"is Directory, please check!");
break;
}
}
}
//这里是转换bytes显示成KB,MB,GB这样更常态化!
public static String getNetFileSizeDescription(long size) {
StringBuffer bytes = new StringBuffer();
decimalformat format = new DecimalFormat("###.0");
if (size >= 1024 * 1024 * 1024) {
double i = (size / (1024.0 * 1024.0 * 1024.0));
bytes.APPend(format.format(i)).append("GB");
}
else if (size >= 1024 * 1024) {
double i = (size / (1024.0 * 1024.0));
bytes.append(format.format(i)).append("MB");
}
else if (size >= 1024) {
double i = (size / (1024.0));
bytes.append(format.format(i)).append("KB");
}
else if (size < 1024) {
if (size <= 0) {
bytes.append("0B");
}
else {
bytes.append((int) size).append("B");
}
}
return bytes.toString();
}
//解压ZIP文件到文件夹
public static void unZipFiles(File zipFile,String descDir)throws IOException {
File pathFile = new File(descDir);
if(!pathFile.exists()) {
pathFile.mkdirs();
}
ZipFile zip = new ZipFile(zipFile);
for(Enumeration entries = zip.entries(); entries.hasMoreElements();){
ZipEntry entry = (ZipEntry)entries.nextElement();
String zipEntryName = entry.getName();
if(zipEntryName.endsWith(".pdf")) {
InputStream in = zip.getInputStream(entry);
//unzip all report to folder.
String outPath = (descDir+"/"+zipEntryName).replaceAll("\\*", "/");
if(new File(outPath).isDirectory()){
continue;//
}
//print the OutPath information
System.out.println("PDF OutPath:"+outPath);
outputstream out = new FileOutputStream(outPath);
byte[] buf1 = new byte[1024];
int len;
while((len=in.read(buf1))>0){
out.write(buf1,0,len);
}
in.close();
out.close();
}else {
}
}
System.out.println("******************extract the complete********************");
}
最后发现,着实繁琐,能不能三两行代码解决问题。
后来又继续网上搜索了半天,问了下同事,突然之间找到了一种新的解决方式。成功搞定,代码如下:
//String path = "D://PDF//PDF Get File//PDF Get File.zip";
ZipFile zf = new ZipFile(filePath);
java.util.Enumeration zipEnum = zf.entries();
InputStream in = new BufferedInputStream(new FileInputStream(filePath));
while(zipEnum.hasMoreElements ()){
ZipEntry ze = (ZipEntry) zipEnum.nextElement();
if(ze.isDirectory()){
//为空的文件夹什么都不做
}else{
System.err.println("file:"+ze.getName()+"\nsize:"+ze.getSize()+"bytes\nCompressedSize:"+ze.getCompressedSize());
if(ze.getSize()>0){
}
}
}
in.close();
成功解决:
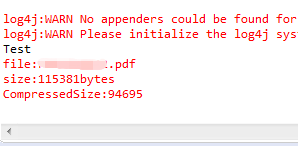
分析下原因是因为:
把判断条件由【(ze=zin.getNextEntry())!=null】换成【zipEnum.hasMoreElements ()】
使用了枚举, Enumeration 接口(枚举)。
通常用 Enumeration 中的以下两个方法打印向量中的所有元素:
(1) boolean hasMoreElements(); // 是否还有元素,如果返回 true ,则表示至少含有一个元素
(2) public Object nextElement(); // 如果 Enumeration 枚举对象还含有元素,该方法返回对象中的下一个元素。如果没有,则抛出NoSuchElementException 异常。
相关阅读
from:https://blog.csdn.net/qingchuwudi/article/details/25785307
位图(bmp)文件格式分析
作者:深蓝(由博主分享)
一、什么是位图
ResourceBundle与Properties的区别在于ResourceBundle通常是用于国际化的属性配置文件读取,Properties则是一般的属性配置文件读取
学习时间长了,有些东西可能会遗忘,所以大概整理下,方便大家观看,以后自己看起来也更加方便,如果那里错误,请联系指出,谢谢.大概分为三个
一、队列简单介绍
队列是一种常用的数据结构之一,与之前的栈类似,不过队列是“先进先出”。队列有队头(front)和队尾(rear),数据从队尾
有这样一个问题,有N个人围成一圈做游戏,编号为1->2->3->...->1,让第m个人开始报数,报到底k个数的那个人出队,出队的下一个人继续报数,














 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









