






使用聚合函数进行查询统计
1、常用的聚合函数
| 常用函数 | 功能 |
|---|---|
| sum( distinct | all | * ) | 计算某列值的总和 |
| count( distinct | all | 列名 ) | 计算某列值的个数 |
| avg( distinct | all | 列名 ) | 计算某列值的平均值 |
| max( distinct | all | 列名 ) | 计算某列值的最大值 |
| min( distinct | all | 列名 ) | 计算某列值的最小值 |
| variance / stddev( distinct | all | 列名 ) | 计算特定的表达式中所有值的方差/标准差 |
说明:
1、distinct 表示在计算过程中去列中的重复值,如果不指定distinct 或者指定 all ,则计算所有列值。
2、count(*)是计算所有记录的数量,也包括空值的所在行。count(列名)只计算该列的数量,不计该列的空值。同样 avg 、max 、min和sum 函数后跟 列名 也只计算该列的数量,不计该列的空值。a、求学号为 201925080100 的总分、平均值。
mysql> select sum(course_report) , avg(course_report) from achievement group by stu_num having stu_num='201925080100';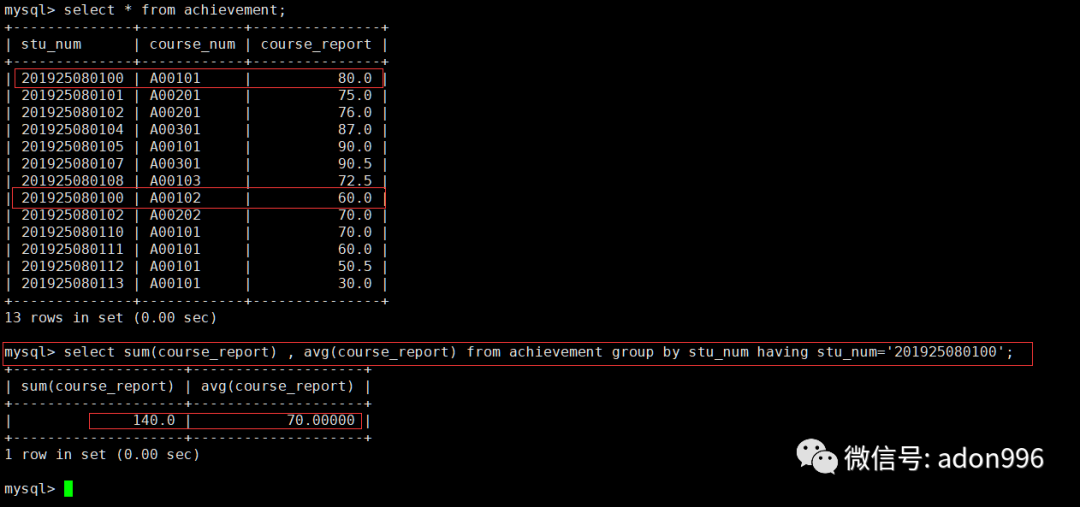
b、求课程A00101的最高分、最低分。
mysql> select max(course_report),min(course_report) from achievement group by course_num having course_num='A00101';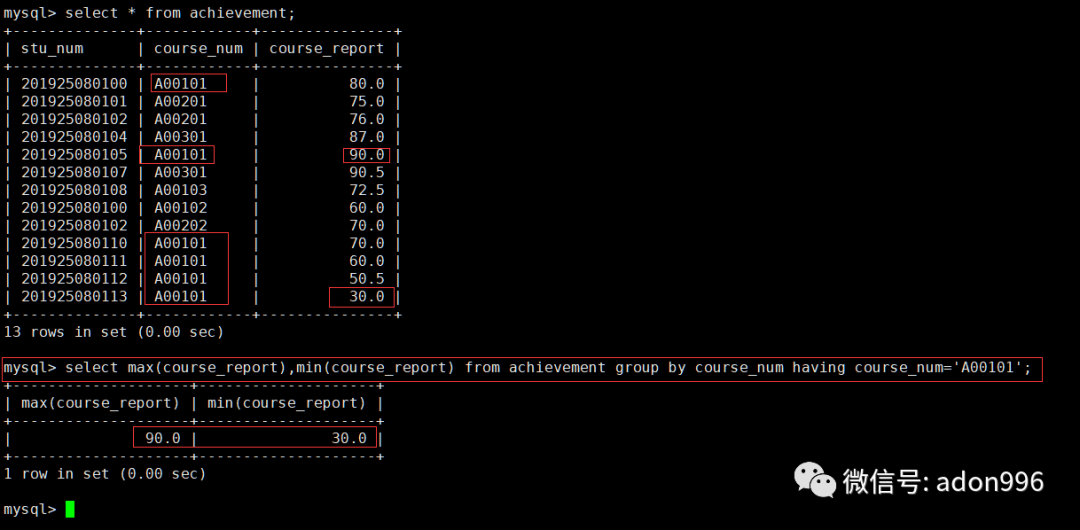
c、求各个课程选修的人数。
mysql> select course_num,count(*) as 选修人数 from achievement group by course_num;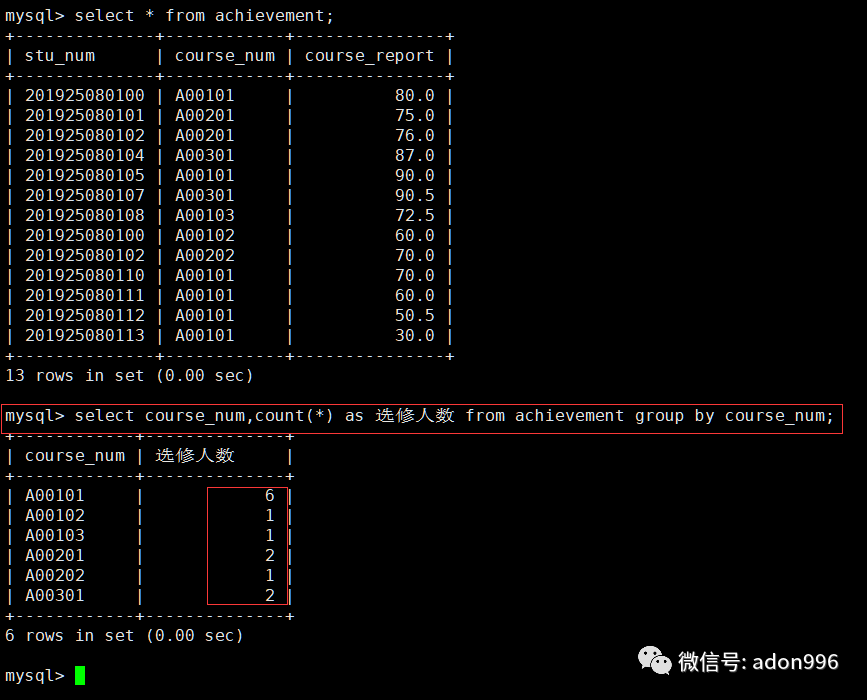
联合查询
联合查询是指将多个 select 语句返回的结果通过 union 组合到一个结果集中。参与查询的 select 语句中的数合列的顺序必须相同,数据类型也要必须兼容。
1、联合查询
联合查询的语法为:
select ... union [all | distinct] select ...[union[all | distinct] select ...]
all 是指查询结果包括所有的行,如果不使用 all ,系统默认自动删除重复行。查询结果得列标题是第一个查询语句中的列标题。
order by 和 limit 子句只能在整个语句最后指定,且使用第一个查询语句中的列名、列标题或序列号,同时还应对单个的 select 语句加圆括号。排序和限制行数对最终结果起作用。a、联合查询 学号为 ‘201925080100’与 ‘201925080112’ 学生的信息。
mysql> select stu_num as 学号,stu_name as 姓名,stu_sex as 性别 from students where stu_num='201925080100' -> union select stu_num,stu_name,stu_sex from students where stu_num='201925080112';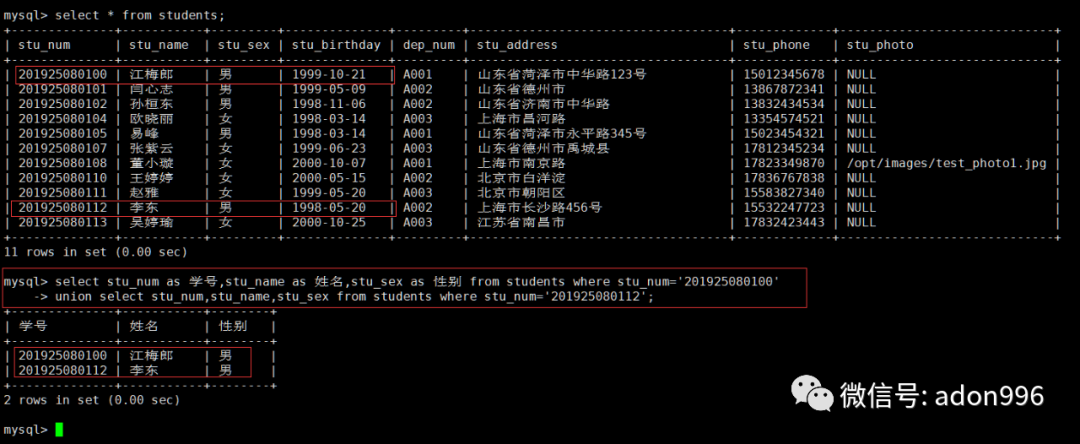
b、联合查询院系编号为 ‘A001’ 与 ‘A002’ 的院系学生成绩,查找在两系成绩中排名前5名的学生。
mysql> select students.stu_num,dep_num,course_report from students,achievement -> where students.stu_num=achievement.stu_num and dep_num='A001' -> union -> select students.stu_num,dep_num,course_report from students,achievement -> where students.stu_num=achievement.stu_num and dep_num='A002' -> order by course_report desc limit 5;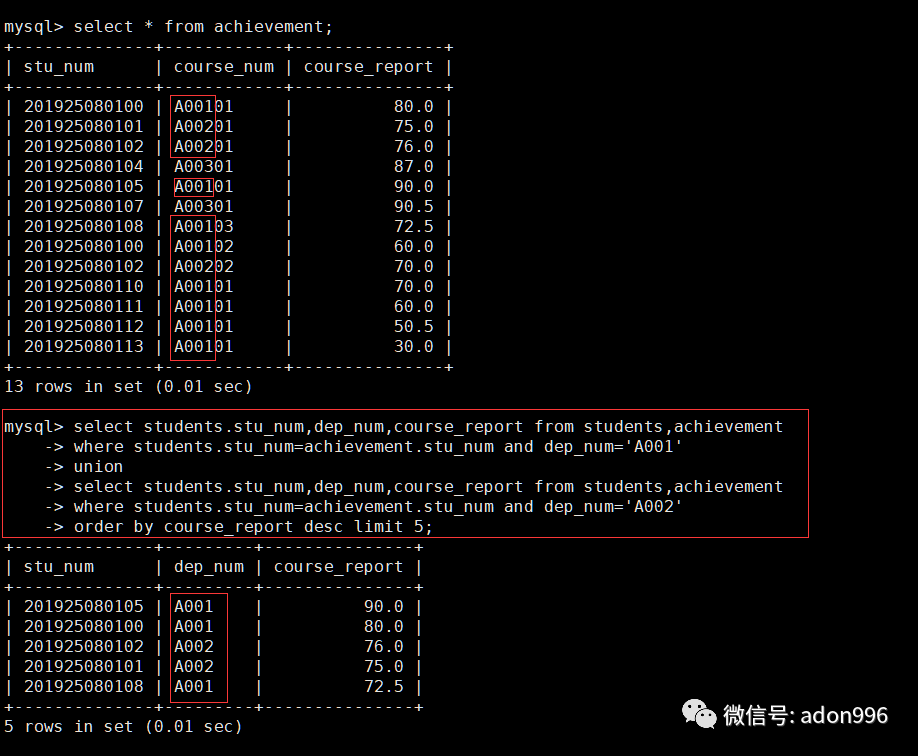
讨论:1、order by 是对最终结果进行一个排序,limit 5 查询的是按两个院系的成绩合并后,排名在前5 位的学生信息。并不是每个系的前5名。















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









