






1.概述
学习率是位于损失函数梯度前,更新网络权重的超参数。学习率越低,权重更新速度越慢,损失函数变化速度越慢。虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛,特别是被困在高原区域的情况下。
梯度下降:new_weight=existing_weight-learning_rate*gradient
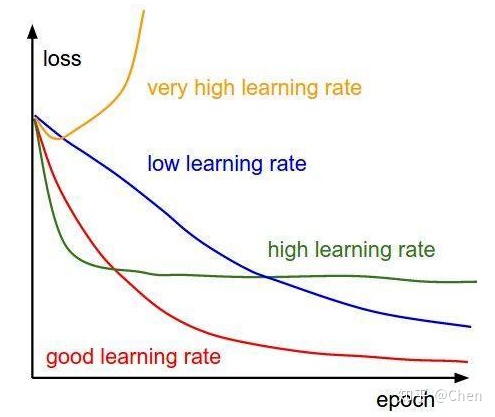
学习率设置中初始学习率与学习率衰减策略是非常重要的两方面。下图展示了不同大小的学习率下模型收敛情况的可能性。
2.初始学习率的选择
初始学习率过大则导致模型不收敛,过小则导致模型收敛特别慢或者无法学习,在不考虑具体的优化方法的差异的情况下,怎样确定最佳的初始学习率呢?
通常采用最简单的搜索法,即从小到大开始训练模型,然后记录损失的变化,通常会记录到这样的曲线。首先我们设置一个非常小的初始学习率,比如1e-5,然后在每个batch之后都更新网络,同时增加学习率,统计每个batch计算出的loss。最后我们可以描绘出学习的变化曲线和loss的变化曲线,从中就能够发现最好的学习率。最后我们可以描绘出学习的变化曲线和loss的变化曲线,从中就能够发现最好的学习率。
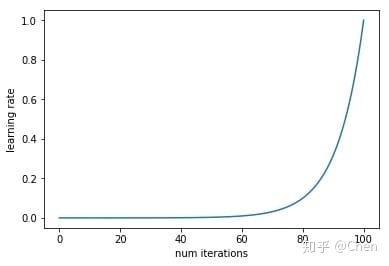
下面就是随着迭代次数的增加,学习率不断增加的曲线,以及不同的学习率对应的loss的曲线。
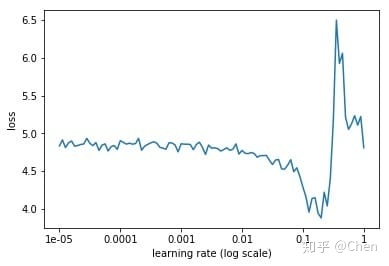
从上面的图片可以看到,随着学习率由小不断变大的过程,网络的loss也会从一个相对大的位置变到一个较小的位置,同时又会增大,这也就对应于我们说的学习率太小,loss下降太慢,学习率太大,loss有可能反而增大的情况。从上面的图中我们就能够找到一个相对合理的初始学习率,0.1。
之所以上面的方法可以work,因为小的学习率对参数更新的影响相对于大的学习率来讲是非常小的,比如第一次迭代的时候学习率是1e-5,参数进行了更新,然后进入第二次迭代,学习率变成了5e-5,参数又进行了更新,那么这一次参数的更新可以看作是在最原始的参数上进行的,而之后的学习率更大,参数的更新幅度相对于前面来讲会更大,所以都可以看作是在原始的参数上进行更新的。正是因为这个原因,学习率设置要从小变到大,而如果学习率设置反过来,从大变到小,那么loss曲线就完全没有意义了。
criterion = torch.nn.CrossEntropyLoss()
net = model_zoo.resnet50(pretrained=True)
net.fc = nn.Linear(2048, 120)
with torch.cuda.device(0):
net = net.cuda()
basic_optim = torch.optim.SGD(net.parameters(), lr=1e-5)
optimizer = ScheduledOptim(basic_optim)
lr_mult = (1 / 1e-5) ** (1 / 100)
lr = []
losses = []
best_loss = 1e9
for data, label in train_data:
with torch.cuda.device(0):
data = Variable(data.cuda())
label = Variable(label.cuda())
# forward
out = net(data)
loss = criterion(out, label)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr.append(optimizer.learning_rate)
losses.append(loss.data[0])
optimizer.set_learning_rate(optimizer.learning_rate * lr_mult)
if loss.data[0] < best_loss:
best_loss = loss.data[0]
if loss.data[0] > 4 * best_loss or optimizer.learning_rate > 1.:
break
plt.figure()
plt.xticks(np.log([1e-5,1e-4,1e-3,1e-2,1e-1,1]),(1e-5,1e-4,1e-3,1e-2,1e-1,1))
plt.xlabel('learning rate')
plt.ylabel('loss')
plt.plot(np.log(lr), losses)
plt.show()
plt.figure()
plt.xlabel('num iterations')
plt.ylabel('learning rate')
plt.plot(lr)3.学习率调整方法
学习率变化方式有两种,一种是预设规则学习率变化法,一种是自适应学习率变换方法。第一种方法常见的策略包括StepLR、MultiStepLR;第二种方法常见的策略包括ExponentialLR、Cosine Annealing LR、Reduce LR On Pleateau和Lambda LR。
PyTorch中提供了6种基于epoch训练次数进行学习率调整的方法,分别如下:
StepLR
MultiStepLR
ExponentialLR
CosineAnnealingLR
ReduceLRonPlateau
LambdaLR它们是在迭代中修改学习率,这6种方法继承于一个基类_LRScheduler,该类有三个主要属性和两个主要方法。
三个主要属性分别是:
- optimizer:关联的优化器。
- last_epoch:上一个epoch数,该变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整。当为-1时,学习率设为初始值。
- base_lrs:记录初始学习率。
两个主要方法分别是:
- step():更新下一个epoch的学习率。
- get_last_lr():返回上次计算后的学习率。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









