






file1.c中的程序:
int multi(int a)
{
return (a*a);
}
文件file2.c中的程序:
#include "file1.c"
int squsum(int *pt)
{
int i = 0, sum = 0;
for (i = 0; i <= 5; i++)
{
sum += multi(pt[i]);
}
return sum;
}
pretreatmen.c中的文件
#include
#include "file1.c"
#include "file2.c"
int main()
{
int sum=0,array[] = { 0,1,2,3,4,5 }, *pt = array;
sum = squsum(array);
printf("sum is %d", sum);
}
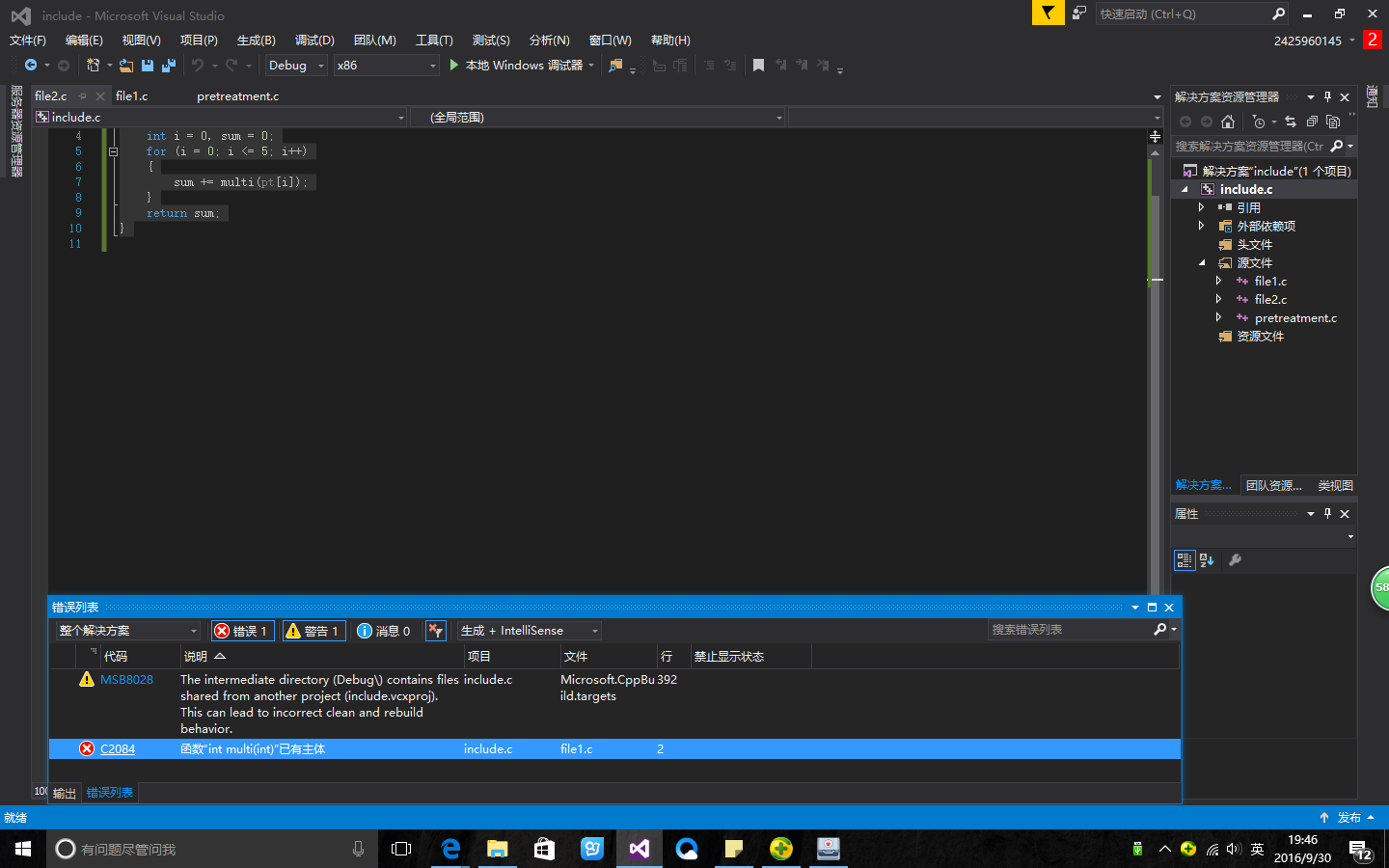
在文件pretreatment.c中我用文件包含,然后程序运行出现连接错误,信息如下:
严重性 代码 说明 项目 文件 行 禁止显示状态
警告 MSB8028 The intermediate directory (Debug\) contains files shared from another project (include.vcxproj). This can lead to incorrect clean and rebuild behavior. include.c C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V140\Microsoft.CppBuild.targets 392
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 C2084 函数“int multi(int)”已有主体 include.c e:\vs 编程文档\include\include\file1.c 2
请问一下这个改如何解决














 9256
9256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









