






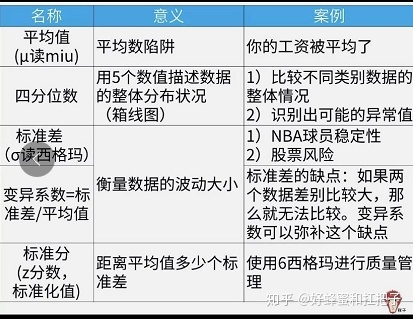
1、描述数据常用的4个指标
1.1、 平均值
不再赘述
1.2、四分位数
1.2.1、如何计算中位值Q2(先排序,后计算中间位置)
- 在数据集 10 11 12 13 中,中位数为11.5[(11+12)/2]
- 在数据集 10 11 12 13 10 中,中位数为12
1.2.2、上四分位Q3和下四分位Q1(中位数左右数据分别一分为二)
-
-
- 在数据集 1 1 2 2 2 3 3 4 4 6 7 8 10 11 14 15 20 22(总共18个数字,在这里我以深色浅色5个5个交替排列,已经以从小到大的方式进行了排列)
- 中位数:1 1 2 2 2 3 3 4 4 6 78 10 11 14 15 20 22 18个数,为偶数,为最中间2个位置的数字的平均值(也就是第9个位置和第10个位置,分别为4和6,中位数为5)
- 上四分位:1 1 2 2 2 3 3 4 4 6 7 8 10 11 14 15 20 22,标粗的8个数字的中位数,为[(2+2)/2]
- 下四分位:1 1 2 2 2 3 3 4 4 6 7 8 10 11 14 15 20 22,标粗的8个数字的中位数,为[(11+14)/2]
-
1.2.3、四分位数的描述
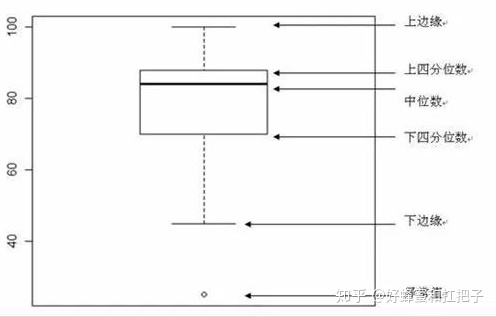
1.2.3.1、箱线图的描述
-
-
- 最上方和最下方的横线是上界和下界
- 中间的三条箱子的横线分别代表上四分位、中位数、下四分位
- 另外还有异常值
-
1.2.3.2、箱线图的应用
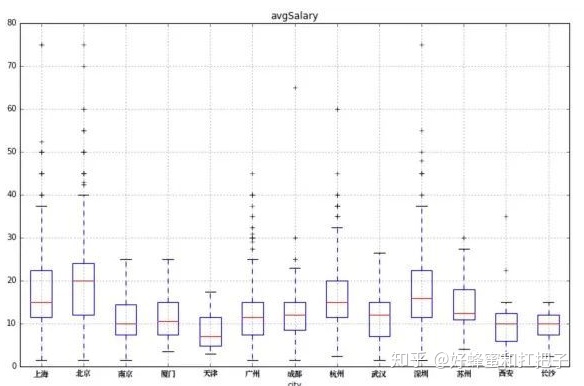
- 比较多批数据的形状
- 箱子的上下限,分别是数据的上四分位数和下四分位数。这意味着箱子包含了50%的数据。因此,箱子的宽度在一定程度上反映了数据的波动程度。箱体越扁说明数据越集中,端线(也就是“须”)越短也说明数据集中。
- 比如最右边的长沙,说明数据分析师的工资分布区间是比较集中的,波动程度比较小
- 直观明了地识别数据批中的异常值
- 箱形图可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。通过计算这些统计量,生成一个箱体图,箱体包含了大部分的正常数据,而在箱体上边界和下边界之外的,就是异常数据。
- 最小估计值:Q1(下四分位)-K(Q3-Q1) 其中K为异常值
- 最大估计值:Q3(上四分位)+K(Q3-Q1)
- 案例:69 69 70 70 70 70 71 71 71 72 73 300
- 中位数Q2:70.5
- 上四分位数Q3:71.5
- 下四分位数Q1:70
- K=1.5中度异常;K=3极度异常
- 最大估计值:Q3(上四分位)+K(Q3-Q1)=73.75
- 最小估计值:Q1(下四分位)-K(Q3-Q1)=67.75
- 结论:系统自动剔除异常的值,温度异常的值300被排除在正常值之外
- 判断数据的偏态和尾重
- 对于标准正态分布的大样本,中位数位于上下四分位数的中央,箱形图的方盒关于中位线对称。中位数越偏离上下四分位数的中心位置,分布偏态性越强。
- 比如:上海的中位数比较靠近下分位数,说明数据的稳定集中在下四分位和中位数之间
1.3、标准差
- 计算公式
- 用来衡量数据的波动性,比如如何衡量NBA球员的稳定性
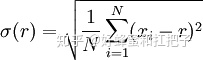
- 标准差的两个问题
- 标准差的单位是什么?——对于篮球运动员来说,就是分,比如标准差1.4,代表波动1.4分
- 标准差是大一点好,小一点好?——如果是是研究大公司的工资,希望工资波动性大一点,可以争取更高的工资,上限高;如果是衡量稳定性,希望小一点
- 标准差案例:
- 股票波动大小,标准差大小代表股票波动更大
- 夏普比率=(投资回报-无风险回报)/投资组合的标准差;美国的夏普比率是0.5:也就是风险是回报的2倍,全球表现的最好,中国夏普比率是0.22,风险是回报的5倍
1.4、变异系数
标准差的缺点:如果两个数据差别比较大,那么就无法比较。
- 计算公式
- 如果能用标准差除以数据集的平均值,就可以消除数据大小的差异。标准差除以平均值得到的值叫作变异系数。
- 变异系数案例
- 店铺A的销售额是1000万,店铺B的销售额是100万,两个店铺的标准差都是20万。
- 如果说两个店铺的“波动幅度相同”,这是不对的。
- 因为一般情况下,如果原始数据值较大,那么它的波动(标准差)也会比较大。
- 这句话怎么理解呢?比如,20万对于1000万和100万的比例是不一样的,一个是五分之一,一个是五十分之一。
- 所以,我们通常用变异系数来比较不同数据集的波动大小。
1.5、标准分
- 计算公式
- (单个值- 平均值)/标准差,代表距离平均值多少个标准差
- 标准分案例
- 质量管理,六西格玛质量管理
1.5、总结
1.6、电商与婴儿数据
- 熟悉数据集
- 字段的中文翻译已标注在excel中
- bigint:Transact-SQL的系统数据类型,当整数值超过int数据范围时才可以使用。为了实现兼容性,int数据类型仍是 Microsoft SQL Server 2005 中的主要整数数据类型。
- int数据类型所表示的数值范围从-2^31到2^31-1,也就是说,你可以用int数据类型来表达-2,147,483,648到2,147,483,647(即大约正负二十亿)之间的整数。一个int型占用四个字节的存储空间。
- bigint可以精确的表示从-2^63到2^63-1(即从-9,223,372,036,854,775,808到 9,223,372,036,854,775,807)之间的整数,它占用了八个字节的存储空间。
- String:是C++、java、VB等编程语言中的字符串,字符串是一个特殊的对象,属于引用类型
- 你想从该数据集中分析哪些业务问题?你觉得哪些字段有助于你解决这些问题?为什么?你想从该数据集中得到哪些描述统计信息?
- 如果是我,我可能从遍历的角度来说:
- 首先从1个数据维度进行遍历
- 第一张表(商品信息)
- 从商品一级分类和二级分类的数据汇总,可以判断出该数据集中的各种类销量对比
- 可以对物品编号相同的东西:分析property:分析出什么大小、尺码、品牌、等描述, 针对这些销售数据进行不同物品的备货
- 对购买时间的分析:可以分析哪个月份销量的大小,对于销量较少的月份,分析原因,进行广告投放或其他操作;对于销量较多的月份,分析原因,可以做活动,让销量更高
- 第二张表(婴儿信息)
- 通过对出生日期的分析:可以知道应该重点投放什么年龄段的商品
- 通过对性别的分析:知道广告投放的重点板块是男孩还是女孩
- 第一张表(商品信息)
- 从2个数据维度进行遍历
- 同样的用户id,分析购买时间以及property,进行不同时间段、不同产品的的个性化推荐
- 首先从1个数据维度进行遍历















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









