






1、列表,字典,集合解析
from random import randint
#列表解析,选出大于0的元素
data=[randint(-10,10)for i in range(10)]
result1=filter(lambda x:x>=0 ,data)
result2=[x for x in data if x>=0]#最快
for x in data:#最慢
if x>=0:
print(x)
#字典解析,value大于80
d = {x:randint(60,100) for x in (1,20)}#构造字典
result3={k:v for k,v in d.items() if v>80}
print(result3)
#集合解析
#集合中科院被3整除的元素
s=set(data) result4={x for x in s if x%3 ==0}
2、为元组命名
#可命名元组
from collections import namedtuple
#第一种方式
student = ('BOB',16,'male','810833355@qq.com')
name,age,sex,email = range(4)
print(student[name])
from collections import namedtuple
#第一种方式
# student = ('BOB',16,'male','810833355@qq.com')
# name,age,sex,email = range(4)
# print(student[name])
student= namedtuple('student',['name','age','sex','email'])
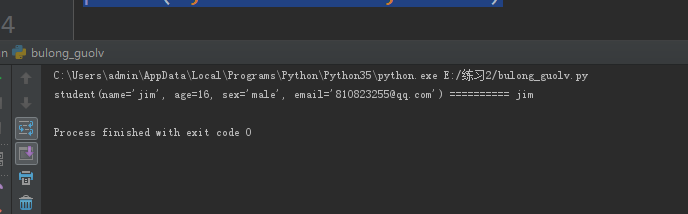
s=student('jim',16,'male','810823255@qq.com')
print(s,'==========',s.name)
执行结果如图
3、统计序列中元素出现频度
from random import randint
data = [randint(1,20) for x in range(50)]#随机序列,计算每个元素出现的次数
c=dict.fromkeys(data,0)#0是初始值,将;将列表中的元素作为字典的key
for x in data:
c[x] +=1
from random import randint
data = [randint(1,20) for x in range(50)]#随机序列,计算每个元素出现的次数
from collections import Counter
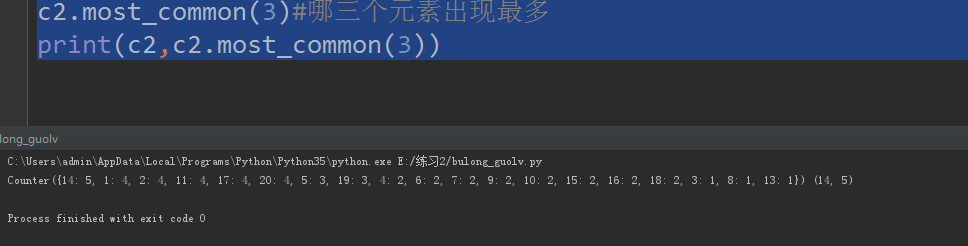
c2 = Counter(data)
c2.most_common(3)#哪三个元素出现最多
print(c2,c2.most_common(3))
结果如图
词频统计
import re
from collections import Counter
txt = open('a.txt').read()
c1=re.split('\w',txt)#对非字母进行分割,然后传进Counter
result = Counter(c1)#将列表传进去
res = result.most_common(3)#出现次数最多的三个单词
4、根据字典中值的大小,对字典中的项进行排序
from random import randint
d1={x: randint(60,100) for x in 'abcxyz'}#六个人分别叫abcxyz
#1
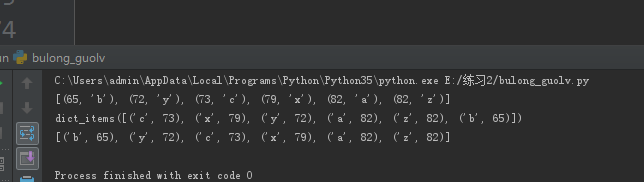
print(sorted(zip(d1.values(),d1.keys())))#元组组成的列表,比较元组的第一个元素
#2
print(sorted(d1.items(),key=lambda x :x[1]))
结果如图
5、如何快速找到多个字典里面的公共键
from random import randint,sample
#sample是取样
#1
sam=sample('abcdef',randint(3,6))#随机选取'abcdef'三到6个样本
s1 ={x:randint(1,4) for x in sample('abcdef',randint(3,6))}
s2={x:randint(1,4) for x in sample('abcdef',randint(3,6))}
s3={x:randint(1,4) for x in sample('abcdef',randint(3,6))}
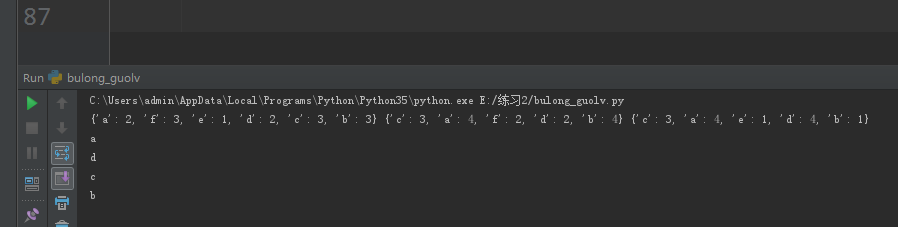
print(s1,s2,s3)
for k in s1:
if k in s2 and k in s3:
print(k)
结果如图
第二种方法
print(s1.keys() & s2.keys() & s3.keys())#python2是viewkeys,这里取交集
from functools import reduce
print(reduce(lambda a,b:a & b,map(dict.keys,[s1,s2,s3])))#如果键多可以这样,python2是viewkeys
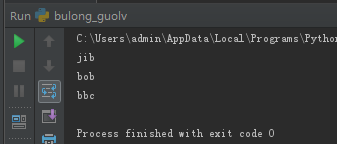
6,、如何让字典有序
from collections import OrderedDict
d= OrderedDict()
d['jib']=(1,35)
d['bob']=(2,5)
d['bbc']=(3,5)
for i in d:
print(i)
结果如图
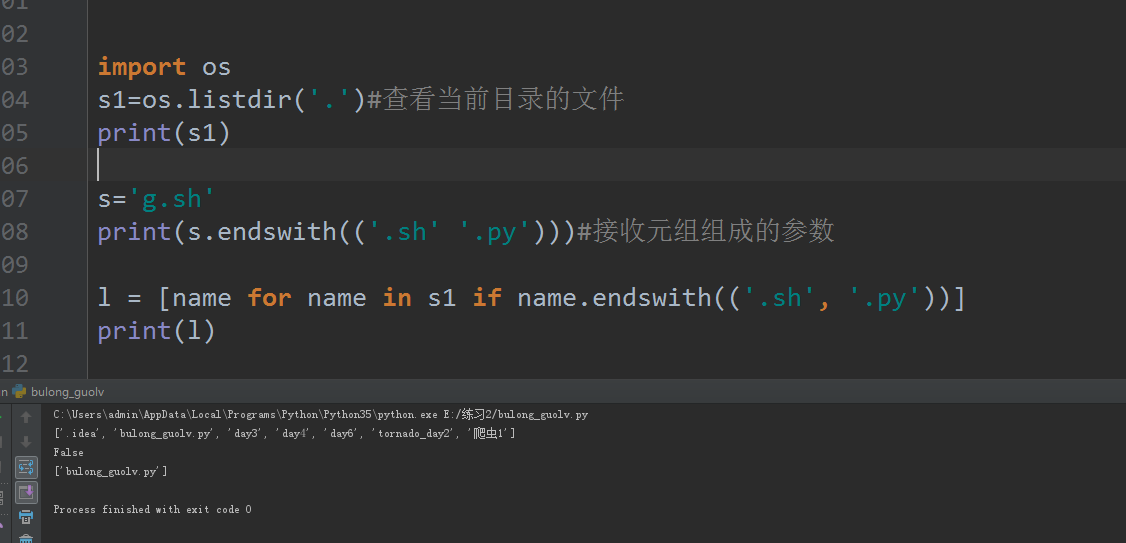
7、拆分含有多个分隔符的字符串
s='ab;cd|efgh|hi,jkl|topq;rst,vww\atex'
t=[]
res = s.split(';')
map(lambda x: t.extend(x.split('|')),res)
print(t)
第二种方法
import re
s='ab;cd|efgh|hi,jkl|topq;rst,vww\atex'
print(re.split(r'[,;\|]',s))
结果如图

8、判断字符串开头
9、正则调整文本格式
import re
#1
l=['2016-05-23','2016-06-11','2016-07-12']
l1='2016-05-23'
print(re.sub('(\d{4})-(\d{2})-(\d{2})',r'\2/\3/\1',l1))
结果如图
第二种方法
import re
#1
l=['2016-05-23','2016-06-11','2016-07-12']
l1='2016-05-23'
print(re.sub('(?P\d{4})-(?P\d{2})-(?P\d{2})',r'\g/\g/\g',l1))
10、字符串拼接
第一种方法
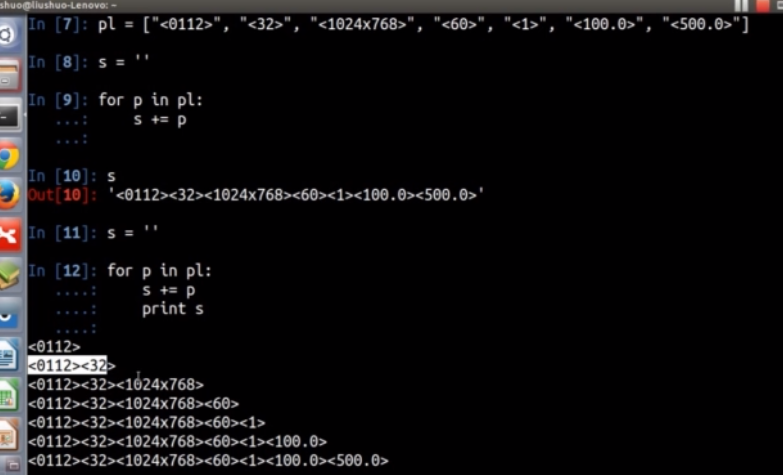
不过这种方法浪费内存,下面是第二种方法,用join
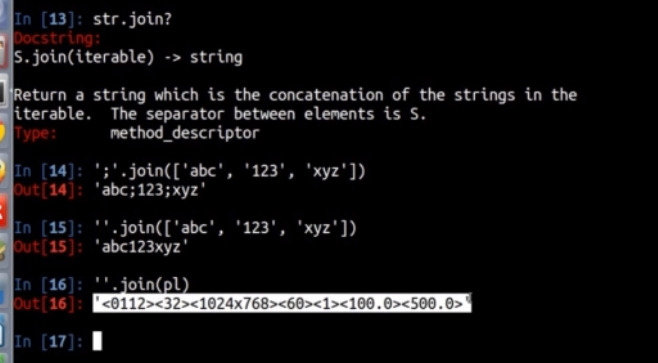

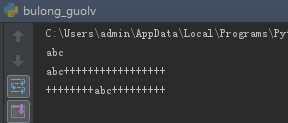
11、调节字符串居中,左右对齐
s= 'abc'
print(s.ljust(20))
print(s.ljust(20,'+'))
print(s.center(20,'+'))
结果如图
ling另外一种方法如图
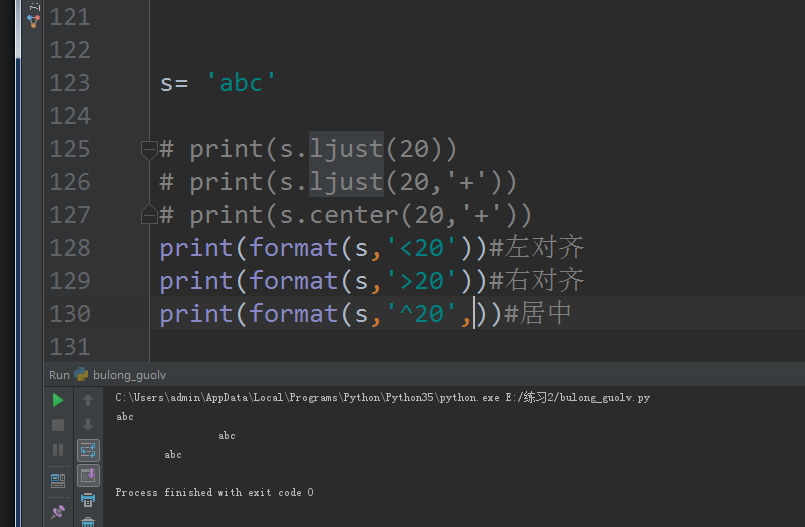
12、去掉不需要的字符串
去除空格
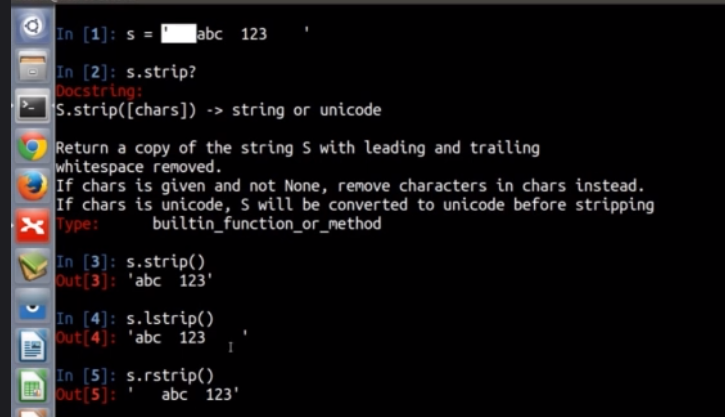
去除指定字符
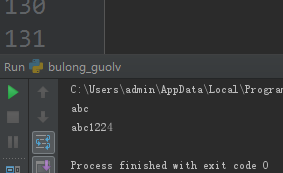
s= 'abc__++++'
print(s.strip('_+'))
s1 = 'abc:1224'
print(s1[:3]+s1[4:])
结果如图
s= '\tadhi\sfds\sdfds\sdfds\gf\gs\ggg'
print(re.sub('[\t\g\f\d]','',s))
来源:https://www.cnblogs.com/xiaobeibei26/p/6727074.html














 3065
3065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









