






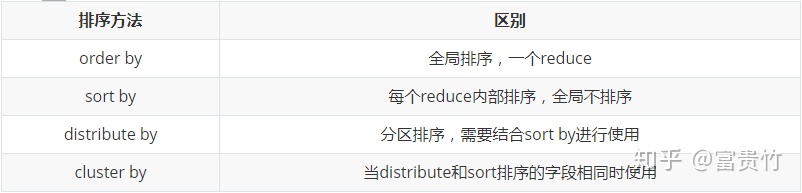
hive中排序查询的语法见:LanguageManual SortBy,排序中包括ORDER BY, SORT BY, CLUSTER BY, and DISTRIBUTE BY四种方法。
1.order by
order by是与关系型数据库的用法是一样的,还以员工表emp为例,按照员工编号降序进行排列的查询语句如下: select * from emp order by empno desc; 执行结果如下:
hive (default)> select * from emp order by empno desc;
Query ID = hive_20190221201414_f8b41ee1-c06e-4c44-8298-4b685b54aff1
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550060164760_0022, Tracking URL = http://node1:8088/proxy/application_1550060164760_0022/
Kill Command = /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1550060164760_0022
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-02-21 20:14:30,472 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:15:07,210 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.62 sec
2019-02-21 20:15:40,108 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.85 sec
MapReduce Total cumulative CPU time: 4 seconds 850 msec
Ended Job = job_1550060164760_0022
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.85 sec HDFS Read: 9730 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 850 msec
OK
empno ename job mgr hiredate sal comm deptno
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 90.76 seconds, Fetched: 14 row(s)可以看到查询的结果已经按照empno进行降序排列。在实际使用中需要注意的是order by是针对全局数据进行排序,所以最终只会有1个reduce,因为一个reduce对应一个输出文件,全局排序的话只能有一个输出文件,这个是不受hive的参数控制的。如果要查询的结果集数据量比较大的话,只有一个reduce运行,那么效率会非常低,所以在实际应用中一定要谨慎使用order by。
2.sort by
对每一个reduce内部进行排序,而对全局结果集来说是没有进行排序的。一般在实际使用中会比较经常使用sort by。要测试sort by的功能,我们需要先设置reduce的数量,使用下面的语句可以设置执行时reduce的个数: set mapreduce.job.reduces=<number> 查询语句为: select * from emp sort by empno asc; 执行结果如下:
hive (default)> set mapreduce.job.reduces=3;
hive (default)> set mapreduce.job.reduces;
mapreduce.job.reduces=3
hive (default)> select * from emp sort by empno asc;
Query ID = hive_20190221202727_6e33d79c-264e-4693-a699-1d1b1a6d81d7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550060164760_0023, Tracking URL = http://node1:8088/proxy/application_1550060164760_0023/
Kill Command = /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1550060164760_0023
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-02-21 20:29:08,073 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:29:39,667 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.26 sec
2019-02-21 20:30:11,235 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 3.96 sec
2019-02-21 20:30:16,627 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 5.47 sec
2019-02-21 20:30:20,761 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.16 sec
MapReduce Total cumulative CPU time: 7 seconds 160 msec
Ended Job = job_1550060164760_0023
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 7.16 sec HDFS Read: 19078 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 160 msec
OK
empno ename job mgr hiredate sal comm deptno
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
Time taken: 184.504 seconds, Fetched: 14 row(s)这样执行的结果会合并在一起,无法看出实际的效果,我们需要将结果分别保存到本地文件,然后再进行查看:
hive (default)> insert overwrite local directory '/opt/datas/sortby-res' select * from emp sort by empno asc ;
Query ID = hive_20190221203131_224d32ff-30ab-45c3-b3b5-5440a1b86fab
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550060164760_0024, Tracking URL = http://node1:8088/proxy/application_1550060164760_0024/
Kill Command = /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1550060164760_0024
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-02-21 20:31:26,915 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:31:38,848 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.73 sec
2019-02-21 20:32:07,147 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 3.6 sec
2019-02-21 20:32:13,408 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 5.11 sec
2019-02-21 20:32:44,309 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.61 sec
MapReduce Total cumulative CPU time: 6 seconds 610 msec
Ended Job = job_1550060164760_0024
Copying data to local directory /opt/datas/sortby-res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 6.61 sec HDFS Read: 18103 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 610 msec
OK
empno ename job mgr hiredate sal comm deptno
Time taken: 105.523 seconds查看执行结果文件如下:
[root@node3 ~]# cd /opt/datas/sortby-res/
[root@node3 sortby-res]# ls
000000_0 000001_1 000002_0
[root@node3 sortby-res]# cat 000000_0
7654•MARTIN•SALESMAN•7698•1981-9-28•1250.0•1400.0•30
7698•BLAKE•MANAGER•7839•1981-5-1•2850.0•N•30
7782•CLARK•MANAGER•7839•1981-6-9•2450.0•N•10
7788•SCOTT•ANALYST•7566•1987-4-19•3000.0•N•20
7839•KING•PRESIDENT•N•1981-11-17•5000.0•N•10
7844•TURNER•SALESMAN•7698•1981-9-8•1500.0•0.0•30
[root@node3 sortby-res]# cat 000001_1
7499•ALLEN•SALESMAN•7698•1981-2-20•1600.0•300.0•30
7521•WARD•SALESMAN•7698•1981-2-22•1250.0•500.0•30
7566•JONES•MANAGER•7839•1981-4-2•2975.0•N•20
7876•ADAMS•CLERK•7788•1987-5-23•1100.0•N•20
7900•JAMES•CLERK•7698•1981-12-3•950.0•N•30
7934•MILLER•CLERK•7782•1982-1-23•1300.0•N•10
[root@node3 sortby-res]# cat 000002_0
7369•SMITH•CLERK•7902•1980-12-17•800.0•N•20
7902•FORD•ANALYST•7566•1981-12-3•3000.0•N•20可以看到每个输出结果的文件中的数据都是按empno进行排好序的。
3.distribute by
这种查询方法类似于MapReduce中的partition的功能,对数据进行分区,一般和sort by结合进行使用。 以员工表为例,按照部门进行排序的查询语句写法如下: insert overwrite local directory '/opt/datas/distby-res' select * from emp distribute by deptno sort by empno asc ; 执行结果如下:
hive (default)> insert overwrite local directory '/opt/datas/distby-res' select * from emp distribute by deptno sort by empno asc ;
Query ID = hive_20190221204141_742ff907-7e3f-4eba-805d-303a8862a023
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550060164760_0025, Tracking URL = http://node1:8088/proxy/application_1550060164760_0025/
Kill Command = /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1550060164760_0025
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-02-21 20:42:07,058 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:43:07,112 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:44:08,142 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:44:49,353 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 62.1 sec
2019-02-21 20:45:06,145 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 64.45 sec
2019-02-21 20:45:11,330 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 65.81 sec
2019-02-21 20:45:14,477 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 67.79 sec
MapReduce Total cumulative CPU time: 1 minutes 7 seconds 790 msec
Ended Job = job_1550060164760_0025
Copying data to local directory /opt/datas/distby-res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 67.79 sec HDFS Read: 18143 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 7 seconds 790 msec
OK
empno ename job mgr hiredate sal comm deptno
Time taken: 207.675 seconds注意,distribute by必须要在sort by之前,原因是要先进行分区,然后才能进行排序。
[root@node3 datas]# cd distby-res/
[root@node3 distby-res]# ls
000000_0 000001_0 000002_0
[root@node3 distby-res]# cat 000000_0
7499•ALLEN•SALESMAN•7698•1981-2-20•1600.0•300.0•30
7521•WARD•SALESMAN•7698•1981-2-22•1250.0•500.0•30
7654•MARTIN•SALESMAN•7698•1981-9-28•1250.0•1400.0•30
7698•BLAKE•MANAGER•7839•1981-5-1•2850.0•N•30
7844•TURNER•SALESMAN•7698•1981-9-8•1500.0•0.0•30
7900•JAMES•CLERK•7698•1981-12-3•950.0•N•30
[root@node3 distby-res]# cat 000001_0
7782•CLARK•MANAGER•7839•1981-6-9•2450.0•N•10
7839•KING•PRESIDENT•N•1981-11-17•5000.0•N•10
7934•MILLER•CLERK•7782•1982-1-23•1300.0•N•10
[root@node3 distby-res]# cat 000002_0
7369•SMITH•CLERK•7902•1980-12-17•800.0•N•20
7566•JONES•MANAGER•7839•1981-4-2•2975.0•N•20
7788•SCOTT•ANALYST•7566•1987-4-19•3000.0•N•20
7876•ADAMS•CLERK•7788•1987-5-23•1100.0•N•20
7902•FORD•ANALYST•7566•1981-12-3•3000.0•N•20emp表最后一个字段是部门编号,由上面的结果可以看出,第一个文件的部门编号是30,第二个文件的部门编号是10,第三个部门编号是20。然后每个部门的员工数据都是按照员工编号进行升序排列的。
4.cluster by
cluster by是sort by和distribute by的组合,当sort by和distribute by的字段相同的时候,可以使用cluster by替代。参考查询语句如下: insert overwrite local directory '/opt/datas/clustby-res' select * from emp cluster by empno ; 执行结果如下:
hive (default)> insert overwrite local directory '/opt/datas/clustby-res' select * from emp cluster by empno ;
Query ID = hive_20190221205353_4485604f-078a-4813-85f0-4bea3c179c7a
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550060164760_0026, Tracking URL = http://node1:8088/proxy/application_1550060164760_0026/
Kill Command = /opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1550060164760_0026
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-02-21 20:54:14,963 Stage-1 map = 0%, reduce = 0%
2019-02-21 20:55:09,305 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.07 sec
2019-02-21 20:55:18,219 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 7.8 sec
2019-02-21 20:55:23,513 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 9.42 sec
2019-02-21 20:55:26,840 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.02 sec
MapReduce Total cumulative CPU time: 11 seconds 20 msec
Ended Job = job_1550060164760_0026
Copying data to local directory /opt/datas/clustby-res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 11.02 sec HDFS Read: 18146 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 20 msec
OK
empno ename job mgr hiredate sal comm deptno
Time taken: 95.212 seconds注意,cluster by 后面不能指定desc或者asc,否则会报错。
[root@node3 datas]# cd clustby-res/
[root@node3 clustby-res]# ls
000000_0 000001_0 000002_0
[root@node3 clustby-res]# cat 000000_0
7521•WARD•SALESMAN•7698•1981-2-22•1250.0•500.0•30
7566•JONES•MANAGER•7839•1981-4-2•2975.0•N•20
7698•BLAKE•MANAGER•7839•1981-5-1•2850.0•N•30
7782•CLARK•MANAGER•7839•1981-6-9•2450.0•N•10
7788•SCOTT•ANALYST•7566•1987-4-19•3000.0•N•20
7839•KING•PRESIDENT•N•1981-11-17•5000.0•N•10
7902•FORD•ANALYST•7566•1981-12-3•3000.0•N•20
[root@node3 clustby-res]# cat 000001_0
7369•SMITH•CLERK•7902•1980-12-17•800.0•N•20
7654•MARTIN•SALESMAN•7698•1981-9-28•1250.0•1400.0•30
7876•ADAMS•CLERK•7788•1987-5-23•1100.0•N•20
7900•JAMES•CLERK•7698•1981-12-3•950.0•N•30
[root@node3 clustby-res]# cat 000002_0
7499•ALLEN•SALESMAN•7698•1981-2-20•1600.0•300.0•30
7844•TURNER•SALESMAN•7698•1981-9-8•1500.0•0.0•30
7934•MILLER•CLERK•7782•1982-1-23•1300.0•N•10四种排序的区别如下:















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









