




 本文介绍了如何使用Python的uiautomation库爬取Wind金融终端中的研报数据。通过分析Wind页面结构,选定Wind窗口,获取研报列表并模拟点击进入详情页,最后抓取所需信息并退出详情页。这种方法适用于Windows程序自动化数据抓取。
本文介绍了如何使用Python的uiautomation库爬取Wind金融终端中的研报数据。通过分析Wind页面结构,选定Wind窗口,获取研报列表并模拟点击进入详情页,最后抓取所需信息并退出详情页。这种方法适用于Windows程序自动化数据抓取。
1.前言
Wind(万德)金融终端是我校同学常用的商业软件,其中提供了大量的金融实施数据,丰富而翔实。Wind几乎是我见过的付费商业软件中用户体验最好的之一,然而正是由于其昂贵的价格,使得其保密性非常高,不容易获取其中的数据。Wind官方为我们提供了api接口,但这些接口还不能满足我们更加个性化的数据要求。
同时Wind作为PC客户端程序,抓取其中的数据并不能像在浏览器中那样方便。对于浏览器中的数据,可以用大家非常熟悉的传统爬虫来解决。然而对于这种PC程序中的数据,抓取就需要其他的办法。
如需按本文操作进行实验,建议准备一块额外的外接屏幕。
2.问题描述
这里我们的目标问题是爬取wind终端中的研报数据。wind账号异常昂贵,这里我们只好想象自己真的有一个Wind账号。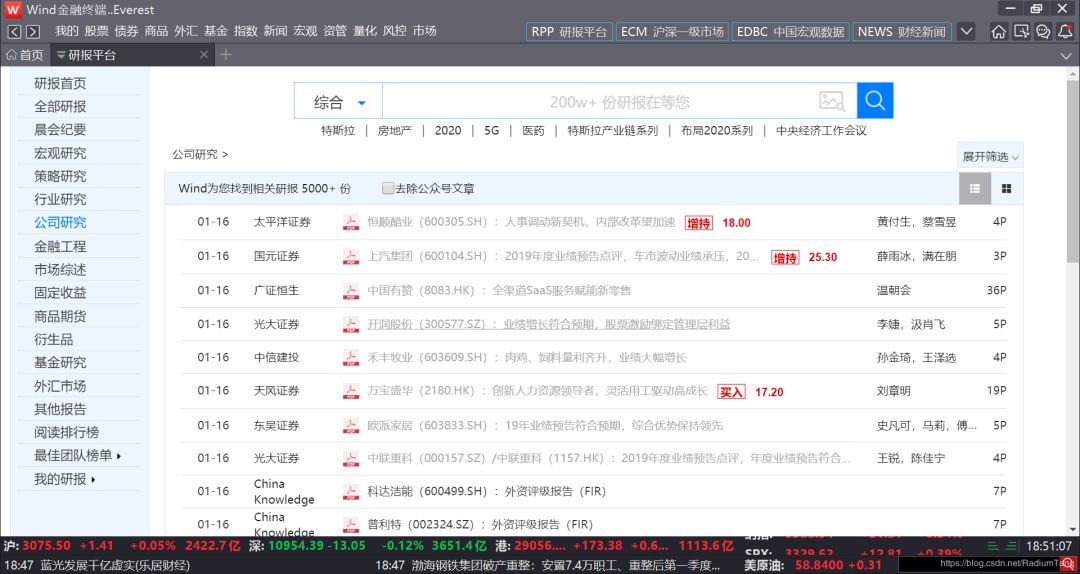
我们的目标主要是爬取每条研报中的一些具体数据,如研报撰稿人、发布时间,180天内被评测次数和EPS值(见下图红框),并写入csv文件。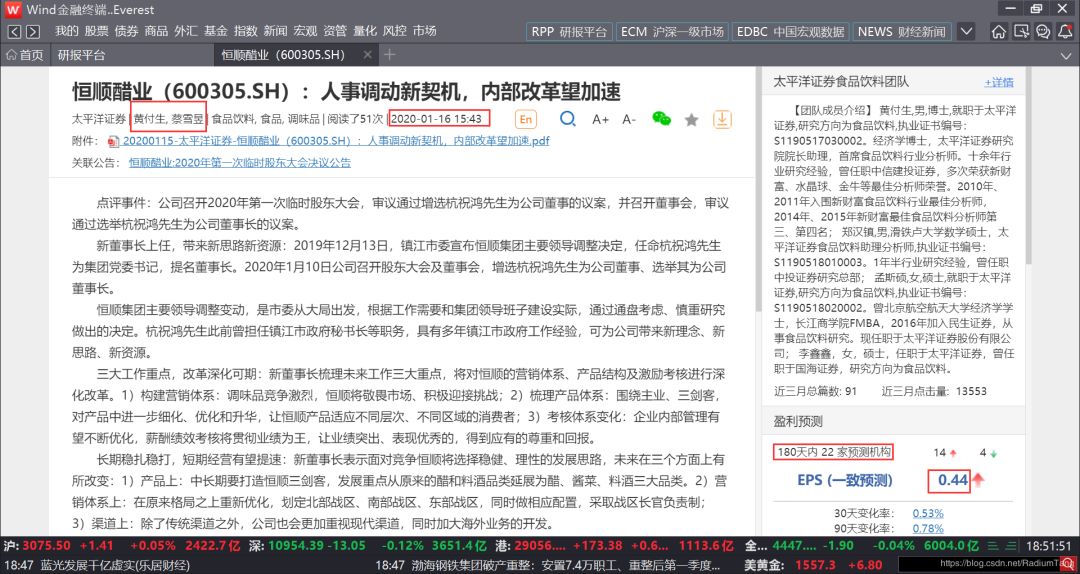
3.分析页面
众所周知,浏览器中的数据是以HTML的形式展现的,通过爬虫,辅之以正则表达式、xpath等工具可以轻松拿到我们需要的数据。实际上,很多Windows程序中也有类似HTML页面的结构,只不过大部分Windows程序是不提供检查功能的。我们可以使用Windows SDK提供的inspe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









