






在应用程序中使用
maven坐标:
com.chenlb.mmseg4j
mmseg4j-core
1.10.0
默认加载词典的路径代码如下(源码单词拼写有错误,将就着看吧,readonly):
另外,可以建立自己的词库,文件名为words*.dic,并且文件要以UTF-8无BOM格式编码。
* 每个分词文件必须以words开头,.dic结尾,如:words-canmou.dic
* 每个分词文件大小必须控制在50M以内,否则很可能会OOM
/**
* 当 words.dic 是从 jar 里加载时, 可能 defalut 不存在
*/
public static File getDefalutPath() {
if(defalutPath == null) {
String defPath = System.getProperty("mmseg.dic.path");
log.info("look up in mmseg.dic.path="+defPath);
if(defPath == null) {
URL url = Dictionary.class.getClassLoader().getResource("data");
if(url != null) {
defPath = url.getFile();
log.info("look up in classpath="+defPath);
} else {
defPath = System.getProperty("user.dir")+"/data";
log.info("look up in user.dir="+defPath);
}
}
defalutPath = new File(defPath);
if(!defalutPath.exists()) {
log.warning("defalut dic path="+defalutPath+" not exist");
}
}
return defalutPath;
}
建立以下工具类:
package com.caiya.software.service.utils;
import com.chenlb.mmseg4j.*;
import org.apache.commons.lang3.StringUtils;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import java.util.HashSet;
import java.util.Set;
/**
* 使用mmseg4j分词器,共有三种分词方法
* Created by caiya on 16/4/27.
*/
public class MMSeg4jUtils {
public static final String mode_simple = "simple";
public static final String mode_complex = "complex";
public static final String mode_max_word = "max-word";
public static final String mode_default = mode_max_word;
public static final String operator_default = " ";
public static Dictionary dictionary_default = Dictionary.getInstance();
public static Dictionary getDictionary(String path){
if(StringUtils.isBlank(path)){
throw new IllegalArgumentException("词典目录不可为空");
}
return Dictionary.getInstance(path);
}
private static Seg getSeg(String mode, Dictionary dic) {
if(mode.equals(mode_simple)){
return new SimpleSeg(dic);
}else if(mode.equals(mode_complex)){
return new ComplexSeg(dic);
}else{
return new MaxWordSeg(dic);
}
}
private static String segWords(Reader input, String wordSpilt, String mode, Dictionary dic) throws IOException {
StringBuilder sb = new StringBuilder();
Seg seg = getSeg(mode, dic);//取得不同的分词具体算法
MMSeg mmSeg = new MMSeg(input, seg);
Word word = null;
boolean first = true;
while((word=mmSeg.next())!=null) {
if(!first) {
sb.append(wordSpilt);
}
String w = word.getString();
sb.append(w);
first = false;
}
return sb.toString();
}
public static String segWords(String txt, String wordSpilt, String mode, Dictionary dic) throws IOException {
return segWords(new StringReader(txt), wordSpilt, mode, dic);
}
public static String segWords(String txt, String wordSpilt) throws IOException {
return segWords(txt, wordSpilt, mode_default, dictionary_default);
}
public static Set segWordsSet(String txt, String wordSpilt, String mode, Dictionary dic) throws IOException {
Set sets = new HashSet();
String segWords = segWords(new StringReader(txt), wordSpilt, mode, dic);
for (String s : segWords.split(wordSpilt)){
sets.add(s);
}
return sets;
}
public static Set segWordsSet(String txt, String mode, Dictionary dic) throws IOException {
return segWordsSet(txt, operator_default, mode, dic);
}
public static Set segWordsSet(String txt) throws IOException {
return segWordsSet(txt, mode_default, dictionary_default);
}
}
调用方式:
SolrQuery params = new SolrQuery();
StringBuffer buffer = new StringBuffer();
if (StringUtils.isNotBlank(softwareQuery.getKeyWord())) {
String kw = softwareQuery.getKeyWord();
try {
// kw = MMSeg4jUtils.segWords(kw, " OR ");
kw = MMSeg4jUtils.segWords(kw, " OR ", MMSeg4jUtils.mode_complex, SoftwareConstants.dictionary);
} catch (IOException e) {
logger.error("mmseg4j切词出现异常", e);
}
buffer.append("title:(").append(kw).append(")^50");
buffer.append(" OR tag_name:(").append(kw).append(")^1.7");
buffer.append(" OR author:(").append(kw).append(")^1.1");
buffer.append(" OR origin:(").append(kw).append(")^1.1");
buffer.append(" OR description:(").append(kw).append(")^1.1");
buffer.append(" OR txt:(").append(kw).append(")^1.1");
} else {
buffer.append("*:*");
}
params.setQuery(buffer.toString());
//其中, // 初始化词典文件 /Users/caiya/workspace/test/dic
// dictionary = MMSeg4jUtils.getDictionary(dicPath);
分词效果:
扩展词典内容:
$ cat words.dic
十衣素
韩都衣舍专卖旗舰旗舰店
十衣素啊哈哈
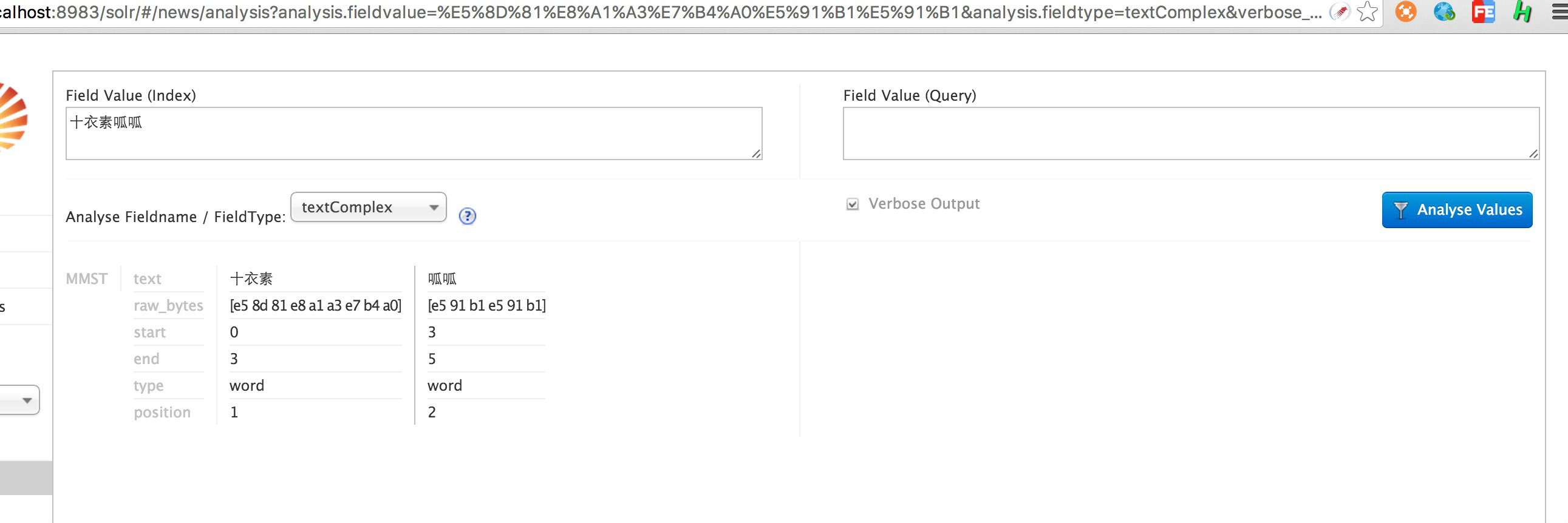
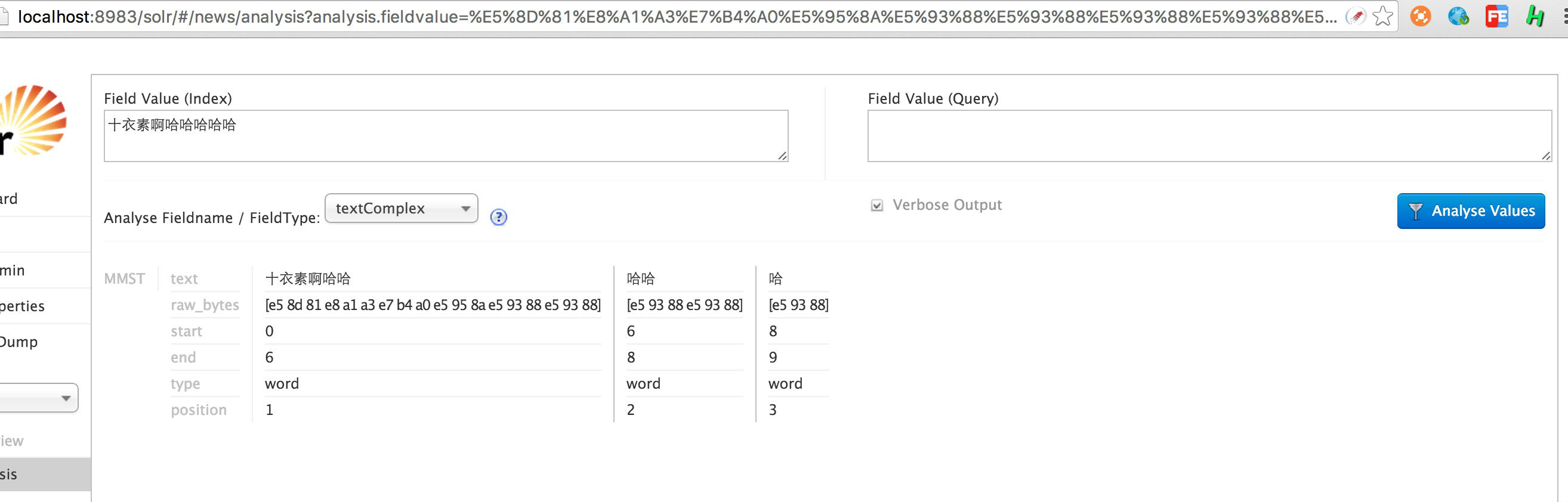
由此可见,一般的分词器都是基于正向最大匹配,稍后我们可以最这块进行拓展和挖掘。
在solr中的使用
目前solr 4.7.2使用mmseg4j 2.0.0版本
dicPath 指定词库位置(每个MMSegTokenizerFactory可以指定不同的目录,当是相对目录时,是相对 solr.home 的目录),mode 指定分词模式(simple|complex|max-word,默认是max-word)。














 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









