







对一个软件/服务的配置有多么痛苦的回忆,在事后把它的过程记录下来的欲望既有多么强烈。
这次的主题是Ganglia,是一个由UCBerkeley主导开发的服务器集群监测平台。由于研究室今年新进了一台8GPU服务器的服务器,老板提出“想要在ganglia上实时看到gpu资源运行情况”的需求。本以为是个小工作,想不到最后配置下来,居然花了我整整一天的时间。主要的原因还是在于网上乃至于官方的配置教程实在是太潦草了,对于我这原本对ganglia一无所知的人儿来说简直是充满敌意。
所以这篇note,或者厚着脸皮说是教程的东西,会尽可能地简单、简单、简单...
需求
在ganglia的前端网页上,显示出某个节点的gpu资源监测框图。要求可以看到每一块gpu的负载、显存占用、温度等信息。
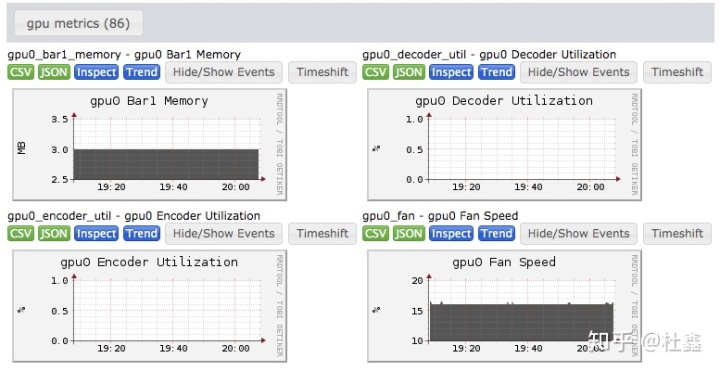
上图是配置完成后的一个例子。“86”指的是最后这台机器上关于gpu资源的监测项目包含86项。这几乎是关于gpu所有能够实时获取的内容了,根据需要当然也可以只显示其中的一部分。等会会提到其中的原理。
服务器集群的原始状态
- 在服务器集群上原本已经搭建好了ganglia服务,能够实时监测服务器的cpu、内存等信息。
- 集群中包括一台机器 (host) 用于整合整个集群的数据,并发布到前端网页;以及若干台配备了数块gpu的设备 (client)。
- host 机器 (debian系统) 上安装了 ganglia 的 gmetad 服务。这次要连入集群中的新服务器 client-A 尚未安装 ganglia 相关的任何程序。
关于 ganglia 的基本原理
Ganglia 这个项目主要可分为以下几个部分:(参照几乎没有任何有用信息的官方文档)

其中 gmetad 用于整合整个集群上所有服务器传过来的信息,然后将数据发布到前端网页。整个集群中需要(至少)一台机器安装并启动了该服务。检测其是否正常运作可通过输入
>> systemctl status gmetad
gmond 是每一台被监测的机器上都需要安装的程序。它会收集这台机器上的信息,定时发送给集群中启动了 gmetad 服务的计算机。在 debian / ubuntu 上 gmond 的名字叫 ganglia-monitor,它的安装过程很简单:
>> sudo apt-get install ganglia-monitor安装后程序会自动启动。正常来说,这时候你的 ganglia 网页上会多出一个对应的框图了。
至于 gmetric, gstat, web 这三个部分,我们这次就不去探究了。
gpu 资源的监测
要监测 nvidia gpu 的资源使用情况,nvidia 官方提供的解决方案是,利用 cuda + pynvml 来获取信息,并交给 gmond 进行汇总。
- cuda 大家应该都知道,是驱动 nvidia GPU 完成科学计算任务的必备库。在计算机上安装 cuda 完毕后,输入
>> nvcc -V如果出现 nvcc 的版本号,就说明 cuda 已经安装成功了。此时,继续输入
>> nvidia-smi应该会出现各个 gpu 的使用信息:
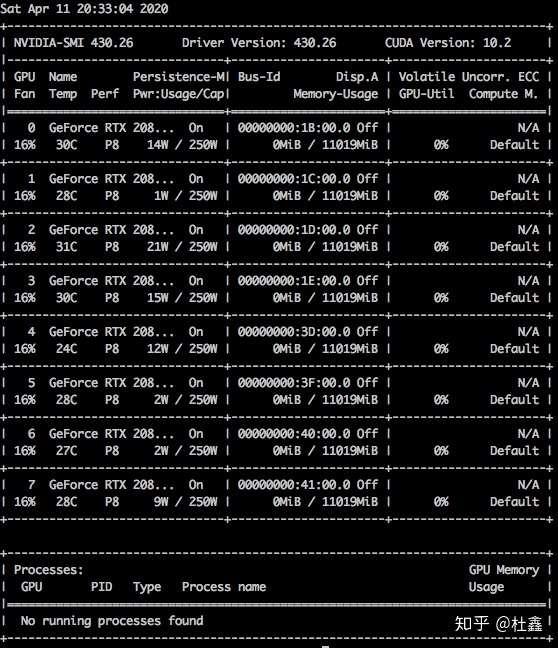
- pynvml 是 python 的一个包,它可以用来获取 gpu 的各项数据。这些数据本质上也就是 nvidia-smi 这个命令返回的那些数据了,只不过用 python 打包之后能更便于处理。
所以这里的思路很明显:用 python 写一个脚本,在脚本里用 pynvml 连接 cuda,通过 cuda 获取 gpu 的实时数据,然后传给这个机器上的 gmond 服务。最后 gmond 服务再将信息传给另一台服务器上的 gmetad 服务,完成发布。
好在,这个 python 脚本不需要我们自己写,在 github 上可以找到:
gpu 监测脚本github.com配置过程
下面进入正题。
Step 1: 登陆需要监测 gpu 的服务器(我这里称为 client-A 服务器),获取管理员权限。
>> sudo -iStep 2: 通过 pip 安装 nvidia-ml-py 库(也就是上面提到的 pynvml 库)
>> python -m pip install -U pip
>> pip install nvidia-ml-py这里可能会遇到两个问题:
- 没有登陆为 sudoer。可能导致的问题是,你并没有为系统自带的 python 版本安装这个包,而是为你自己平时用的 python 版本安装 nvidia-ml-py。比如系统自带的 python 是 2.7 版本,而我自己用的是 python 3.6 版本,在我使用上述命令后,3.6版本安装成功但2.7版本依旧没有安装。结果是,ganglia 调用 nvidia-ml-py 失败,且错误信息你是看不到的。
- 系统自带的 python 版本 (2.7) 甚至没有配备 pip 工具。解决的方法有两条:
- 先安装 pip,再通过 pip 安装 nvidia-ml-py。
- 直接从 python 源代码安装,下载地址在这里。
安装方法是python setup.py install
Step 3: 下载前文所属的 python 脚本(它调用 nvidia-ml-py / pynvml 获取 gpu 信息)
这个github项目包含了很多 ganglia 可以调用的 python 脚本,但我们这里只用其中的 gpu/nvidia 这里文件夹里面的东西:
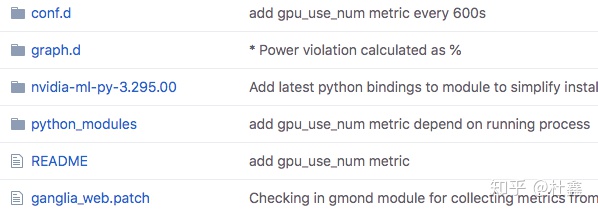
- conf.d: 配置文件,放在 client-A 服务器上。
- python_modules: python 脚本,放在 client-A 服务器上。
- graph.d: 网页前端的配置文件,放在 host 服务器上。
- nvidia-ml-py-3.295.00: 就是前面 Step 2 里面我提到的这个库的源文件,如果已经 pip 安装过了,可以忽略它。
- ganglia_web.patch: 不用理它,现在版本已经不需要它了。
Step 4: 把 Step 3 里面的文件放到正确的位置。以 ubuntu 16/18 为例:
首先,进入 client-A 服务器:
>> git clone https://github.com/ganglia/gmond_python_modules.git
>> cd gmond_python_modules/gpu/nvidia
>> cp conf.d/nvidia.conf /etc/ganglia/conf.d/
>> cat <<EOF | sudo tee /etc/ganglia/conf.d/modpython.conf
modules {
module {
name = "python_module"
path = "/usr/lib/ganglia/modpython.so"
params = "/usr/lib/ganglia/python_modules/"
}
}
include ('/etc/ganglia/conf.d/*.pyconf')
EOF
>> cp python_modules/nvidia.py /usr/lib/ganglia/python_modules/其中,/etc/ganglia/conf.d/ 文件夹和 /usr/lib/ganglia/python_modules/ 文件夹可能不存在,创建一下即可。cat <<... 这句是为了在 /etc/ganglia/conf.d 里写入一个 modpython.conf 文件,因为 ganglia 在未配置时只能识别后缀为 .conf 的文件,有了这个 modpython.conf 后,就会识别 .pyconf 文件了。
这时候,可以检验一下 pynvml 是否安装成功:
>> python /usr/lib/ganglia/python_modules/nvidia.py顺利的话,这个命令会打印出一些 gpu 的相关信息;否则,可能会提示 pynvml 未安装等错误。需要注意的是,由于 gpu 的型号,pynvml 的版本不同,部分信息会无法打印出来,但不表示安装出现问题。
然后,进入 host 服务器:
>> git clone https://github.com/ganglia/gmond_python_modules.git
>> cd gmond_python_modules/gpu/nvidia
>> cp graph.d/* /usr/share/ganglia-webfrontend/graph.d/Step 5: 最后,重启 host 服务器上的 gmetad 服务,以及 client-A 服务器上的 gmond 服务:
host 上:
>> sudo /etc/init.d/gmetad restartclient-A 上:
>> sudo /etc/init.d/ganglia-monitor restart多刷新几遍,再访问 ganglia 的网页,进入 client-A 对应的节点,应该就能看到多了一个 gpu metrics 了。
Trouble shooting
如果在配置过程中出现问题,大家首先确认一下几点:
- 在安装 gpu 监测服务之前,ganglia 的网页是否可以正常显示各节点。如果不能显示,可能是 gmetad / gmond 未启动,或者是集群内的通信出了问题(比如 DNS 解析不正确)。
- cuda 是否已经安装。
nvidia-smi可以正常返回信息,则安装成功。 - 在各个 client 服务器上,nvidia-ml-py (也叫 pynvml) 是否已经正确安装。如果正确安装,那么 Step 4 中执行 nvidia.py 应该会出现 gpu 信息。
- 在各个 client 服务器上,/etc/ganglia/conf.d/ 目录下是否已经放入
nvidia.conf和modpython.conf文件。 - 在 host 服务器上,是否已经将 graph.d/ 目录下的文件复制到 /usr/share/ganglia-webfrontend/graph.d/ 下面。
如果还有问题存在,那大概率我也无能为力了 :(。
关于 python 脚本的调用过程,以及对它的修改
(根据我的猜想) /usr/lib/ganglia/python_modules/nvidia.py 这个脚本首先会被 gmond 服务调用,它的结构仔细一看其实很简单,所有信息会被以字符串的形式 print 出来。
随后 gmond 按照 /etc/ganglia/conf.d/nvidia.pyconf 里面定义的过滤格式,从 print 的标准输出中使用正则表达式截取各项数据。下面是 nvidia.pyconf 的一部分:
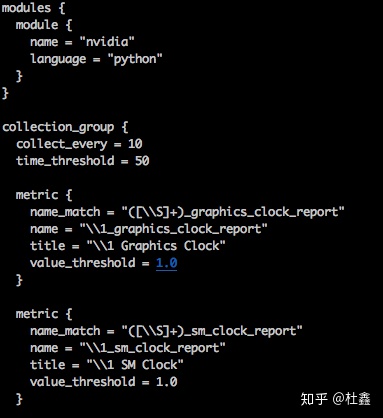
可以看出,每一个 metric 最后就会在 ganglia 的网页端形成一个窗口。例如图中第一个 metric 中描述的就是对 graphics_clock_report 这项数据的匹配过程。
所以如果想要在 ganglia 中只显示部分 metric,或者对多项 metric 数据进行整理和集成的话,只需要在 nvidia.py 中进行修改就好。
相信大家的 python 水平足够应付这个 nvidia.py 文件了:)。
这篇文章也是久违的一次投稿,去年花了很多精力写的一篇论文被接受,最近心情很好。也由衷希望这篇 blog 能给焦头烂额的你带来一点点好心情。















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









