






解释下什么叫做原本时间的曲线....假设原来的样本的关系是某时刻T,f:X(T)->y(T),这个y(t)就是原本时间的曲线..........然后我们想用T时刻的X预测T+1时刻的y,也就是P:X(T)->yy(T),如果yy(T)=y(T+1)就是预测成功但是问题就是在样本少的情况下yy(T)约等于y(T)我按照FARUTO老师在中第14章预测上证指数的源代码里面进行了些改造,就遇到上面那个问题.老师的预测方法是用第T天的属性(开盘价,最高价,最低价,收盘价....),记做SX(T),去预测T+1天的比如收盘价,记做SPJ(T+1),老师是用训练数据作为测试数据的.然后我改造的目的是将数据分成几组来做测试,我想要的结果是预测曲线SVM_SPJ(T)接近SPJ(T+1)结果发现得到的预测曲线SVM_SPJ(T)的形态却是接近SPJ(T),曲线的形态说的就是它波动的程度和趋势.后来经过不断的修改测试就发现原来是训练样本数大于1500的时候,SVM预测曲线SVM_SPJ(T)与正确的预测曲线SPJ(T+1),也就是 形态是接近的;少于1200的时候SVM_SPJ(T)与SPJ(T)的形态相同;样本介于两者之间的时候SVM_SPJ(T)是介于SPJ(T)和SPJ(T+1)之间的.我的问题就是为什么样本不足的时候预测曲线的形态与原本曲线的相似?下面是图片使用1000个样本进行训练,可以看到预测曲线与原本曲线形态相似与训练曲线有一天的延迟
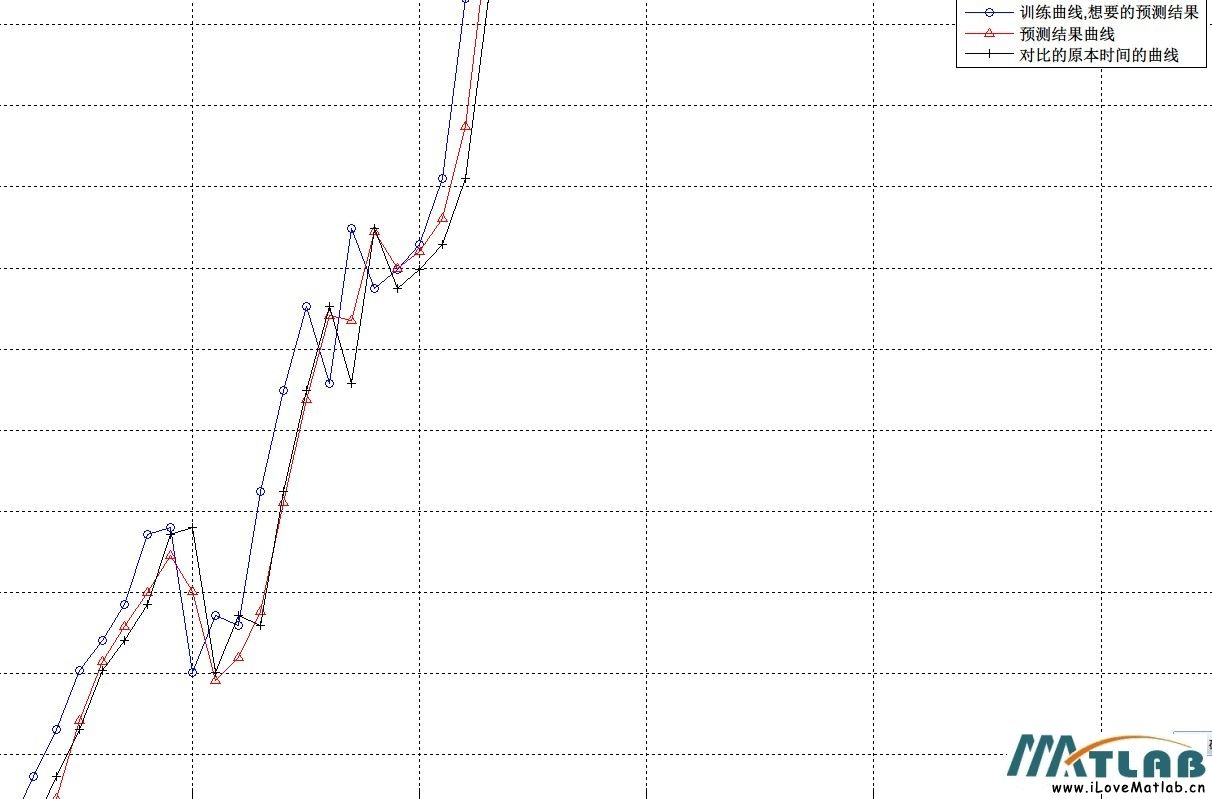
上证预测曲线图样本数1000.jpg (106.53 KB, 下载次数: 2)
2013-6-18 20:16 上传
使用1500个样本进行训练,预测曲线形态介于原本曲线形态与训练曲线之间
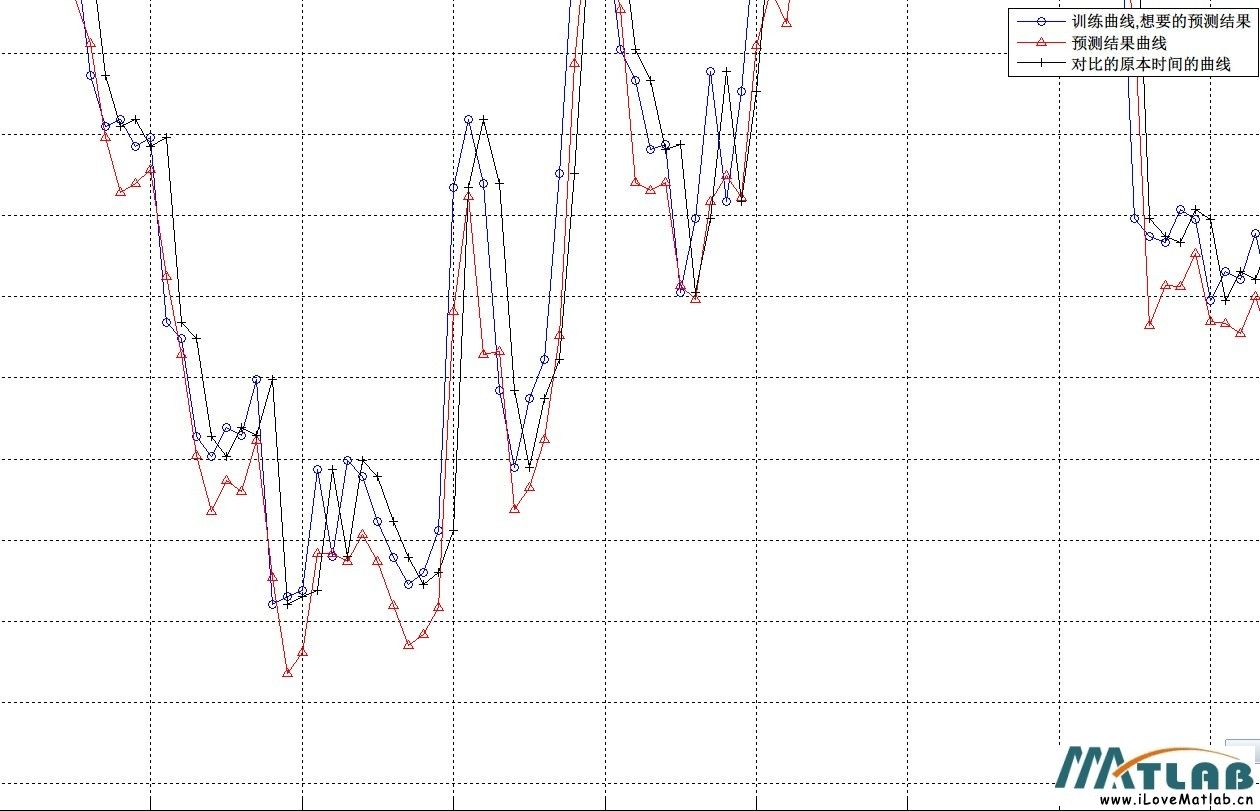
上证预测曲线图样本数1500.jpg (145.95 KB, 下载次数: 1)
使用1500个样本进行训练
2013-6-18 20:16 上传
使用4500个样本进行训练,预测曲线形态与训练曲线大致相似.
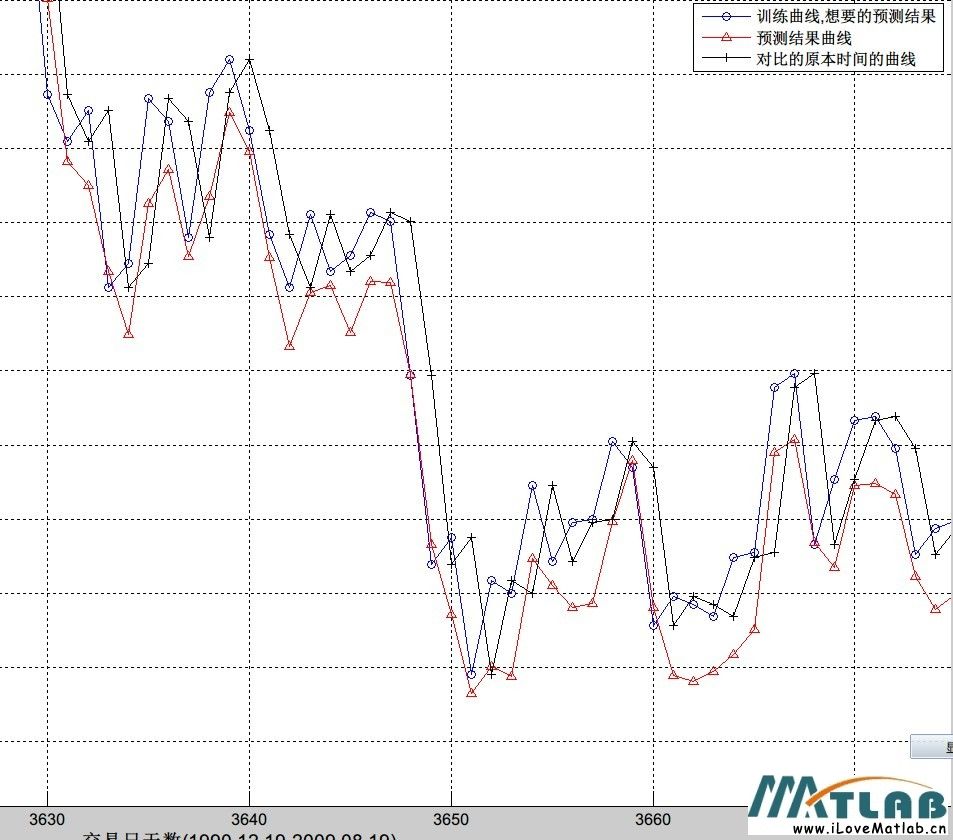
上证预测曲线图样本数4500.jpg (126.65 KB, 下载次数: 1)
使用4500个样本进行训练
2013-6-18 20:16 上传
下面是代码因为带有数据,所以用附件

2013-6-18 20:18 上传
点击文件名下载附件














 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









