






Secondary NameNode有啥用?
对于刚接触Hadoop可能弄不明白NameNode和Secondary NameNode的区别和关系。很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,非也。为啥大家有这样的误解呢,在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一,但Secondary 有辅助,从属的意思,也能勉强说名字还算可以。先聊聊 NameNode,后面就明白secondary namenode有啥用了,namenode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它启动时,这些信息被加载在内存中的,运行时持久化到磁盘文件。namenode通过维护fsimage 和editlog2个文件运转的。
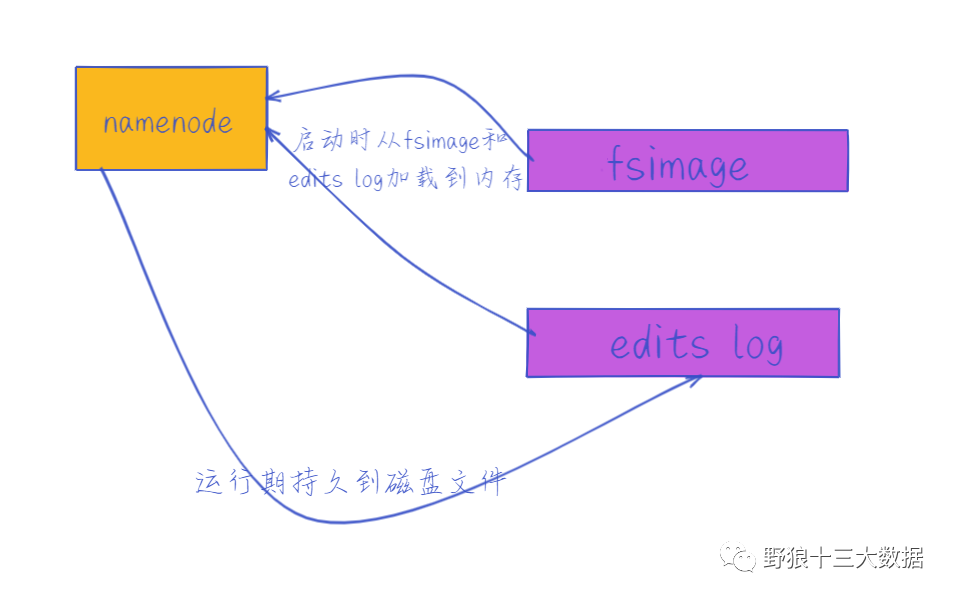
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。一句话,记录datanode的行为的。
fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。一句话,Fsimage就是在某一时刻,整个hdfs 的快照,类似于windows的恢复点。
namdenode要加载的数据=fsimage+editlog ,但只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:edit logs文件会变的很大,如何管理将是一个挑战。
NameNode的重启会花费很长时间,很多改动要合并到fsimage文件上。
如果NameNode挂掉了,会丢失内存中但是没有写到edit logs的这部分。
Secondary NameNode 内部实现原理
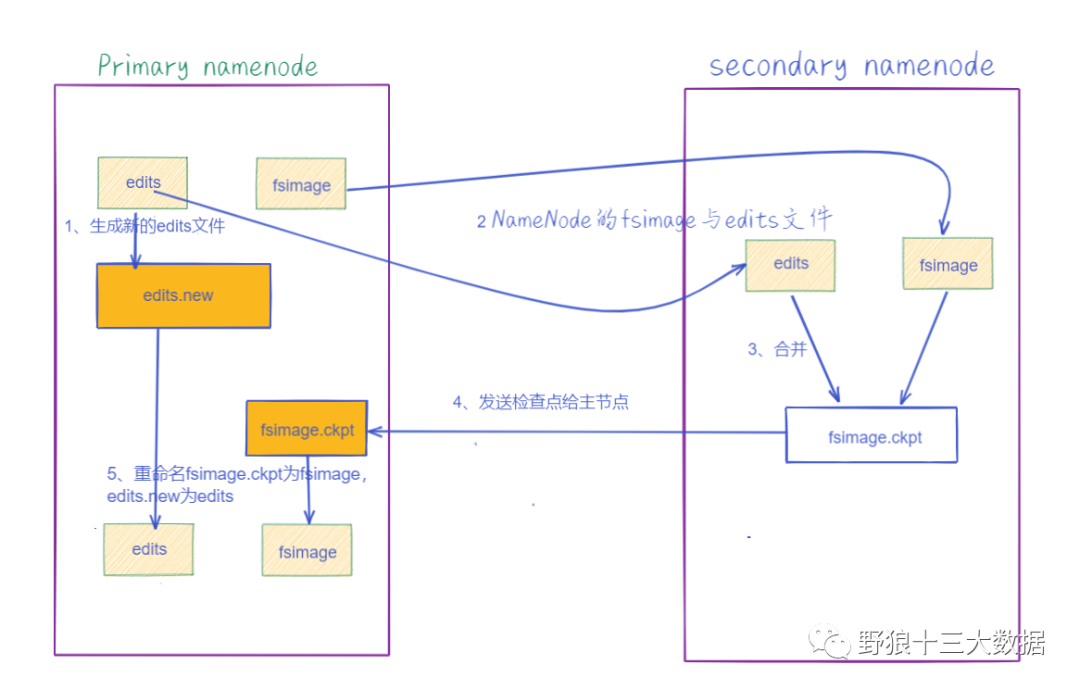
日志与镜像的定期合并总共分五步:
- SecondaryNameNode通知NameNode准备提交edits文件,此时主节点产生edits.new。
- SecondaryNameNode通过http get方式获取NameNode的fsimage与edits文件(在SecondaryNameNode的current同级目录下可见到 temp.check-point或者previous-checkpoint目录,这些目录中存储着从namenode拷贝来的镜像文件)。
- SecondaryNameNode开始合并获取的上述两个文件,产生一个新的fsimage文件fsimage.ckpt。
- SecondaryNameNode用http post方式发送fsimage.ckpt至NameNode。
- NameNode将fsimage.ckpt与edits.new文件分别重命名为fsimage与edits,然后更新fstime,整个checkpoint过程到此结束。
其中,CheckPoint触发机制。
默认SecondaryNameNode每隔一小时执行一次checkPoint。
一分钟检查一次操作次数,默认当操作次数达到1百万时,SecondaryNameNode执行一次checkPoint。

hadoop 2.7.6版本在hdfs-site.xml配置文件中控制
<property> <name>dfs.namenode.checkpoint.periodname> <value>3600value> property><property><name>dfs.namenode.checkpoint.check.periodname><value>60value><description> 1 分钟检查一次操作次数description>property><property><name>dfs.namenode.checkpoint.txnsname><value>1000000value><description>操作动作次数description>property>HA搭建参考历史文章:hadoop HA集群搭建















 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









