






1、application/x-www-form-urlencoded
它是一种编码类型。当URL地址里包含非西欧字符的字符串时,系统会将这些字符转换成application/x-www-form-urlencoded字符串。表单里提交时也是如此,当包含非西欧字符的字符串时,系统也会将这些字符转换成application/x-www-form-urlencoded字符串,然后在服务器端自动解码。FORM元素的enctype属性指定了表单数据向服务器提交时所采用的编码类型,默认的缺省值是“application/x-www-form-urlencoded。
Java类中提供了URLEncoder与URLDecoder操作URL转换。
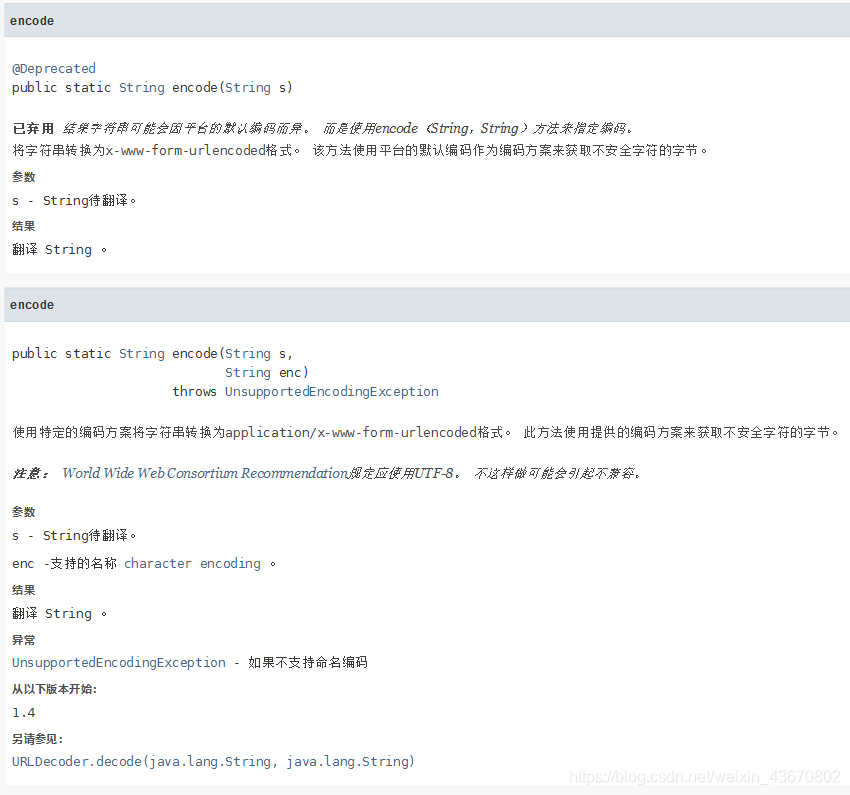
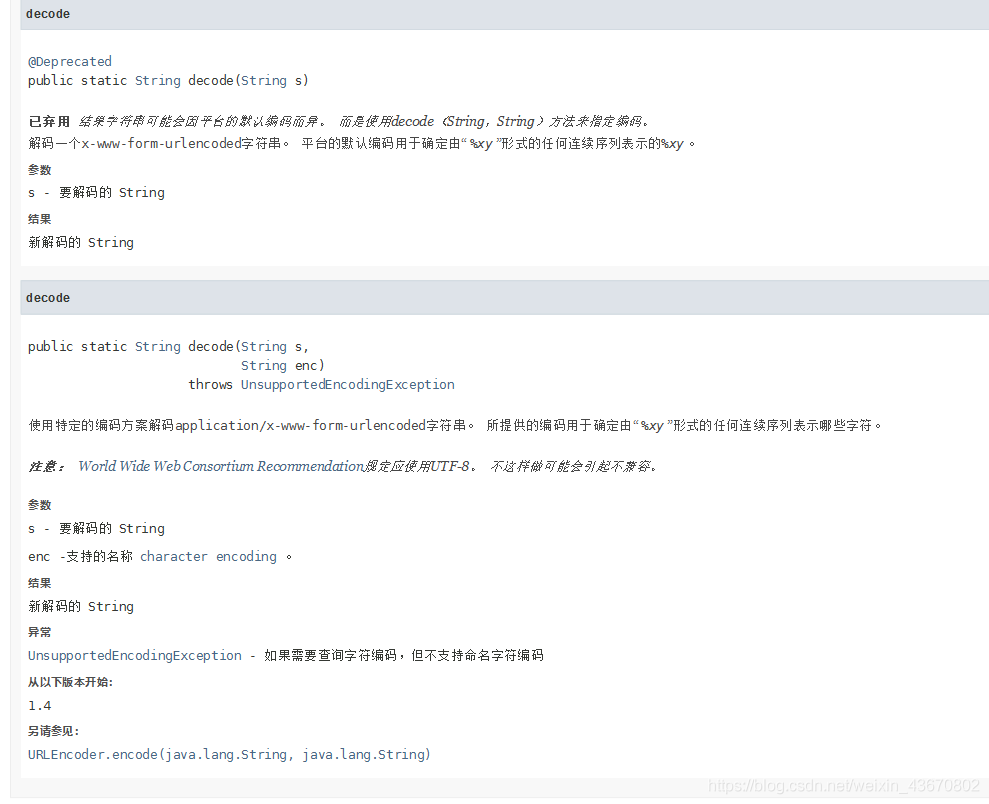
2、不同的浏览器默认对含中文的URL转化采用的编码不同
正因如此,所以才会使用Java提供的那两个URL编码类来统一编码。
3、某些Web容器自动解码问题
某些web容器在request.getParameter()自动解码,比如Tomcat就这么干。
Tomcat自动解码默认以其默认的编码解码。
Tomcat不同版本的默认编码格式
Tomcat7:ISO-8859-1
Tomcat8:UTF-8
重点来了:正因为Tomcat存在自动解码一次的问题,所以,在前端JSP页面编码中文URL时,为了防止后端获取乱码,所以采用二次编码的方式。
UTF-8编码(第一次编码)->UTF-8或iso-8859-1(第二次编码,这里看Tomcat默认哪种编码自动解码)编码->Tomcat使用默认编码自动解码(第一次解码)->手动UTF-8解码(第二次解码)
编码和解码的过程是对称的,所以不会出现乱码。
实际使用
前端
...
"/>
...
后端
...
//设置请求编码--仅针对Post请求
//request.setCharacterEncoding("utf-8");
//获取文件名--并通过前端二次编码,后端二次解码 解决中文名问题
String downloadSign=request.getParameter("download");
//采用两次编码并且两次解码
//Tomcat在getParameter时已经自动解码一次,下面我手动解码
String key=URLDecoder.decode(request.getParameter("key"),"gbk");
//测试
System.out.println("我的名字:"+key);
...















 1819
1819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









