







sklearn逻辑回归
logistics回归名字虽然叫回归,但实际是用回归方法解决分类的问题,其形式简洁明了,训练的模型参数还有实际的解释意义,因此在机器学习中非常常见。
理论部分
设数据集有n个独立的特征x,与线性回归的思路一样,先得出一个回归多项式:
\[y(x) = w_0+w_1x_1+w_2x_2+…+w_nx_n
\]
但这个函数的值域是\([-\infty,+\infty]\),如果使用符号函数进行分类的话曲线又存在不连续的问题。这个时候,就要有请我们的sigmoid函数登场了,其定义如下:
\[f(x)=\frac{1}{1+e^{-x}}
\]
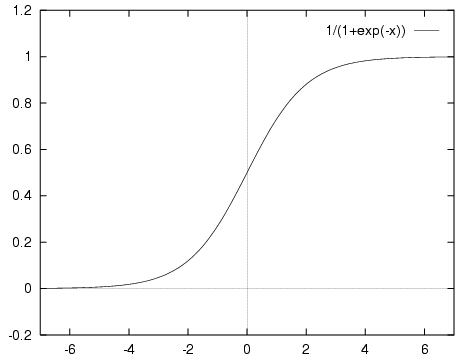
这个函数属于\([0,1]\),而且连续可导,如果把纵坐标看成概率,那么就可以根据某个对象属于某一类的概率来进行分类了。
顺着这样的思路,我们定义几率比(odds ratio):
\[y(x)=ln(\frac{p(x)}{1-p(x)})
\]
这里\(p(x)\)表示该属性组合x属于第一类(正类)的概率,对应的\(1-p(x)\)表示该属性组合x属于第二类(反类)的概率。可以解得:
\[p(x)=\frac{1}{1+e^{-(w_0+w_1x_1+w_2x_2+…+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









