






1、关于字符集的几个相关概念
(1)字符Character,人类语言中最小的表意(表达意思的)符号
(2)字符集(合)CharSet 一组字符就可以定义一个字符集合,通常包括一个国家、民族使用的字符
ASCII字符集合、扩展ASCII字符集合、拉丁语系、GB2312 BIG5 Unicode字符集合
(3)字符编码 给字符集合中的字符指定一个数字来标识
(4)字符集 字符集合+编码=字符集
(5)字符序 Collation 定义了字符集中字符的排序规则(是否区分 大小写),有了字符序,就有了排序标准。一个字符集可以 有多个字符序,有的字符序可能区分大小写,有的字符序可能不区分大小写。
字符集合 可以有多种编码方式 多个字符集
一个字符集 可以有多个排序规则 多个字符序
字符序 Collation中的以_ci结尾代表大小写不敏感,应该是case insensitive,以_cs结尾表示大小写敏感,以_bin按编码值进行比较
2、常见的字符集
ASCII字符集
扩展ASCII字符集 latin1 8位二进制,包括ASCII字符集中的全部字符
GB2312 BIG5 GBK 16位二进制
Unicode字符集 全球语言 16位二进制
扩展ASCII字符集,例如:latin1、latin2
Unicode字符集合 Unicode编码 一个字符两个字节
Unicode字符集合 UTF-8编码 一个英文字符一个字节,一个中文字符使用3个字节
UTF-8是一种变长字节编码方式。对于某一字符的UTF-8编码,如果只有一个字节则其最高二进制为0;如果是多字节,其第一个字节从高位开始,连续的二进制为1的个数决定了其编码的倍数,其余字节均以10开头。UTF-8最多可用到6个字节。
如下:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
编码的本质就是用一个数值来表示一个字符
如何获取一个汉字在UTF-8编码中码值呢?
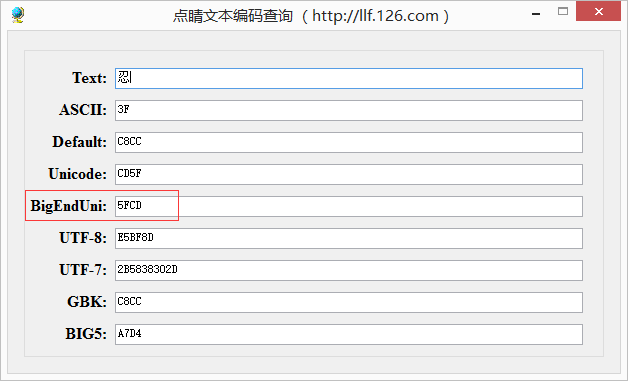
例如一个“忍”字,它对应的UTF-8编码是E5BF8D
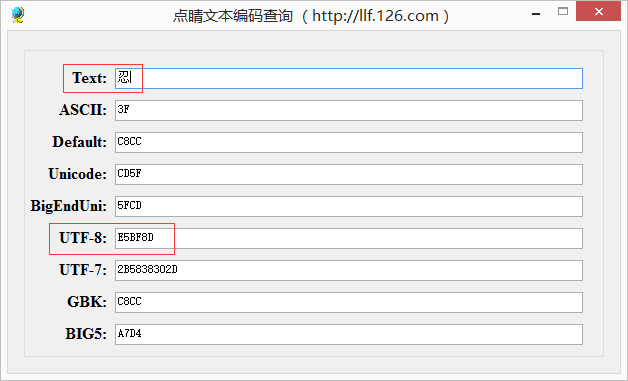
将E5BF8D转换为二进制111001011011111110001101
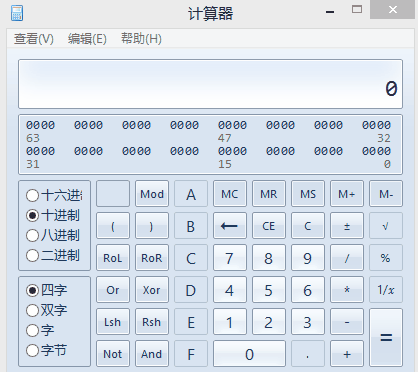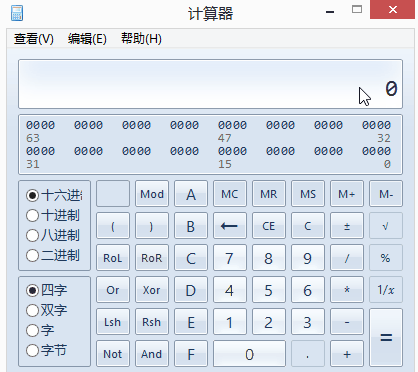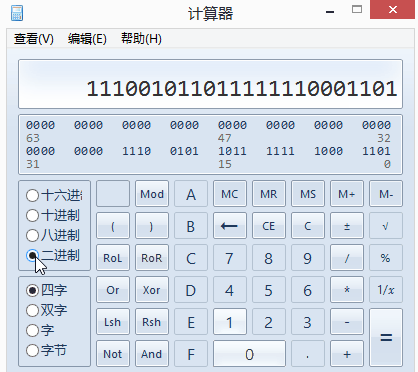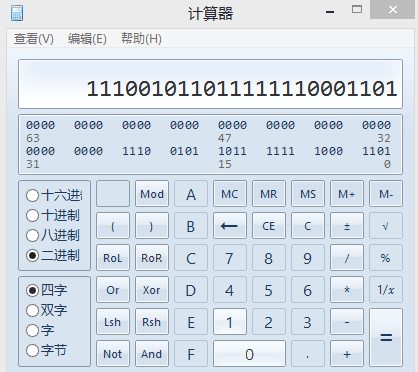
我们知识中文在UTF-8中占用3个字节,因此它的模板是
1110xxxx 10xxxxxx 10xxxxxx

因此,“忍”字对应的UTF-8码值为0101 1111 1100 1101,这16个二进制,恰好是两个字节
再将这16个二进制数转换为16进制数,即5FCD。
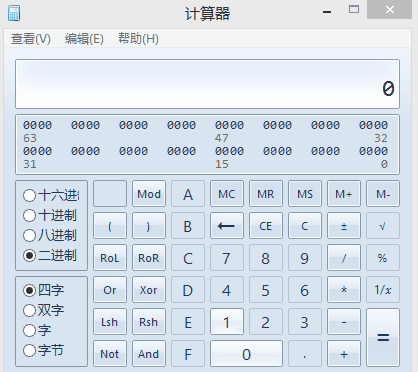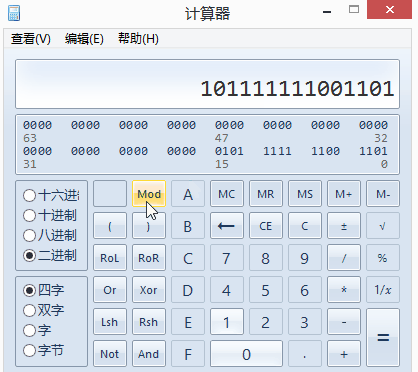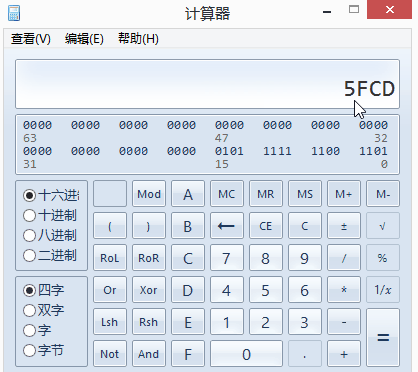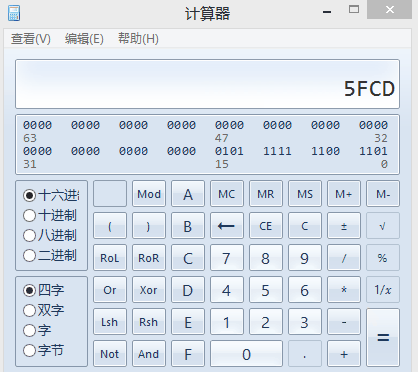
再次查看编码查询工具,发现BigEndUni的值正好是“5FCD”
同样的字符,使用的编码方式不同,占用的字节数也不相同
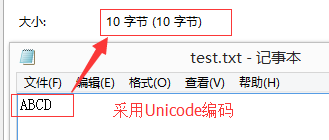
(1)Unicode编码存储英文。
打开记事本ABCD占用10个字节,“ABCD”一共4个字符,每个字符采用Unicode编码占用2个字节,共8个字节,再加上结束字符(EOF)2个字节,共10个字节。
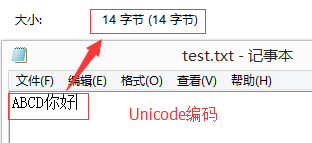
(2)Unicode编码存储中文
记事本中输入“ABCD你好”,一共6个字符,共占12字节,再加上结束字符(EOF)2个字节,共14字节。
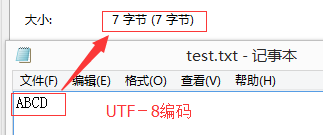
(3)UTF-8编码存储英文
记事本中输入“ABCD”,共4个字符,每个英文字符占1个字节,共4个字节,再加上结束字符(EOF)3个字节,共7个字节。
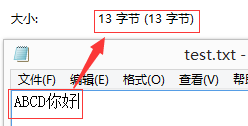
(4)UTF-8编码存储中文
记事本中输入“ABCD你好”,4个英文字符,每个英文字符占1个字节,共4个字节,2个中文字符,每个中文字符占3个字节,共6个字节,再加上结束符(EOF)3个字节,共13个字节。
在控制台查看可接受的字符集
使用chcp [nnn]
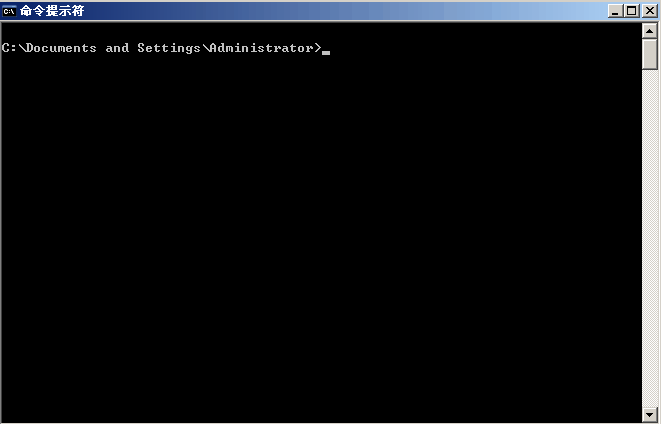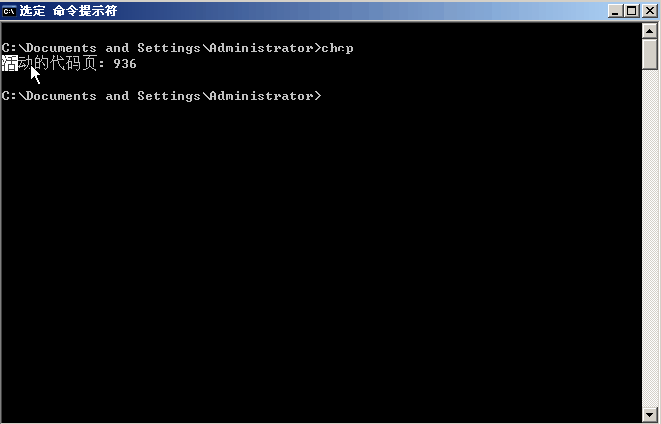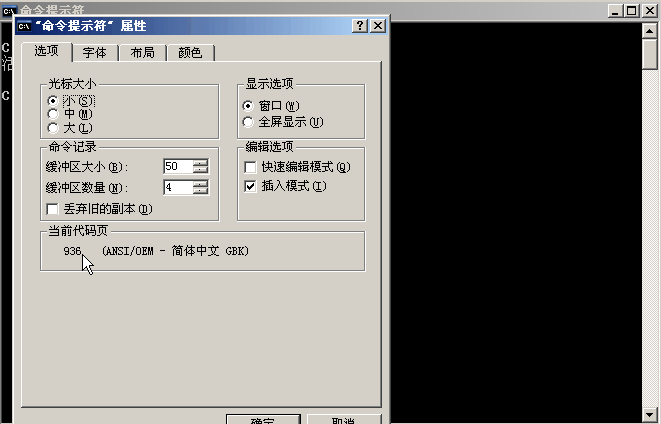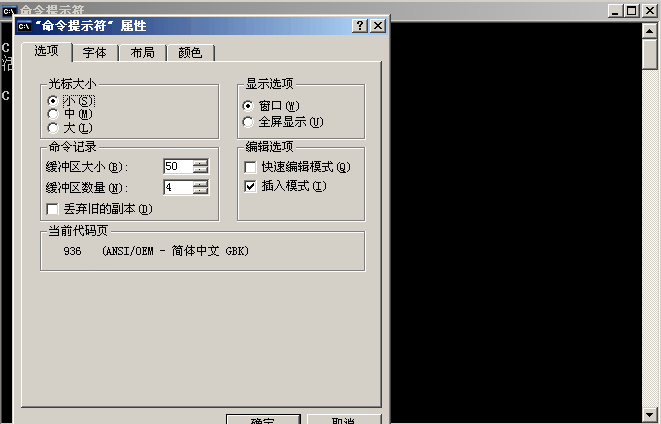 显示活动控制台代码页数量,或更改该控制台的活动控制台代码页。如果在没有参数的情况下使用,则 chcp 显示活动控制台代码页的数量。
显示活动控制台代码页数量,或更改该控制台的活动控制台代码页。如果在没有参数的情况下使用,则 chcp 显示活动控制台代码页的数量。
语法
chcp [nnn]
参数
指定代码页。下表列出了所有支持的代码页及其国家(地区)或者语言:
代码页 国家(地区)或语言
437 美国
932 日文(Shift-JIS)
936 中国 - 简体中文(GB2312)
949 韩文
950 繁体中文(Big5)
说明windows默认的字符集为 GBK
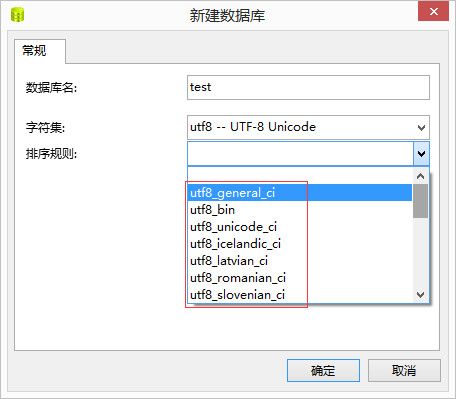
3、MySQL中的字符集
3.1、查看MySQL支持的所有字符集show character set;
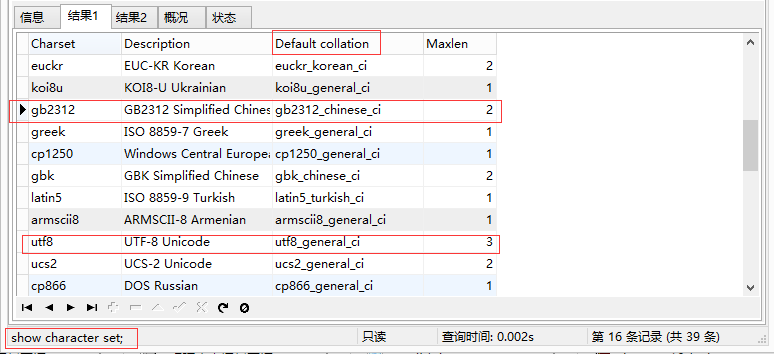
3.2、MySQL中字符集的使用策略:数据库级别、表级别、列级别
创建数据库的时候,如果不指定数据库的字符集,就会使用服务器的默认字符集
创建表的时候,如果不指定表的字符集,就会使用数据库字符集
创建列的时候,如果不指定字符集,默认使用表的字符集
3.3、查看当前使用的字符集show variables like 'character_set_%';
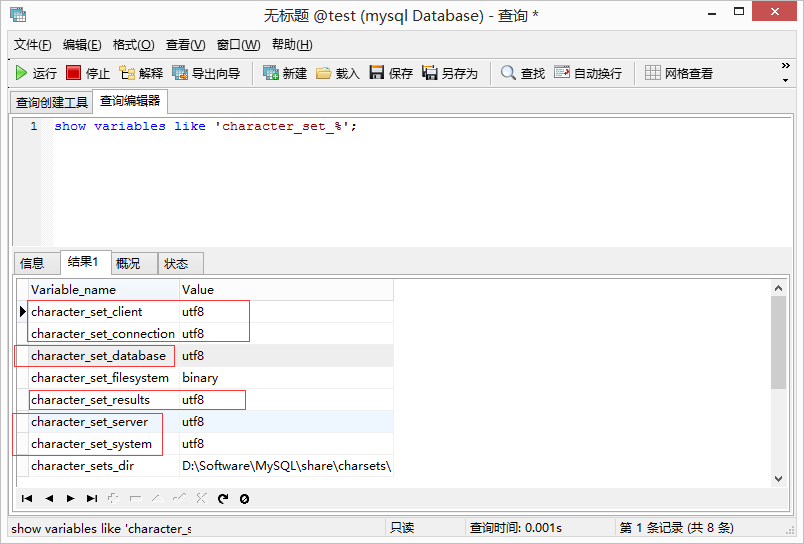
character_set_system 系统级别的字符集
character_set_server 服务器级别使用的字符集
character_set_database 数据库级别的字符集(每个数据库可能有自己的字符集)
character_set_system,是server用来存储identifier(例如:数据库的名字、表的名字、列的名字)的字符集,总是utf8。

character_set_server,是server的默认字符编码。【猜想:character_set_system是用来存储identifier(标识符,例如:数据库名、表名、列名可以使用中文),而character_set_server是用来指示content(存储内容)使用的字符编码】

chracter_set_database,如果当前没有选中数据库,则使用character_set_server的值;如果选定了某个数据库,则会根据该数据库相应的存储内容的字符集。
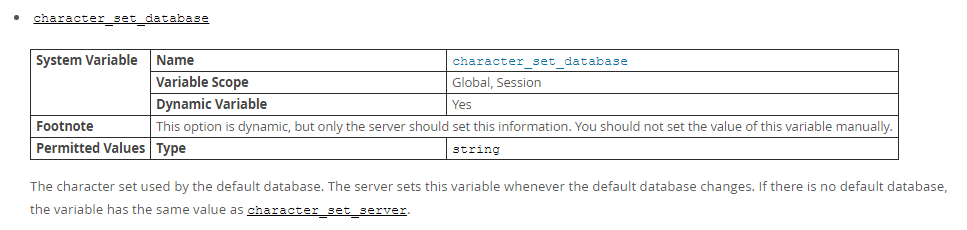
后面的内容,不知道该如何整理了,可能自己还不太清楚吧。。。
character_set_client
character_set_connection
character_set_results
更改MySQL默认字符集
create database schooldb
set names latin1
set names utf8
字符集兼容性















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









