






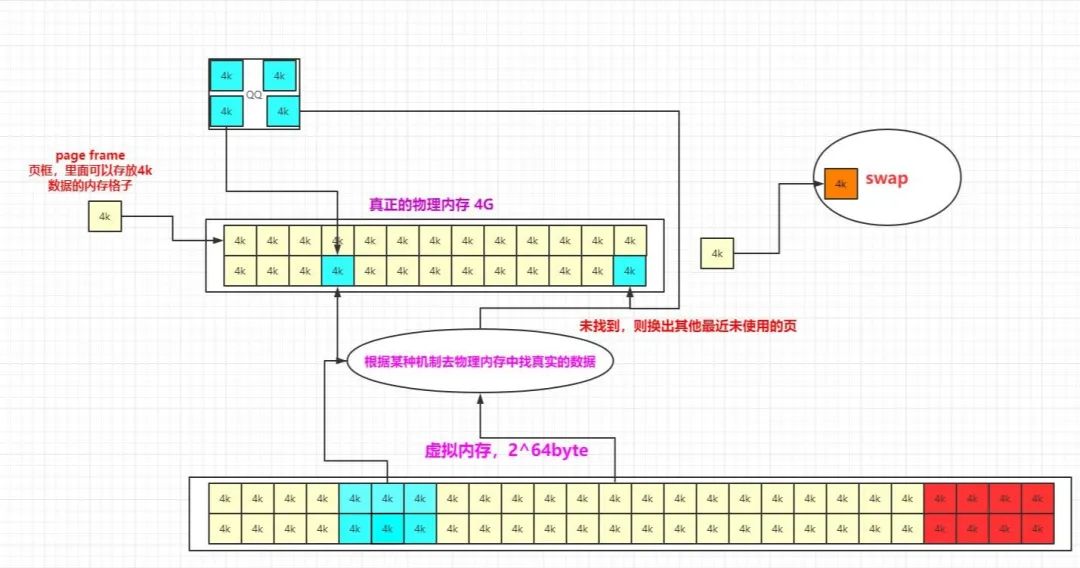
前边讲了很多有关linux系统的基础知识,今天我们来手动实现一下linux内存淘汰算法LRU算法。如下图便是我们之前讲过的,当linux内存不足时,需要将最不常用的页换出内存到swap分区,再从磁盘加载需要的内存进来。这里面其实包含着一种思想,时间局部性原理,当一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
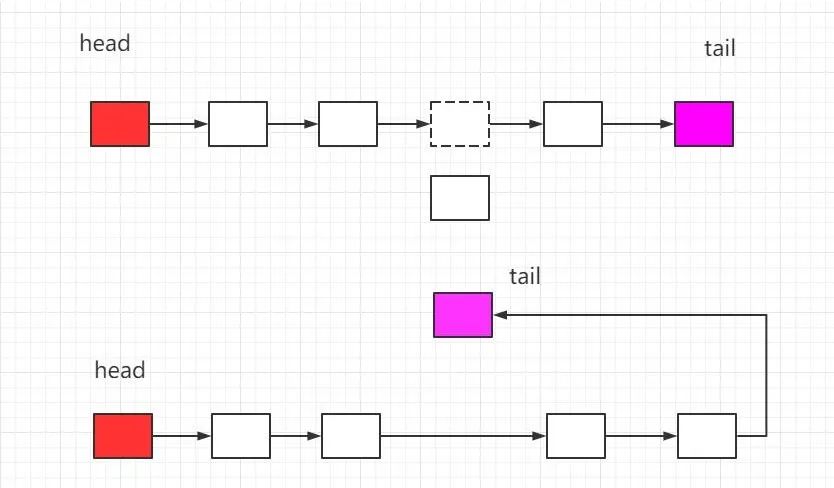
实现这种原理需要使用到数据结构中的链表。最新进入内存的页我们假设把它放到链表的尾部,每当中间某块内存被使用时,我们就把该内存移动到链表尾部,这样一来,链表头部就是最不常用的数据,而链表尾部则是最近使用的数据。这里的操作只需要一个头部指针和一个尾部指针,便可以实现复杂度为O(1)的操作。这是链表的优点
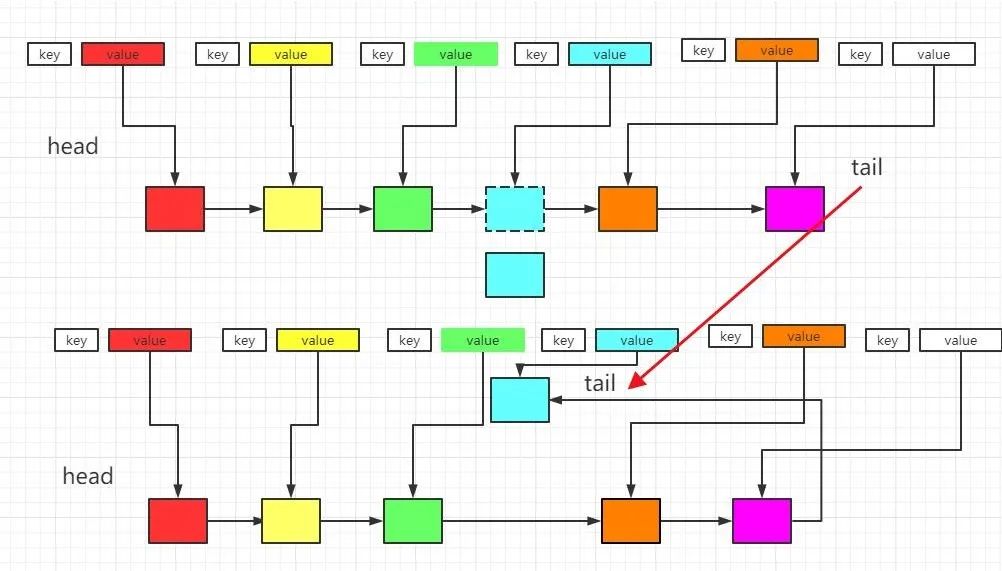
可是我们怎么才能知道,哪一块内存最近被使用呢,如果我们采用标记节点,被使用的节点会被标记,那么我们每次都需要遍历整个列表,直到找到被标记的节点,然后进行节点移位操作,这个寻找过程就是一个O(n)的操作。所以我们必须要对这个步骤进行改善,那么如何改善才能使得我们可以快速定位到一块内存呢,其实也很容易想到计算机中常常使用的一个手段,那就是空间换取时间,维护一份数据结构呗,当你需要操作哪一块内存的时候,去这个数据结构中去查找,每当你操作完成后,更新这个数据结构。 维护的数据结构如下。

所以我们必须要对这个步骤进行改善,那么如何改善才能使得我们可以快速定位到一块内存呢,其实也很容易想到计算机中常常使用的一个手段,那就是空间换取时间,维护一份数据结构呗,当你需要操作哪一块内存的时候,去这个数据结构中去查找,每当你操作完成后,更新这个数据结构。 这里我们使用的当然是hash表这种根据key:value直接定位的数据结构。java中我们就是用HashMap。
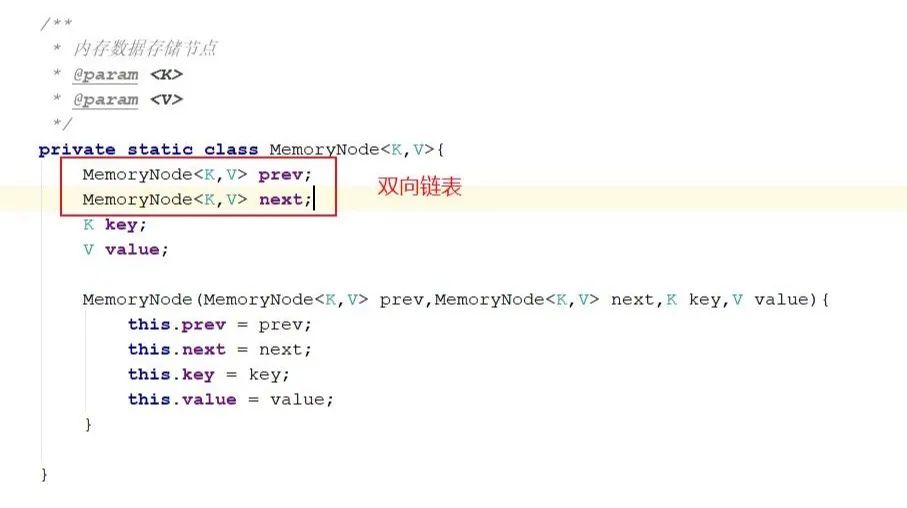
可是此处仍然会出现一个问题,当我们找到一个内存结点之后,将尾部指针指向该新节点,可是,接下来,我们需要将刚才内存的前驱节点和后继节点相连。由于我们的链表是单向的,所以,我们找不到该节点的前驱节点,只能又重新从头遍历,这又是O(n)的操作,所以一般都是hash表+双向链表的组合,也就是在节点数据结构中多维护一个指针。让每个节点知道自己前边是谁,后边是谁。最后我们就实现了O(1)操作进行内存淘汰。数据结构如下图所示
将数据load进内存,如果内存撑爆,开始淘汰头部节点。memoryMap为我们维护的hash表。

从内存中获取一个内存块,则需要进行尾部更新,如下图

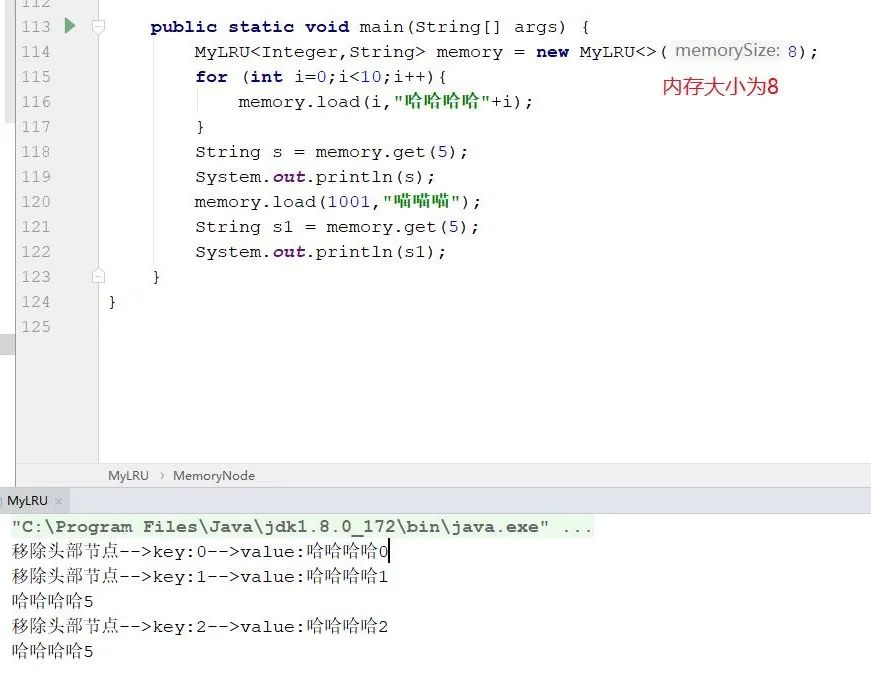
测试结果如下所示。















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









