






查询语句:select 字段 from 表名 ;
字段别名:as 给字段或者 表名 一个表名 为了显示方便起见,可以设置字段别名。
select 后面选项 all 代表不去除重复行,distinct 取出结果集中的重复行,查询字段中含有主键,其他字段值相等时,不能算作重复行。
运算符:
逻辑运算符:
逻辑与:and
逻辑或:or
运算符分类:
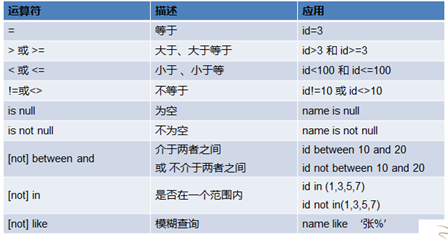
= 在mysql中既可以充当赋值运算符的作用,又可以充当比较运算符作用。
in (x,x,x)
字段取的值可以为多个选项中的一个时,使用in指定可取的选项。
#例 指定字段数据的取值为哪些具体值 a或b或cselect * from tables where id in(1,2,3)
#notin排除数据select * from tables where id not in(1,2,3)
between x and x
#取值为10到20范围之内的任意值,包括10,20
select * from tables where id between 10 and 20;
#取值不为10到20范围之内的任意值,包括10,20
select * from tables where id not between 10 and 20;
is null
null相当于录入一行记录时,特定的字段没有录入数据。null不等于任何值(空字符串,以及null本身)
#直接插字段 = null 是查不到数据的 需要用is null查询select * from tables where id is null;
区分空字符串与null:
空字符串:黑户,没有籍贯信息
null:有可能有,可能没有 ,只是没有录入
like
like,用于实现模糊查询,后面跟对应的匹配条件,一般和统配符结合使用。可以用来做简单的站内查询。
#like 模糊查询 %表示通配符 写在前面表示 匹配以这个开始的,写在后面是以这个结束的 都写是包含这个内容的
#以张开始的select * from tables where name like '%张';
#以张结束的select * from tables where name like '张%';
#包含张的select * from tables where name like '%张%';
通配符:
l % :使用任意多个字符(包括0个)进行匹配
l _: 使用单个字符进行匹配
五子句:
where:
where字句中不能使用别名,可以使用逻辑运算符 and/or
#例
select * from table where id=1;
#id是1 并且name是小明的
select * from table where id=1 and name=‘小明’;
#id是1或者name是小明的
select * from table where id=1 or name=‘小明’;
where的本质是从磁盘返回所有行,逐行进行条件判断。
满足条件,返回true,该行在结果集中显示。否则返回false,不显示。
#特殊情况 每一行条件都会判断都会返回trueselect * from tables where 1;
sql注入:
例如用户提交万能用户名:
#例select * from tables where name =’123’ or 1#最终结果为真,返回所有行
PHP用这个函数进行转义:addslashes();
group by 字句
对一组数据进行统计,计算平均值,最小值,最大值等,需要使用聚合函数。
聚合函数:
聚合函数本质为系统函数。如同now();
avg():一组数的平均值,average
count():计数,有多少行
max():最大值
min():最小值
sum():求和
特点:返回的都是单一确定的值,也就是一行一列。
聚合出一些信息出来:最大,最小,平均值等。
回溯统计:with rollup;
having字句:
对数据表的数据执行group by操作之后,可以聚合出一些数据表中本身不存在的数据,如最大值,最小值等。再按照这些条件对数据进行再次筛选时,无法再使用where条件,必须使用having。
having与where的区别:
where 后面不能跟别名:取数据表中找对应字段
having:可以 跟聚合函数(分组计算出来)
where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据(初步结果集,比较条件可以是聚合函数统计出来的结果)进行再次筛选。
where后面的字段必须是原始表中的字段,不能使用字段别名或者聚合函数;而having字段可以是结果集中的字段(也可以是普通字段,或者字段别名或者聚合函数)
分组只要再检查最大值、最小值等,必然会使用到having子句。
having在不分组的SQL语句中,相当于where。即where不能实现having的全部功能,having可以实现where的功能。
order by:
可以按照升序 asc 降序排序 desc
select 字段列表 from tb where子句 group by 子句 having子句 order by 字段1 DESC| ASC,字段2 DESC | ASC;
limit 子句:
类似与分页 从多少条数据 往后去到少条数据
偏移量:就是从多少条开始取数据
select 字段列表 from tb where子句 group by子句 having子句 order by子句 limit [ 偏移量= 0],每页显示的行数;















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









