





在新能源行业中,多采用数据中台来管理业务数据,使用时序数据库(Time Series Database)来管理时序数据,他们的数据都来自数采网关。以风力发电场景为例,需要实时计算风机的各种 KPI 指标,往往通过数据中台的定时任务来完成这些计算。目前,现有的方案存在几个方面的问题:首先,由于是定时任务,KPI 计算的实时性无法保证,特别是在 KPI 的计算需要多个步骤才能完成的情况下,延迟可能会长达几分钟甚至十几分钟。其次,由于数据中台基于 Hadoop 生态,架构臃肿、组件繁多,需要大量服务器,不仅导致业务应用开发成本高昂、同时也导致系统的运维成本居高不下。
因此,为了提高业务响应速度和实时性,客户希望将 KPI 计算任务卸载到 TDengine。希望借助 TDengine 的流计算功能,大幅度提升 KPI 计算的效率和实时性。采用 TDengine 流计算后,简单的 SQL 即可实现 KPI 计算需求,将业务响应时间(流计算的开发时长)从数周缩短一两天甚至数小时,极大地提高了业务响应能力,显著地提高了企业的竞争力。
此外,引入 TDengine 流计算后,KPI 计算的延迟从几分钟甚至十几分钟缩短到秒级甚至毫秒级,大幅度地提升了实时性。从基于 Hadoop 生态的批任务到基于 SQL 的流式计算,不仅降低了开发复杂度和开发测试成本,还减少了数据中台的服务器集群规模,显著降低了成本和运维复杂度,实现了降本增效的目标。
本文将从“实时计算 95 个风机的平均风速”到“复杂 KPI 的流计算”两大场景进行阐述,从代码层面为你解读 TDengine 流计算的强大功能,助力新能源行业的应用。
实时计算 95 个风机的平均风速
为尽可能还原真实业务场景,我们模拟 95 个风机,1 秒钟上报 1 条数据的场景。
创建数据库
– 创建风力发电数据库
create database wind;
创建超级表
– 创建风机的超级表
create table wind_turbine (ts timestamp, wind_speed double, conn_state bool)
tags (site_id varchar(20));
创建子表
– 创建遥测风机子表(YC_FJ_001)
create table YC_FJ_001 using wind_turbine tags (‘YC_FJ_001’);
create table YC_FJ_095 using wind_turbine tags (‘YC_FJ_095’);
注意:流计算会考虑过期数据以及乱序数据,如果原来的表中已经有数据,新写入的数据时间若早于已有数据,有可能因为数据过期被丢弃。如果数据被丢弃,有可能无法生成新的流计算结果。
模拟 95 个风机,1 秒钟上报 1 条数据的场景:
taosBenchmark -f insert_1s1row.json
其中,insert_1s1row.json是taosBenchmark的配置文件,配置方法请参考:taosBenchmark插入场景 JSON 配置文件示例 。其中关键参数如下:
“non_stop_mode”: “yes”, # 持续写入不停止
“interlace_rows”: 1, # 交叉向每个子表写入
“insert_interval”: 1000, # 保持1000毫秒插入一条
创建流计算
– 创建流计算,95个风机的平均风速(连接状态断开的风机不参与计算)
create stream stream_avg_speed trigger at_once into avg_speed_95
as select _wstart as time, avg(wind_speed) as avg_speed from wind_turbine
where conn_state = true
interval(1s);
查询流计算结果
– 查询流计算最新结果
select * from avg_speed_95 order by time desc limit 5;
taos> select * from avg_speed_95 order by time desc limit 5;
time | avg_speed | group_id |
==============================================================================
2024-06-26 01:22:23.000 | 26.166599999999992 | 0 |
2024-06-26 01:22:22.000 | 22.864500000000000 | 0 |
2024-06-26 01:22:21.000 | 1.101700000000000 | 0 |
2024-06-26 01:22:20.000 | 29.485700000000001 | 0 |
2024-06-26 01:22:19.000 | 24.481799999999996 | 0 |
Query OK, 5 row(s) in set (0.009711s)
taos> select * from avg_speed_95 order by time desc limit 5;
time | avg_speed | group_id |
==============================================================================
2024-06-26 01:22:50.000 | 31.460899999999992 | 0 |
2024-06-26 01:22:49.000 | 8.252200000000000 | 0 |
2024-06-26 01:22:48.000 | 19.568899999999996 | 0 |
2024-06-26 01:22:47.000 | 5.945700000000001 | 0 |
2024-06-26 01:22:46.000 | 29.533400000000007 | 0 |
Query OK, 5 row(s) in set (0.006516s)
复杂流计算场景
该场景的 KPI 计算规则复杂,并且数据模拟的难度非常大,因此,本演示只展示复杂 KPI 计算逻辑,不展示流计算实时计算的过程。
业务需求
该 KPI 的计算公式,如下:
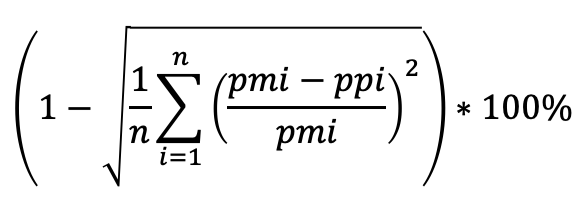
其中:
- n 为该日的样本总数,15 分钟一个点记作 i;pmi 为 i 时刻的实际功率;ppi 为 i 时刻的短期预测功率;
- 若 pmi = 0,则 i 时刻的预测值直接 = 0;
- 若 ppi > 2 * pmi,则 i 时刻的结果直接 = 1;
- 否则,预测值按照上面的公式计算。
创建超级表
– 创建超级表
create table power_predict (ts timestamp, ppi double, pmi double)
tags (site_id varchar(20));
– 发电预测表
create table YC_FJ001_PREDICT using power_predict
tags (“YC_FJ001_PREDICT”);
创建一阶段流计算
– KPI计算规则:
– 1. 当 pmi == 0时, ppi_percent = 0.0
– 2. 当 ppi > 2pmi 时, ppi_percent = 1.0
– 3. 其他情况, ppi_percent = 1-sqrt(avg(pow(((pmi-ppi)/pmi), 2)))
create stream stream_ppi_percent_1 trigger at_once into st_ppi_percent_1 as
SELECT ts, ppi, pmi,
case when pmi <= 0.0001 then 0.0
when ppi > 2pmi then 1.0
else pow(((pmi-ppi)/pmi), 2) end as ppi_percent
from power_predict
partition by tbname; – 这个必不可少
创建二阶段流计算
create stream stream_ppi_percent trigger at_once into st_ppi_percent as
select _wstart as ts, 1-sqrt(avg(ppi_percent)) from
st_ppi_percent_1
interval(1d);
向源表写入数据
insert into YC_FJ001_PREDICT values
(‘2024-06-25 12:00:00’, 5500.00, 0.00)
(‘2024-06-25 13:00:00’, 5000, 5500.00)
(‘2024-06-25 14:00:00’, 15500, 5500.00)
(‘2024-06-26 12:00:00’, 5500.00, 5000.00)
(‘2024-06-26 13:00:00’, 5000, 0.00)
(‘2024-06-25 14:00:00’, 15500, 5500.00);
查询计算结果
– 查询流计算结果
taos> select * from st_ppi_percent_1 order by ts desc limit 20;
ts | ppi | pmi | ppi_percent | group_id |
======================================================================================================================================
2024-06-27 14:00:00.000 | 15500.000000000000000 | 5500.000000000000000 | 1.000000000000000 | 7041101957555052029 |
2024-06-27 13:00:00.000 | 5000.000000000000000 | 0.000000000000000 | 0.000000000000000 | 7041101957555052029 |
2024-06-27 12:00:00.000 | 5500.000000000000000 | 5000.000000000000000 | 0.010000000000000 | 7041101957555052029 |
2024-06-26 14:00:00.000 | 15500.000000000000000 | 5500.000000000000000 | 1.000000000000000 | 7041101957555052029 |
2024-06-26 13:00:00.000 | 5000.000000000000000 | 5500.000000000000000 | 0.008264462809917 | 7041101957555052029 |
2024-06-26 12:00:00.000 | 5500.000000000000000 | 0.000000000000000 | 0.000000000000000 | 7041101957555052029 |
Query OK, 6 row(s) in set (0.007745s)
taos> select * from st_ppi_percent order by ts desc limit 20;
ts | 1-sqrt(avg(ppi_percent)) | group_id |
==============================================================================
2024-06-27 00:00:00.000 | 0.419770160482360 | 0 |
2024-06-26 00:00:00.000 | 0.420268894857303 | 0 |
Query OK, 2 row(s) in set (0.007535s)
写在最后
通过本文的介绍和示例,我们可以清晰地看到 TDengine 在处理大规模时序数据和实时流计算方面的强大功能。它不仅显著提高了业务响应速度和实时性,还大幅降低了系统的开发和运维成本。在新能源领域 KPI 计算的实际应用中,TDengine 成功地解决了定时任务的延迟问题,实现了秒级甚至毫秒级的实时计算。
未来,随着业务需求的不断增长和复杂性提升,TDengine 的流计算能力将为更多场景提供高效、可靠的解决方案。希望本文的分析和实操示例能为广大用户带来启发和帮助,让大家在实际项目中充分发挥 TDengine 的优势,实现更高效的业务管理和数据处理。
关于 TDengine 流计算的更详细信息可查阅官方文档: https://docs.taosdata.com/develop/stream/















 3213
3213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









