






最近我们被客户要求撰写关于贝叶斯非参数模型的研究报告,包括一些图形和统计输出。
概述
最近,我们使用贝叶斯非参数(BNP)混合模型进行马尔科夫链蒙特卡洛(MCMC)推断。
在这篇文章中,我们通过展示如何使用具有不同内核的非参数混合模型进行密度估计。在后面的文章中,我们将采用参数化的广义线性混合模型,并展示如何切换到非参数化的随机效应表示,避免了正态分布的随机效应假设。
使用Dirichlet Process Mixture模型进行基本密度估计








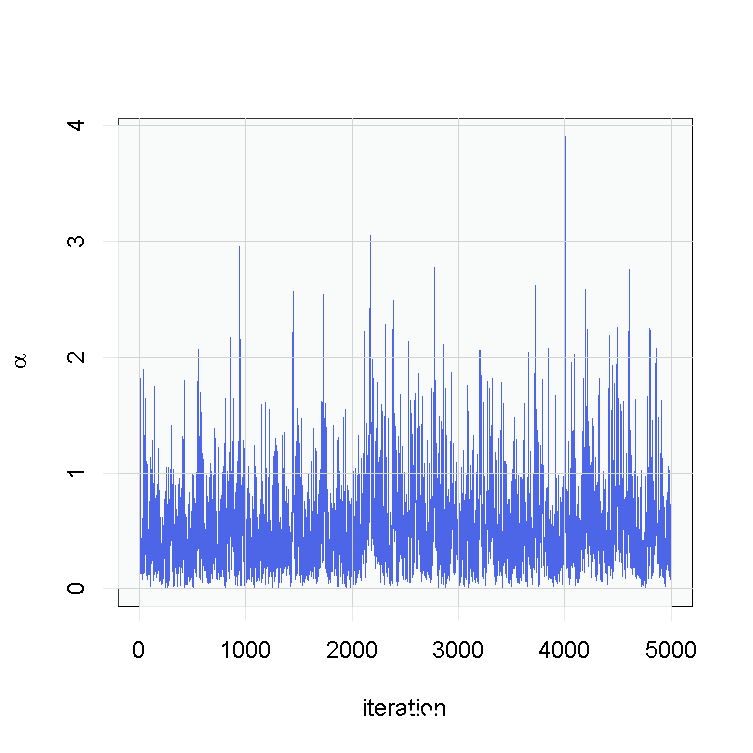
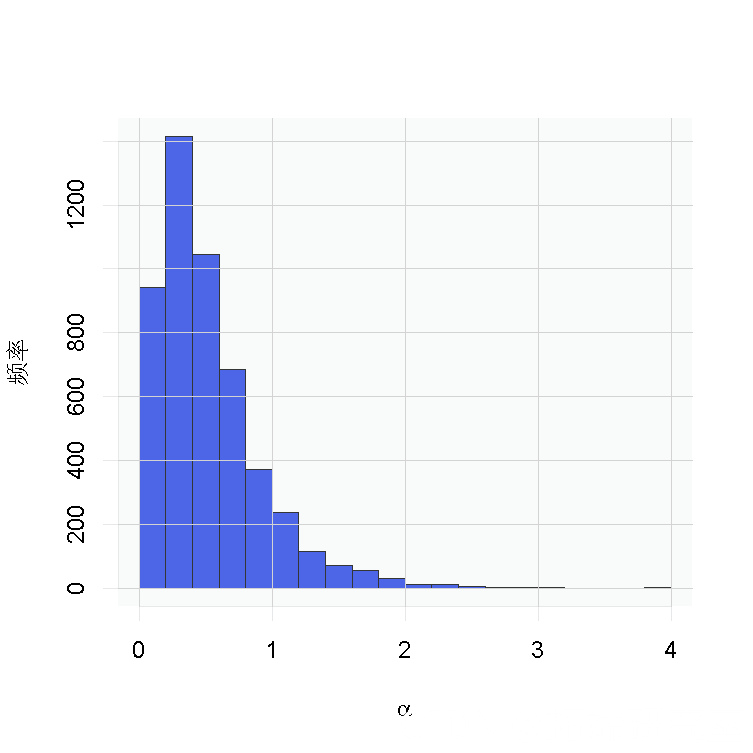

在这个模型下,对于一个新的观察
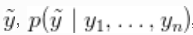
,后验预测分布是最佳密度估计(在平方误差损失下)。这个估计的样本可以很容易地从我们的MCMC产生的样本中计算出来。
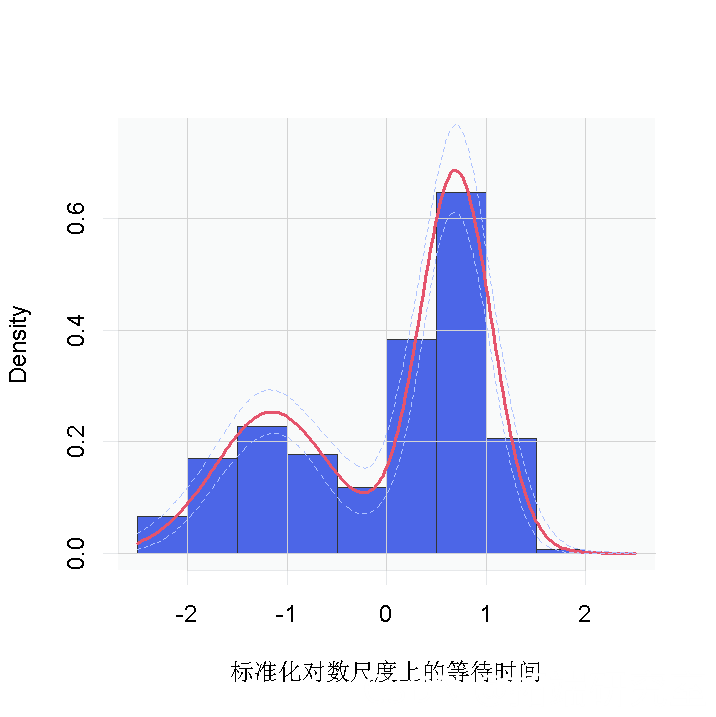
然而,回顾一下,这是对等待时间的对数的密度估计。为了获得原始尺度上的密度,我们需要对内核进行适当的转换。
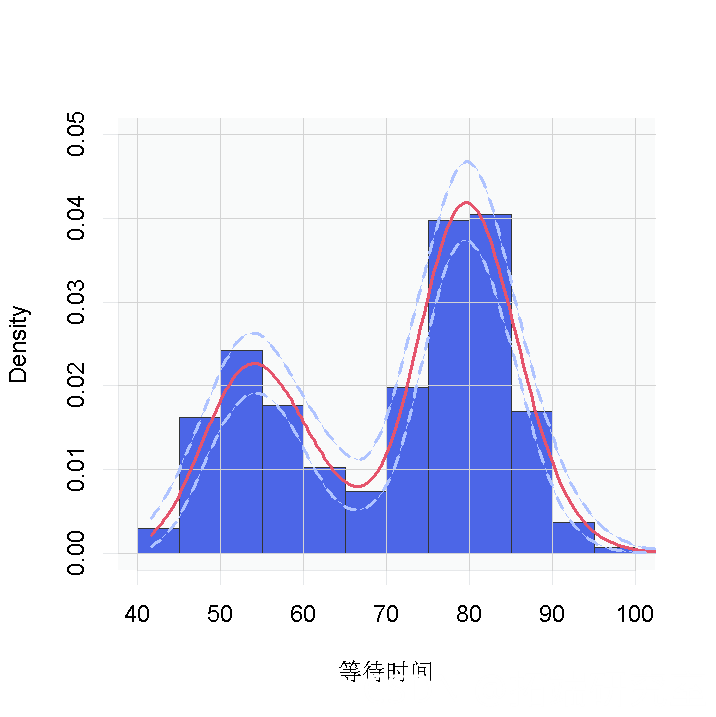
无论是哪种情况,都有明显的证据表明,数据中的等待时间有两个组成部分。
生成混合分布的样本

使用CRP表示法拟合伽马混合分布



从混合分布中生成样本

我们使用这些样本来创建一个数据密度的估计值,以及一个95%置信带。
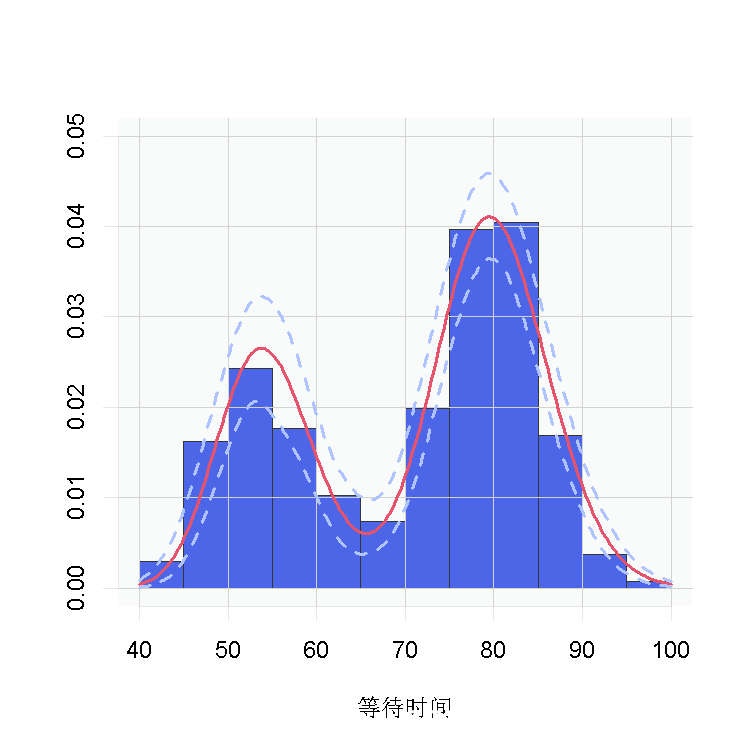
我们再次看到,数据的密度是双峰的,看起来与我们之前得到的数据非常相似。
使用stick-breaking 表示法拟合伽马DP混合分布
模型

注意,截断水平
已被设置为Trunc值,该值将在函数的常数参数中定义。
运行MCMC算法
下面的代码设置了模型数据和常量,初始化了参数,定义了模型对象,并建立和运行了Gamma混合分布的MCMC算法。当使用stick-breaking表示时,会指定一个分块Gibbs抽样器(Ishwaran, 2001; Ishwaran and James, 2002)。

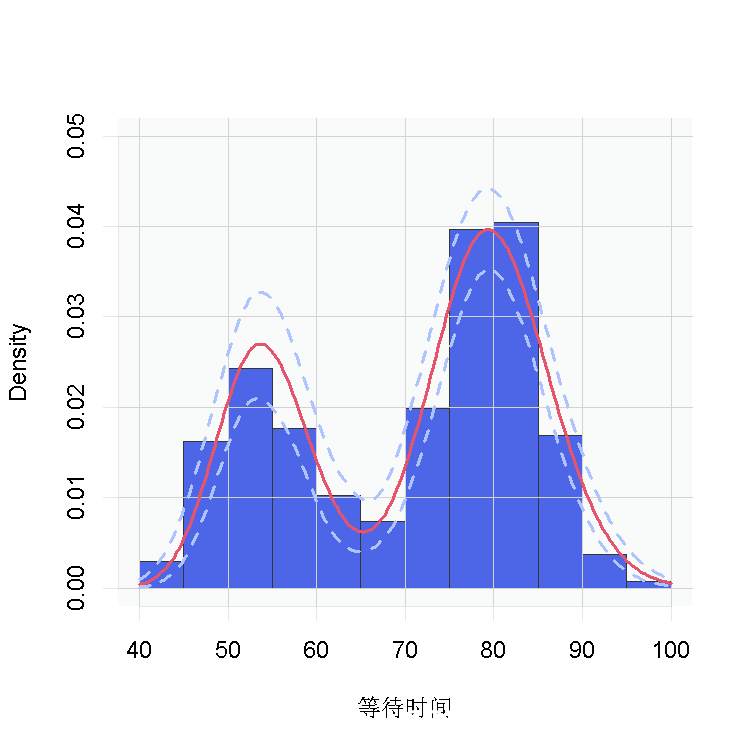
正如预期的那样,这个估计值看起来与我们通过CRP表示的过程获得的估计值相同。
贝叶斯非参数化:非参数化随机效应
我们将采用一个参数化的广义线性混合模型,并展示如何切换到非参数化的随机效应表示,避免了正态分布的随机效应假设。
心肌梗死(MIs)的参数化meta分析
我们将在对以前非常流行的糖尿病药物 "Avandia "的副作用进行meta分析的背景下,说明使用非参数混合模型对随机效应分布进行建模。我们分析的数据在引起对这种药物的安全性的严重质疑方面发挥了作用。问题是使用"Avandia "是否会增加心肌梗死(心脏病发作)的风险。,每项研究都有治疗和对照组。

模型的制定

运行MCMC
让我们来运行一个基本的MCMC。
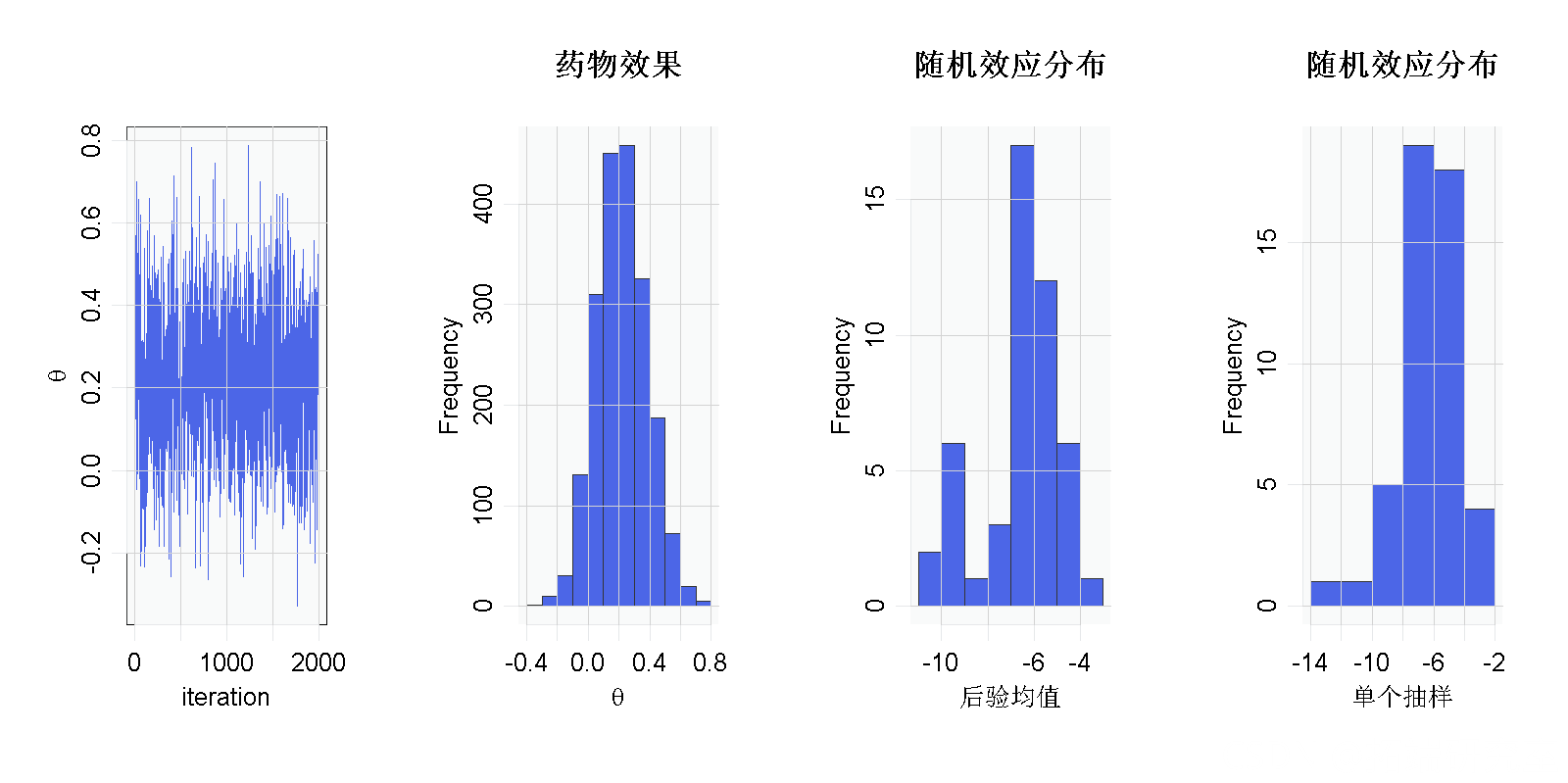
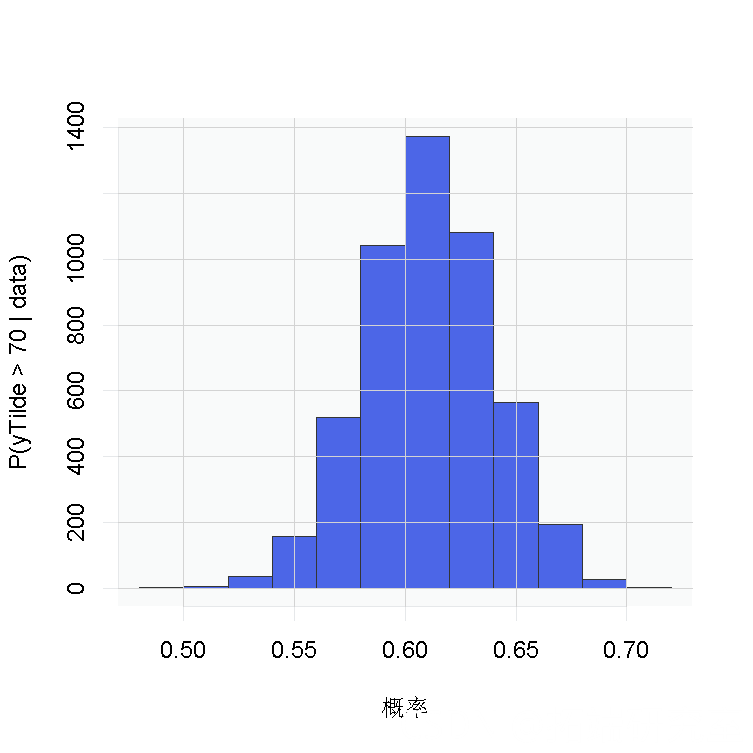
结果表明,对照组和治疗组之间存在着整体的风险差异。但是正态性假设呢?我们的结论对该假设是否稳健?也许随机效应的分布是偏斜的。
用于meta分析的基于DP的随机效应模型
模型

运行MCMC
以下代码对模型进行了编译,并对模型运行了一个压缩Gibbs抽样
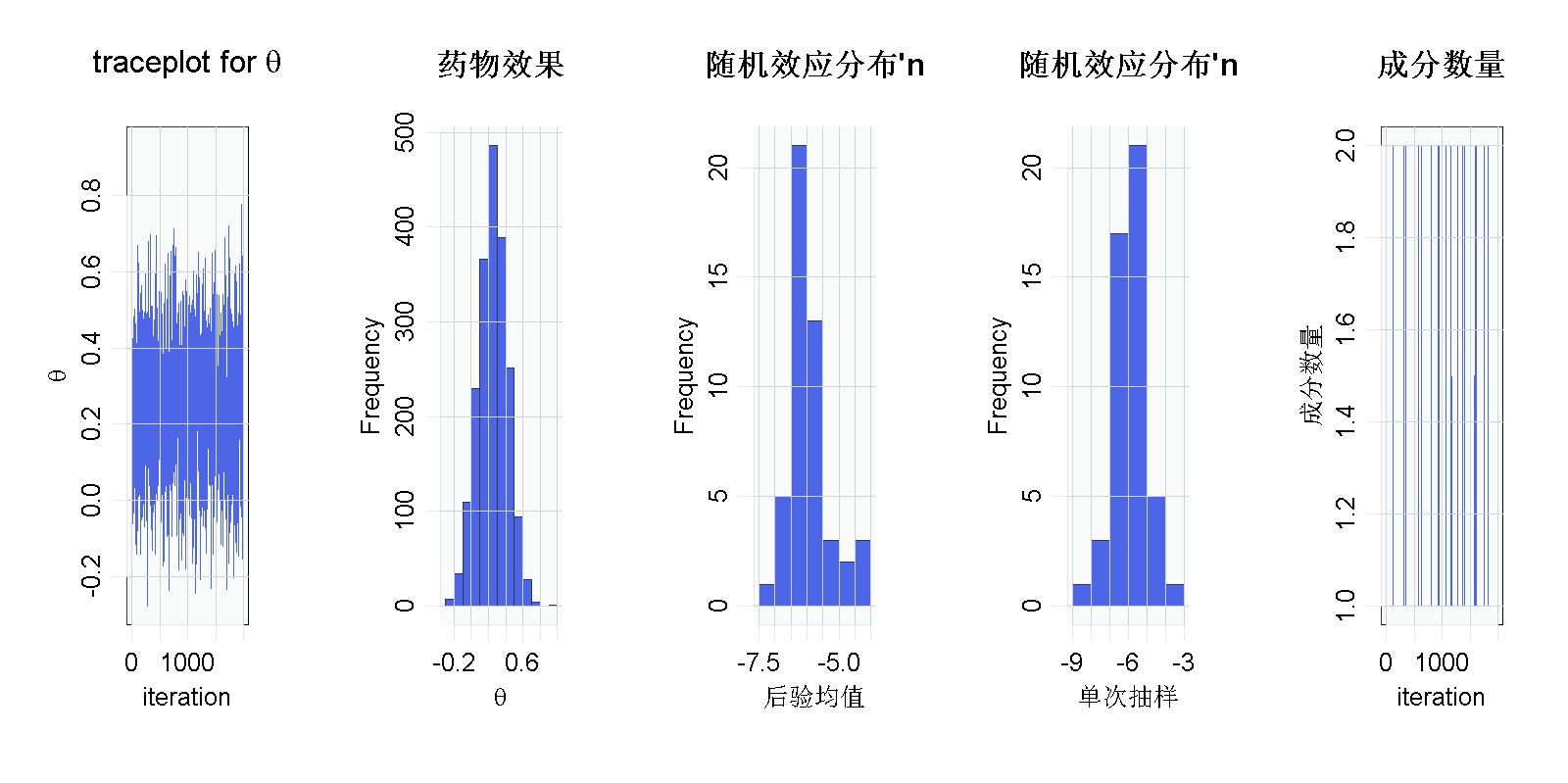
主要推论似乎对原始的参数化假设很稳健。这可能是由于没有太多证据表明随机效应分布中缺乏正态性。
参考文献
Blackwell, D. and MacQueen, J. 1973. Ferguson distributions via Polya urn schemes. The Annals of Statistics 1:353-355.
Ferguson, T.S. 1974. Prior distribution on the spaces of probability measures. Annals of Statistics 2:615-629.
Lo, A.Y. 1984. On a class of Bayesian nonparametric estimates I: Density estimates. The Annals of Statistics 12:351-357.

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









